2 Modelo de regresión múltiple
Objetivos del capítulo
El lector, al finalizar este capítulo, estará en capacidad de:
- Explicar en sus propias palabras cuáles son los supuestos del Teorema de Gauss-Markov
- Explicar en sus propias palabras cuáles son las propiedades de lo estimadores MCO
- Estimar un modelo lineal con más de una variable explicativa empleando R .
- Identificar los coeficientes estimados por R.
- Transformar y crear variables en R.
- Interpretar los componentes de las tablas de salida que proporciona R.
2.1 Introducción
El científico de datos pocas veces se enfrenta con un problema bien definido en el que la teoría pueda aplicarse directamente, ya sea por la disponibilidad de información para construir determinada variable o porque el problema no se encuentra acotado. Así, típicamente el científico de datos se encuentra enfrentado a un problema en el que la variable a explicar (variable dependiente) es clara y existe un conjunto amplio de posibles variables explicativas. Antes de enfrentar ese problema un poco más complicado, supongamos que contamos con un número reducido de variables explicativas.
Por ejemplo, supongamos que queremos responder la pregunta de negocio: ¿de qué dependen las cantidades compradas de mi producto estrella \(Q\)? Y supongamos además que se cuenta con una base de datos con las siguientes posibles variables explicativas: el precio del producto estrella \(p_x\), el precio de un producto idéntico de la competencia que puede sustituir nuestro producto \(p_{sust}\), el precio de un precio de un producto que acompaña (o complementa) el consumo de nuestro producto \(p_{comp}\) y el nivel de actividad económica que puede ser una variable que aproxime el ingreso que tienen los consumidores para comprar mi producto \(I\). Así, la tarea del científico de datos será construir un modelo que cumpla la tarea de regresión que le permita hacer analítica diagnóstica . Estas variables disponibles podrían permitir inicialmente emplear un modelo que permita representar las cantidades compradas en función de las variables explicativas disponibles. En otras palabras: \[\begin{equation} Q = Q_x \left( p_x ,p_{comp} ,p_{sust} ,I \right) \tag{2.1} \end{equation}\]
Naturalmente, no hay nada que permita saber a priori (antes de usar los datos) si realmente son todas estas 4 variables importantes para explicar a \(Q\). En el Capítulo 3 se discutirá cómo determinar con los datos cuáles variables afectan y cuáles no a la variable dependiente.
Por otro lado, es importante determinar la forma de la función \(Q_x()\). Por ejemplo, la forma funcional puede ser: \[\begin{equation} Q_x\left( p_x,p_{comp},p_{sust},I \right) = \gamma p_x^{\alpha_0} + \frac{1}{{p_{comp}{^\beta} + C}} + \ln \left( \varphi p_{sust} \right) + \alpha_0 I \tag{2.2} \end{equation}\] o
\[\begin{equation} {Q_x}\left( p_x,p_{comp},p_{sust},I \right)= \beta_0 + \beta_1 p_x + \beta_2 p_{comp} + \beta_3 p_{sust} + \beta_4 I \tag{2.3} \end{equation}\]
Aún más, el carácter de las relaciones funcionales expresadas en (2.2) y (2.3) es determinístico14. Estas dos expresiones corresponden a modelos matemáticos (exactos) y no estadísticos.
En la práctica se reconoce que las relaciones entre la variables independientes y la dependiente no tienen por qué ser exactas y se incluye un término aleatorio de error en los modelos a estimar15. La inclusión de este término de error se justifica de diferentes formas. Por ejemplo16:
- Las respuestas humanas individuales a diferentes incentivos no son exactas y, por tanto, no son predecibles con total certidumbre; aunque se espera que en promedio sí lo sean.
- En general, es imposible pretender que un modelo recoja todas y cada una de las variables que afectan directamente una variable, pues precisamente un modelo económico es una simplificación de la realidad y, por tanto, omite detalles de ella. Es importante anotar que en algunas ocasiones las variables que se omiten son conocidas, pero el investigador no cuenta con información para medir esas variables, por tanto deben ser omitidas.
- La variable dependiente puede estar medida con error, pues en la práctica los agregados económicos normalmente son estimados a partir de muestras. El error de medición en la variable dependiente estará recogido en el término de error, pues nuestro modelo no pretenderá explicar el error de medición sino el comportamiento promedio del agregado económico.
- En algunas oportunidades las relaciones entre variables enunciadas por la teoría económica son producto de un esfuerzo de resumir un conjunto de decisiones individuales. Así como las decisiones individuales son diferentes de individuo a individuo, cualquier intento por estimar estas relaciones a nivel agregado será simplemente una aproximación; por tanto la diferencia entre esta aproximación y el valor real será atribuida al término de error.
Entonces, todo modelo econométrico poseerá una parte aleatoria y una que no lo es (parte determinística). Por ejemplo, si se considera la relación funcional expresada en la ecuación (2.1), el correspondiente modelo estadístico corresponderá a \(Q = Q_x\left({p_x ,p_{comp} ,p_{sust} ,I} \right) + \varepsilon\), donde \(Q_x \left( {p_x ,p_{comp} ,p_{sust} ,I} \right)\) corresponde a la porción determinística del modelo y \(\varepsilon\) representa el término aleatorio de error.
En la práctica, los científicos de datos adoptan como estrategia tomar una primera aproximación a las relaciones funcionales por medio de relaciones lineales (como en la expresión (2.3) o linealizables. En este libro concentraremos nuestra atención en los modelos lineales. Es decir, modelos de la siguiente forma: \[\begin{equation} Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \varepsilon _i . \tag{2.4} \end{equation}\]
En este modelo podemos distinguir varios componentes: la variable dependiente (\({Y_i}\)), las variables independientes (\(X_{1i}\) y \(X_{2i}\)), los coeficientes o parámetros17 (\(\beta_0\), \(\beta_1\) y \(\beta_2\)), y el término de error (\(\varepsilon_i\)). Adicionalmente, se presenta un subíndice \(i\) que representa que dicha relación se cumple para cualquier observación \(i\) que se realice. Típicamente \(i\) se encuentra entre 1 y \(n\) (el tamaño de la muestra); es decir, \(i = 1,2, \ldots ,n\). Es importante anotar que normalmente cuando se emplean datos de series de tiempo, el subíndice \(i\) es cambiado por una \(t\). En otras palabras, típicamente se emplea el subíndice \(i\) cuando se cuenta con datos de corte trasversal, dado que \(i\) representa a los individuos que están bajo estudio en un período determinado. Y cuando se emplean series de tiempo, el subíndice que se emplea es \(t\) que representa el período (el tiempo) de la observación.
Antes de entrar en detalle, es importante aclarar qué se entiende por modelo lineal en este contexto. Para ser más precisos, cuando nos referimos a un modelo de regresión lineal, estamos hablando de un modelo que es lineal en sus parámetros y el término de error es aditivo. En otras palabras, los parámetros18 están multiplicando a las variables explicativas o representan un intercepto. Formalmente, un modelo se considera un modelo lineal si la variable dependiente se puede expresar como una combinación lineal de las variables explicativas y un término de error, donde los parámetros son los coeficientes de la combinación lineal19.
Por ejemplo, el modelo: \[\begin{equation} Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \varepsilon_i \tag{2.5} \end{equation}\] es un modelo (estadístico) lineal, pues es lineal en los parámetros \(\beta ^T = \left( {\beta_0 ,\beta_1 ,\beta_2 } \right)\); en este caso, estos representan un intercepto y pendientes (Ver ejemplo en la sección 2.1.1), y el término de error es aditivo. Por otro lado, un modelo como \[\begin{equation} Y_i = \beta_0 + \left( {X_{1i} } \right)^{\beta_1 } + \beta_2 X_{2i} + \varepsilon_i \tag{2.6} \end{equation}\] no es un modelo lineal, pues el modelo no es lineal respecto a \(\beta_1\), el cual representa una potencia.
Ahora bien, es importante resaltar que un modelo econométrico puede ser lineal en los parámetros y tener un término aleatorio aditivo, pero no representar una línea recta, un plano o sus equivalentes en dimensiones mayores. En estos casos, aunque no se trata de un modelo lineal desde el punto de vista matemático, aún tenemos un modelo estadístico lineal (Ver sección 2.1.2).
Existen otros modelos especiales que no son lineales en sus parámetros, pero mediante reparametrizaciones20 se convierten en modelos lineales. Estos se conocen con el nombre de modelos linealizables (o modelos intrínsecamente lineales) y también pueden ser estimados por los mismos métodos de estimación de un modelo lineal.
2.1.1 Ejemplo: Modelo (matemáticamente) lineal
Supongamos la siguiente relación entre una variable dependiente (\(Y_i\)) y dos variables explicativas (\(X_{1i} ,X_{2i}\)): \[\begin{equation} Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \varepsilon _i, \tag{2.7} \end{equation}\] donde \(\varepsilon_i\) es un término aleatorio de error. Entendamos primero la naturaleza de esta relación funcional omitiendo el término aleatorio de error. En la Figura 2.1 se puede observar la función \(Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2\) con \(\beta_0 =-3\), \(\beta_1 =2\) y \(\beta_2 =4\).
Figura 2.1: Parte no estocástica del modelo lineal con \(\beta_0 =-3\), \(\beta_1 =2\) y \(\beta_2 =4\)
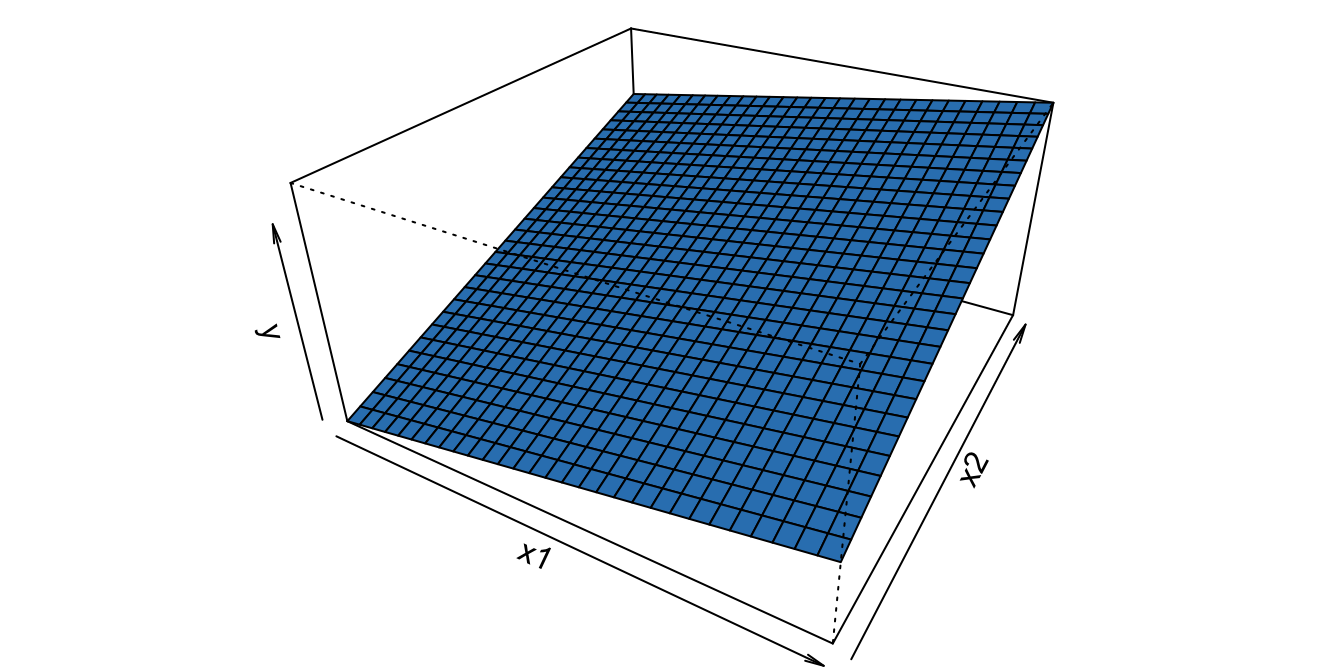
Nota que \(\frac{{\partial Y}}{{\partial X_1 }} = \beta_1\); es decir, el coeficiente asociado a la variable independiente \(X_1\) corresponden al cambio en la variable dependiente cuando la otra variable independiente se mantiene constante. En otras palabras, \(\beta_1\) es la pendiente de la función con respecto al plano formado por los ejes de \(X_1\) y \(Y\). Esto lo podemos ver más claramente si rotamos un poco los ejes (Ver Figura 2.2).
Figura 2.2: Parte no estocástica del modelo lineal con \(\beta_0 =-3\), \(\beta_1 =2\) y \(\beta_2 =4\) con ejes rotados.
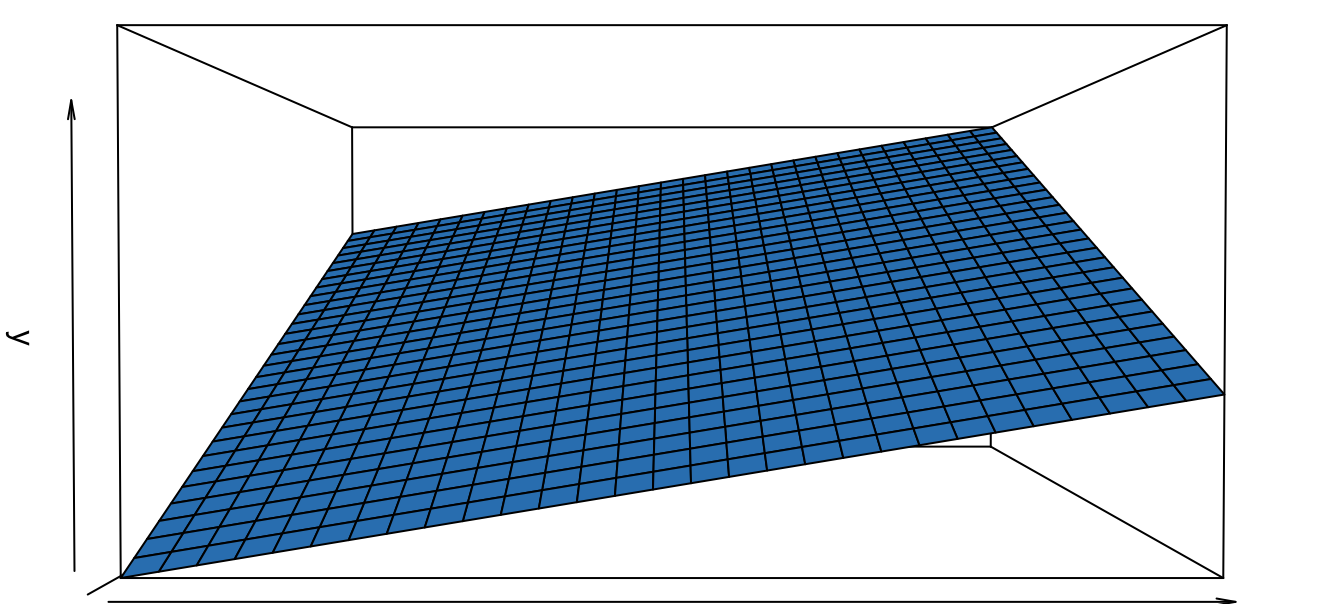
Similarmente, \(\beta_2\) representa el cambio en la variable dependiente cuando la variable \(X_2\) cambia en una unidad dejando \(X_1\) constante (\(\beta_2 = \frac{{\partial Y_i }}{{\partial X_{2i} }}\)).
2.1.2 Ejemplo: Modelo intrínsecamente lineal
Suponga la siguiente relación entre una variable dependiente (\(Y_i\)) y dos variables explicativas(\(X_{1i} ,X_{2i}\)): \[\begin{equation} Y_i = \alpha_1 + \alpha_2 \ln \left( {X_{1i} } \right) + \alpha_3 \left( {\frac{1}{{X_{2i} }}} \right) + \varepsilon_i , \tag{2.8} \end{equation}\] donde \(\varepsilon_i\) es un término aleatorio de error. En este caso, tenemos que el modelo es lineal en los parámetros \(\alpha_1\), \(\alpha_2\) y \(\alpha_3\), además el error es aditivo; por tanto este modelo es estadísticamente lineal.
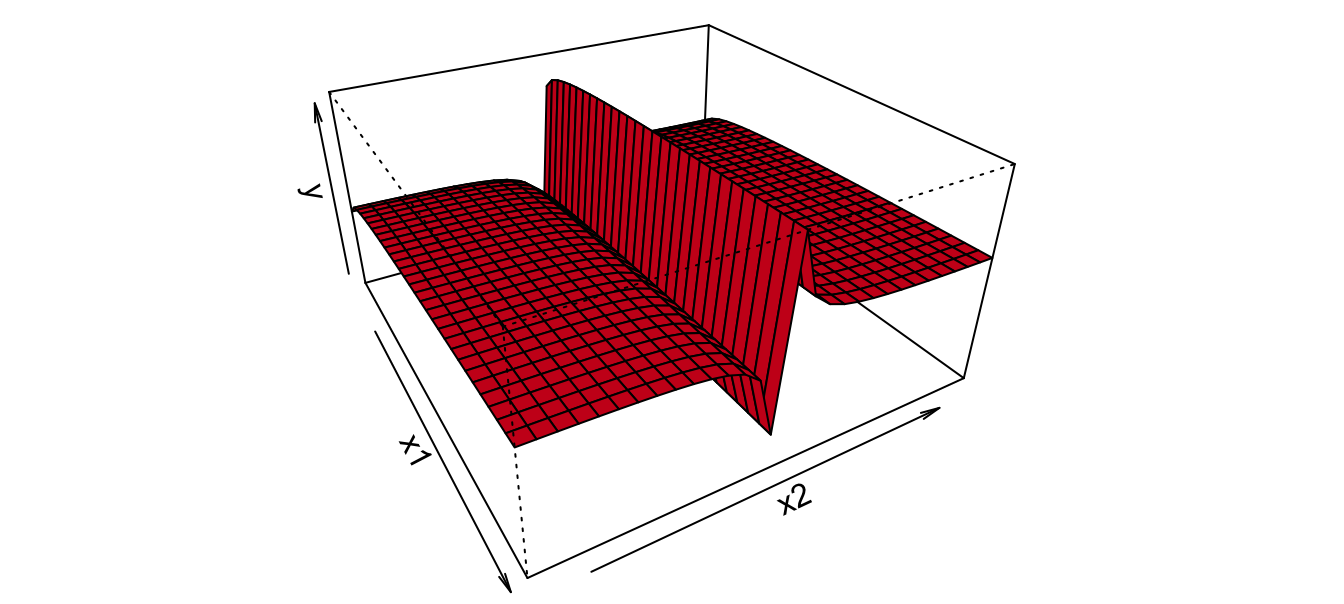
No obstante, el modelo no representa un plano (no es lineal desde el punto de vista matemático), como se puede observar en la Figura 2.3 (en la cual se ha omitido el término de error). Es importante anotar que en este caso \(\alpha_2\) no es una pendiente, pues \(\frac{{\partial Y}}{{\partial X_1 }} = \frac{{ \alpha_2 }}{{X_1 }}\); para \(\alpha_3\) ocurre algo similar.
Figura 2.3: Parte no estocástica del modelo con \(\alpha_1 =1\), \(\alpha_2 =2\) y \(\alpha_3 =4\).
Pero esta función se puede expresar de tal forma que represente un plano; reparametrizando, podemos definir \({W_{1i}} = \ln \left( {{X_{1i}}} \right)\) y \({W_{2i}} = \left( {\frac{1}{{{X_{2i}}}}} \right)\). Ahora, remplazando estas dos nuevas variables en el modelo original, tenemos que \({Y_i} = { \alpha_1} + { \alpha_2}{W_{1i}} + { \alpha_3}{W_{2i}} + {\varepsilon _i}\). La Figura 2.4 muestra esta nueva función, ignorando el término de error, en el espacio \(\left( {Y,{W_1},{W_2}} \right)\).
Figura 2.4: Parte no estocástica del modelo reparametrizado y con \(\alpha_1 =1\), \(\alpha_2 =2\) y \(\alpha_3 =4\).
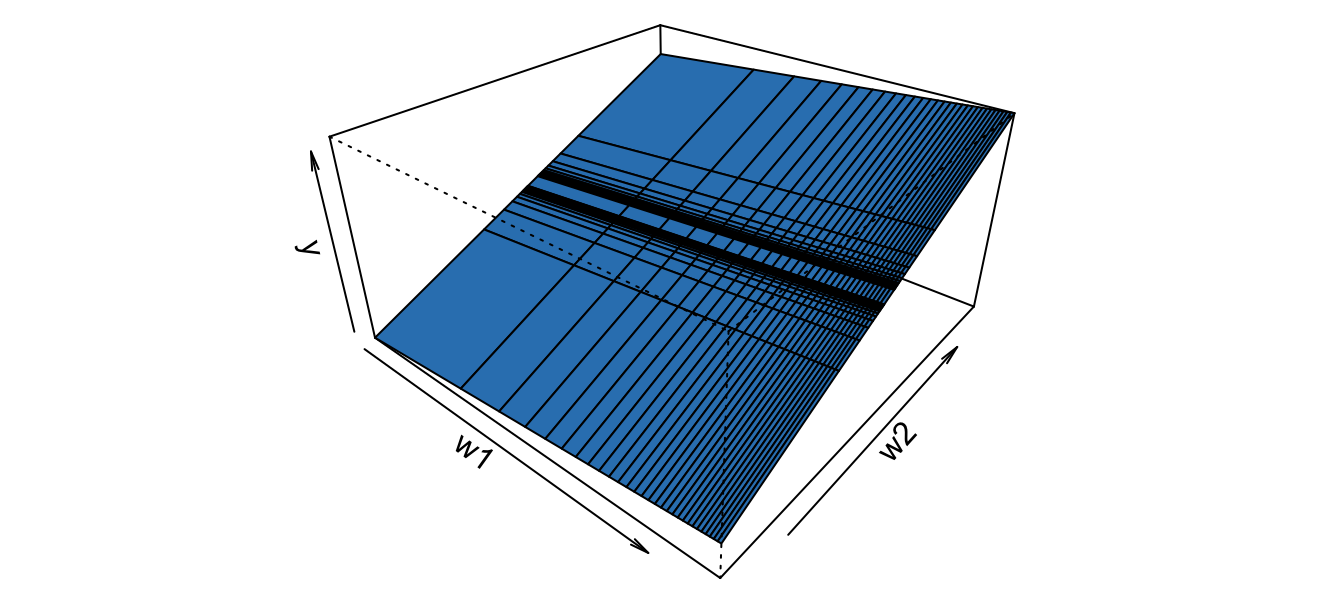
Este modelo reparametrizado es un modelo matemáticamente lineal, representa un plano. Noten que el modelo (2.8) si es lineal desde el punto de vista estadístico y se puede estimar por medio de los métodos que estudiaremos en este capítulo.
Es importante anotar que la interpretación de los parámetros \({\alpha_1}\) y \({\alpha_2}\) es un poco diferente en este caso. Por ejemplo, \({\alpha_2}\) representa el número de unidades en que cambiará la variable dependiente cuando \({W_1}\) cambia en una unidad. Es decir ,cuando el \(\ln \left( {{X_1}} \right)\) cambia en una unidad y no cuando \({X_1}\) cambia. Para interpretar \(\alpha_2\) en términos de \(X_1\) es necesario derivar (2.8) con respecto a \(X_1\): \(\frac{{\partial Y_i }}{{\partial X_{1i} }} = \frac{{ \alpha_2 }}{{X_{1i} }}\). Manipulando algebráicamente tenemos \(\frac{{\partial Y_i }}{{\frac{{\partial X_{1i} }}{{X_{1i} }}}} = \alpha_2\). Multiplicando a ambos lados por \(\frac{1}{{100}}\), obtenemos \(\frac{{\partial Y_i }}{{\frac{{\partial X_{1i} }}{{X_{1i} }} \times 100}} = \frac{{ \alpha_2 }}{{100}}\). Es decir, \(\frac{{\partial Y_i }}{{\Delta \% X_{1i} }} = \frac{{ \alpha_2 }}{{100}}\). Por tanto, la interpretación de \(\alpha_2\) en términos de \(X_1\) es la siguiente: cuando \(X_1\) aumenta en uno por ciento, entonces \(Y_i\) aumentará en \(\frac{{ \alpha_2 }}{{100}}\) unidades.
2.1.3 Ejemplo: Función de Cobb-Douglas
Una función Cobb-Douglas se define como: \[\begin{equation} Y = \alpha_0^{{ \alpha_1}}X_2^{{ \alpha_2}}X_3^{{ \alpha_3}} \tag{2.9} \end{equation}\] donde \(Y\) corresponde a la variable dependiente y \({ \alpha_j}\) para \(j=0,1,2,3\) son los parámetros a estimar.
Claramente, la expresión anterior no corresponde a un modelo estadístico, pues no presenta término aleatorio alguno. Como se discutió anteriormente, existen diferentes justificaciones para incluir un término estocástico de error. Así, un modelo econométrico a partir de la función Cobb-Douglas sería: \[\begin{equation} {Y_i} = \alpha_0 X_{1i}^{{ \alpha_1}}X_{2i}^{{ \alpha_2}}X_{3i}^{{ \alpha_3}}{\varepsilon _i} \tag{2.10} \end{equation}\] donde \(i = 1,2,...,n\) y \({\varepsilon _i}\) es un término aleatorio de error. Es decir, el modelo es válido para cualquiera de las \(i\) observaciones. Pero este modelo no es lineal al no ser lineal en los parámetros. No obstante, éste se puede linealizar fácilmente; aplicando logaritmos a ambos lados de la expresión tendremos: \[\begin{equation} \ln \left( {{Y_i}} \right) = \ln \left( \alpha_0 \right) + { \alpha_1}\ln \left( {{X_{1i}}} \right) + { \alpha_2}\ln \left( {{X_{2i}}} \right) + { \alpha_3}\ln \left( {{X_{3i}}} \right) + \ln \left( {{\varepsilon _i}} \right) \tag{2.11} \end{equation}\] Definamos \(\beta = \ln \left( \alpha_0 \right)\) y \({\mu _i} = \ln \left( {{\varepsilon _i}} \right)\). Entonces la expresión anterior se puede reescribir de la siguiente forma: \[\begin{equation} \ln \left( {{Y_i}} \right) = \beta + { \alpha_1}\ln \left( {{X_{1i}}} \right) + { \alpha_2}\ln \left( {{X_{2i}}} \right) + { \alpha_3}\ln \left( {{X_{3i}}} \right) + {\mu _i} \end{equation}\]
Un aspecto importante de este modelo es la interpretación singular de los coeficientes. En este caso, cada \({\alpha_j}\) (solo para \(j=1,2,3\)) corresponde a la elasticidad de la variable dependiente con respecto a la variable explicativa \(j\). Es decir el aumento porcentual en la variable dependiente dado un aumento en un 1% en la variable explicativa \(X_j\). Para una demostración de esta afirmación se puede ver los ejercicios al final de este capítulo.
En otras palabras, en general cuando contamos con un modelo lineal con todas las variables expresadas en logaritmos, entonces las pendientes corresponderán a las elasticidades (Ver el ejercicio en la sección 2.4.1 para una demostración).
Por otro lado, el intercepto \(\beta\) corresponde al valor esperado del logaritmo del valor de \(Y\) cuando todos las variables explicativas son iguales a una unidad. En otras palabras, \(\alpha_0 = {e^\beta}\). Así, el intercepto en este modelo tiene una interpretación difícil y en la mayoría de las aplicaciones carece de interpretación.
2.2 El modelo de regresión múltiple
Una vez se cuenta con un modelo lineal que representa la relación entre diferentes variables explicativas y la variable dependiente, se deseará conocer los valores de los parámetros del modelo. Para lograr este fin, se recopilan \(n\) observaciones de las variables explicativas y de la dependiente. En general, un modelo lineal múltiple para el cual se cuenta con \(n\) observaciones y \(k-1\) variables explicativas está dado por: \[\begin{equation} \begin{matrix} {y_1} = & {\beta_1} + {\beta_2}{X_{21}} + {\beta_3}{X_{31}} +\ldots+ {\beta_k}{X_{k1}} + & {\varepsilon _1}\\ {y_2} =& {\beta_1} + {\beta_2}{X_{22}} + {\beta_3}{X_{32}} +\ldots+ {\beta_k}{X_{k2}} + & \varepsilon _2 \\ \vdots& \vdots & \vdots \\ {y_n} = & {\beta_1} + {\beta_2}{X_{2n}} + {\beta_3}{X_{3n}} +\ldots+{\beta_k}{X_{kn}}+ & \varepsilon_n \end{matrix} \tag{2.12} \end{equation}\]
Para este tipo de modelos, los datos pueden corresponder a dos tipos de estructura. Una estructura en la que se observan \(n\) individuos en el mismo período. A esta estructura se le conoce como datos de corte trasversal y es equivalente a tomar una foto de los \(n\) individuos. La segunda estructura posible es una serie de tiempo, en la que se observa un individuo (objeto de estudio) periodo tras periodo. En este caso es común emplear el subíndice \(t\) para denotar cada periodo que va desde el primero hasta el \(T\). Para simplificar, en este libro siempre nos referiremos a \(n\) como el tamaño de la muestra, ya sea que empleemos datos de series de tiempo o corte transversal. Es decir, en este libro tendremos que \(n\) representará lo mismo que \(T\). Existe una tercera estructura de datos que combina las dos anteriores, muchos individuos que se siguen en el tiempo. Esta última estructura se conoce como datos de panel. Las técnicas que se presentan en este libro solo aplican para las dos primeras estructuras de datos, pero se pueden extrapolar fácilmente para la estimación de modelos con datos de panel.
Regresando a la notación, para simplificar y ahorrar espacio, escribiremos el modelo (2.12) de una forma más abreviada, de tal modo que sólo describamos la observación i-ésima del modelo. Es decir: \[\begin{equation} {y_i} = {\beta_1} + {\beta_2}{X_{2i}} + {\beta_3}{X_{3i}} + \ldots + {\beta_k}{X_{ki}} + {\varepsilon _i} \tag{2.13} \end{equation}\] para \(i = 1,2,...,n\).
Otra forma de expresar el mismo modelo (2.13) de manera aún más abreviada es empleando matrices. Sean:
\[\begin{equation*} {\bf{y}} = {\left[ {\begin{array}{*{20}{c}} {{y_1}} \\ {{y_2}} \\ \vdots \\ {{y_n}} \\ \end{array}} \right]_{n \times 1}}\beta = {\left[ {\begin{array}{*{20}{c}} {{\beta_1}} \\ {{\beta_2}} \\ \vdots \\ {{\beta_n}}\\ \end{array}} \right]_{k \times 1}}X = {\left[ {\begin{array}{*{20}{c}} 1 & {{X_{21}}} & {{X_{31}}} & \cdots & {{X_{k1}}} \\ 1 & {{X_{22}}} & {{X_{32}}} & \cdots & {{X_{k2}}} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 1 & {{X_{2n}}} & {{X_{3n}}} & \cdots & {{X_{kn}}} \\ \end{array}} \right]_{n \times k}}\varepsilon = {\left[ {\begin{array}{*{20}{c}} {{\varepsilon _1}} \\ {{\varepsilon _2}} \\ \vdots \\ {{\varepsilon _n}} \end{array}} \right]_{n \times 1}} \end{equation*}\]
Entonces, el modelo (2.13) se puede expresar de forma matricial así: \[\begin{equation} {{\bf{y}}_{{\bf{n \times 1}}}} = {{\bf{X}}_{n \times k}}{\beta_{k \times 1}} + {{\varepsilon _{n \times 1}}} \tag{2.14} \end{equation}\]
| \(y\) | \({X_2},{X_3},...,{X_k}\) |
|---|---|
| Variable dependiente | Variables independientes |
| Variable explicada | Variables explicativas |
| Variable de respuesta | Variables de control |
| Variable predicha | Variables predictoras |
| Regresando | Regresores |
| Fuente: elaboración propia. |
2.2.1 Supuestos
Es importante estudiar en detalle el vector de errores \(\varepsilon\). En general, esperaremos que el error no sea predecible y por tanto trataremos de evitar cualquier componente determinístico o comportamiento sistemático del error. Así, asumiremos que en promedio el término de error es cero. En otras palabras, el valor esperado de cada término de error es cero21. Formalmente, asumiremos que: \[\begin{equation} E\left[ {{{\varepsilon }}} \right] = 0 \tag{2.15} \end{equation}\] para todo \(i = 1,2,...,n\), o en forma matricial, \[\begin{equation} E\left[ {{{\varepsilon _i}}} \right] = {\bf {0}}. \end{equation}\]
Otro supuesto importante para garantizar que los errores son totalmente impredecibles es que cada uno de los errores sea linealmente independientes de los otros. En caso de existir dependencia lineal, habrá una forma de predecir errores futuros a partir de la historia de los errores. Por tanto, se asumirá que \[\begin{equation} E\left[ {{\varepsilon _i}{\varepsilon _j}} \right] = E\left[ {{\varepsilon _i}} \right]E\left[ {{\varepsilon _j}} \right] = 0 \tag{2.16} \end{equation}\] esto equivale a: \[\begin{equation*} Cov\left( {{\varepsilon _i},{\varepsilon _j}} \right) = E\left[ {{\varepsilon _i}{\varepsilon _j}} \right] - E\left[ {{\varepsilon _i}} \right]E\left[ {{\varepsilon _j}} \right] = 0 \end{equation*}\] A este supuesto se le conoce como el supuesto de no autocorrelación entre los errores.
Finalmente, asumiremos que cada uno de los errores tiene la misma varianza, es decir se asumirá que: \[\begin{equation} Var\left[ {{\varepsilon _i}} \right] = {\sigma ^2} \tag{2.17} \end{equation}\] para todo \(i = 1,2,...,n\). Este supuesto se conoce como homoscedasticidad.
En resumen, asumiremos que el error cumple con las siguientes condiciones:
- media cero,
- independencia lineal entre los errores y
- varianza constante.
Estos supuestos se acostumbran resumir de diferentes formas; por ejemplo, se pueden resumir los tres supuestos expresando que los errores están linealmente independientemente distribuidos con media cero y varianza constante, denotado por_ \[\begin{equation*} {\varepsilon _i} \sim l.i.d.\left( {0,{\sigma ^2}} \right) \end{equation*}\] Otra forma de escribir estos supuestos de forma matricial es: \[\begin{equation*} {{ \varepsilon}} \sim \left( {0,{\sigma ^2}{I_n}} \right), \end{equation*}\] donde, \[\begin{equation*} Var\left[ {\bf {\varepsilon}} \right] = \left[ {\begin{array}{*{20}{c}} {Var\left[ {{\varepsilon _1}} \right]} & {Cov\left( {{\varepsilon _1},{\varepsilon _2}} \right)} & \cdots & {Cov\left( {{\varepsilon _1},{\varepsilon _n}} \right)} \\ {Cov\left( {{\varepsilon _2},{\varepsilon _1}} \right)} & {Var\left[ {{\varepsilon _2}} \right]} & \cdots & {Cov\left( {{\varepsilon _2},{\varepsilon _n}} \right)} \\ \vdots & \vdots & \vdots & \vdots \\ {Cov\left( {{\varepsilon _n},{\varepsilon _1}} \right)} & {Cov\left( {{\varepsilon _n},{\varepsilon _2}} \right)} & \cdots & {Var\left[ {{\varepsilon _n}} \right]} \end{array}} \right] \end{equation*}\] \[\begin{equation} Var\left[ {\bf {\varepsilon}} \right] = \left[ {\begin{array}{*{20}{c}} {{\sigma ^2}} & {} & 0 \\ {} & \ddots & {} \\ 0 & {} & {{\sigma ^2}} \end{array}} \right] = {\sigma ^2}\left( {\begin{array}{*{20}{c}} 1 & {} & 0 \\ {} & \ddots & {} \\ 0 & {} & 1 \end{array}} \right) = {\sigma ^2}{\bf{I_n}} \tag{2.18} \end{equation}\]
Por otro lado, asumiremos que la información aportada por cada una de las variables explicatorias al modelo es relevante. Es decir, no habrá ningún tipo de relación lineal entre las variables explicativas; pues en caso que una variable de control se pudiera expresar como una combinación lineal de otras variables explicativas, la información de la primera variable sería irrelevante pues ya está contenida en las otras. Así, asumiremos que \({X_2},{X_3},...,{X_k}\) son linealmente independientes. A este supuesto también se le conoce como el supuesto de no multicolinealidad o no colinealidad) de las variables explicativas.
También, asumiremos que \({X_2},{X_3},...,{X_k}\) son variables no estocásticas, pues se espera que el proceso de muestreo implícito en el modelo \(\bf{y}= X\beta + \varepsilon\) debe poderse repetir numerosas veces y las variables exógenas no deben cambiar pues corresponden al diseño de nuestro “experimento”. Así, se asumirá que \({X_2},{X_3},...,{X_k}\) son determinísticas22 (no aleatorias) y linealmente independientes entre sí.
Otros supuestos implícitos en nuestro modelo de regresión lineal \(\bf{y} = X\beta + {\bf {\varepsilon}}\) es que hay en efecto una relación lineal entre \(y\) y \({X_2},{X_3},...,{X_k}\). Asimismo, se supone que esta relación es estable entre observaciones; es decir, los parámetros del vector \(\beta\) son constantes a lo largo de la muestra.
Finalmente, cabe mencionar que desde el punto de vista estadístico el modelo de regresión no tiene una connotación de causalidad asociada a él. Así, para el método estadístico es igualmente válido considerar una de las variables explicativas como variable dependiente y la variable dependiente como una variable explicativa.
Supuestos del modelo de regresión múltiple
En resumen, los supuestos del modelo de regresión múltiple son:
1 Relación lineal entre \(y\) y \({X_2},{X_3},...,{X_k}\)
2 \({X_2},{X_3},...,{X_k}\) son fijas y linealmente independientes (la matriz \(X\) tiene rango completo)
3 El vector de errores \({\bf {\varepsilon}}\) satisface:
- Media cero \(E\left[ {\bf {\varepsilon}} \right] = 0\)
- Varianza constante
- No autocorrelación.
Es decir, \(\varepsilon _i \sim i.i.d\left( {0,\sigma^2} \right)\) o \(\varepsilon _{n \times 1} \sim \left( \bf {0_{n \times 1}},\sigma^2{\bf {I_n}} \right)\).
2.2.2 Método de mínimos cuadrados ordinarios (MCO)
Como se mencionó anteriormente, dadas unas observaciones de la variable dependiente e independientes, normalmente se deseará conocer el valor de los coeficientes o parámetros (vector \(\beta\)). Para lograr acercarnos al valor poblacional desconocido de los coeficientes (\(\beta\)) se emplean estimadores (fórmulas) que responden a una idea plausible para “adivinar” el valor adecuado de estos23.
Consideremos un ejemplo muy sencillo como el que se presenta en la Figura 2.5 donde tenemos una muestra de \(n =\) 7. En este caso se recopiló información para la variable dependiente \(y\) y para una variable explicativa \(x\). Cada punto azul representa una observación (un pareja de \(y\) y \(x\)).
Figura 2.5: Ejemplo de una muestra observada para dos variables (\(y\) y \(x\))

En este caso, suponiendo la linealidad, el modelo estadístico con el que queremos describir la relación entre estas dos variables será: \[\begin{equation} {y_i} = {\beta_1} + {\beta_2}{x_{i}} + {\varepsilon _i} \tag{2.19} \end{equation}\] Así, el objetivo del científico de datos es encontrar el vector \(\beta\) que está formado por el intercepto (\(\beta_1\)) y la pendiente (\(\beta_2\)). En últimas encontrar el intercepto y la pendiente implica trazar una línea recta que aproxime todos los puntos de la Figura 2.5.
Existen muchas posibles rectas que podemos trazar. En la Figura 2.6 se muestran numerosas opciones. Cada línea corresponde a un conjunto “adivinado” (estimado) de intercepto y pendiente. La pregunta natural es ¿cuál de esas pendientes es la adecuada?.
Figura 2.6: Posibles líneas que se pueden trazar para una muestra observada de \(y\) y \(x\)

Una manera muy común de aproximarse a encontrar el “mejor” valor para los coeficientes poblacionales desconocidos (\(\beta\)) es minimizar la suma de los errores que produce el modelo elevados al cuadrado; este método se conoce con el nombre de Mínimos Cuadrados Ordinarios (MCO, o en inglés OLS). Intuitivamente, el método de MCO minimiza la suma de la distancia entre cada una de las observaciones de la variable dependiente (\({\bf {y}}\)) y lo que el modelo “predice” (\({\bf {\hat y}} = {\bf {X}}\hat \beta\)).
En la Figura 2.7 se presenta con líneas rojas cada una de las distancias entre el valor observado de la variable dependiente \(y_i\) y el valor que predice el modelo \(\hat y_1\) para un valor determinado de \(x_i\). En otras palabras, la líneas rojas se presentan cada uno de los errores de modelo estimado. La línea (en negro) se ha trazado minimizando la suma al cuadrado de cada una de estas distancias. De todas las líneas posibles (como las presentadas en la Figura 2.6), esta línea es la única que minimiza esa suma de errores al cuadrado.
Figura 2.7: Ejemplo de la línea trazada con el método MCO para una muestra observada para dos variables (\(y\) y \(x\))
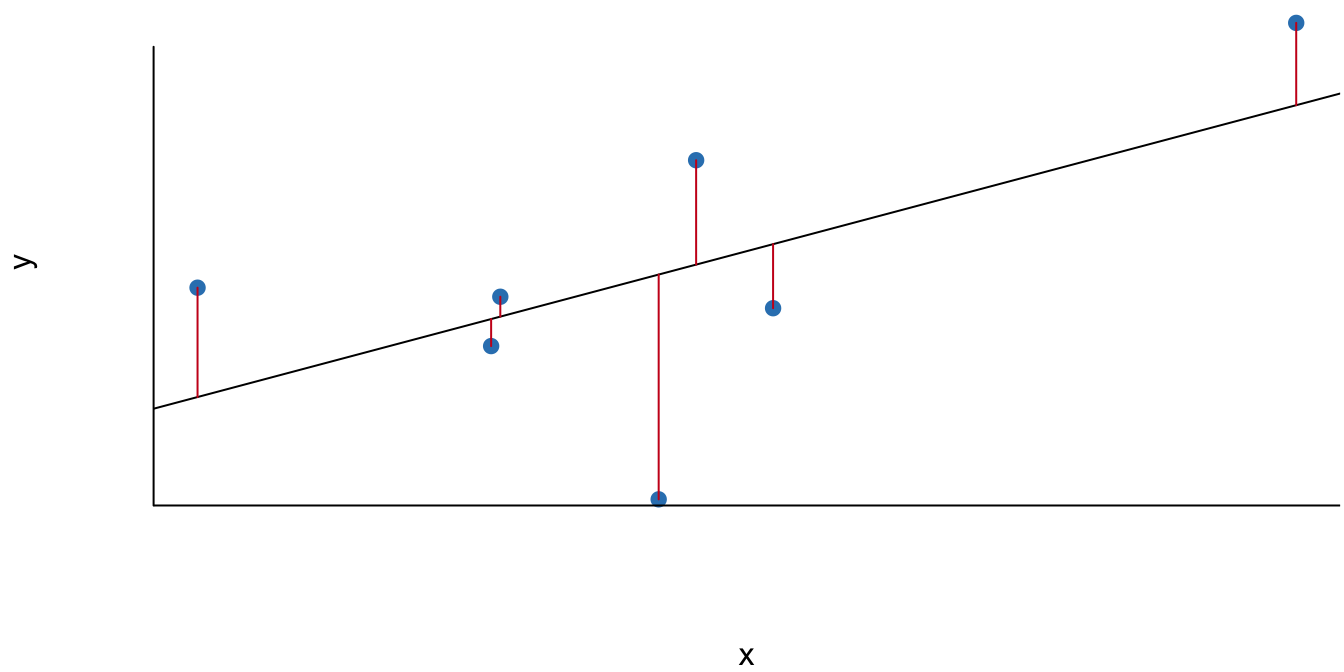
Esta idea de minimizar el cuadrado del error del modelo se puede ver graficado en la Figura 2.8. Las áreas de los cuadrados sombreadas en rojo representan cada uno de los errores del modelo (\(\hat \varepsilon _i\)) elevado al cuadrado. El tamaño del lado del cuadrado es \(\hat \varepsilon _i\) y, por tanto, el área del cuadrado corresponde a \(\hat \varepsilon _i^2\). El método MCO lo que hace es encontrar la línea que minimiza la suma de las áreas del cuadrado; cualquier otra línea que se trace tendrá una suma de las áreas de los respectivos cuadrados mayor a la del método MCO.
Figura 2.8: Ejemplo de la suma de los cuadrados de los errores que implica el método MCO

Formalmente, el estimador de MCO para el vector de coeficientes \(\beta\), denotado por \(\hat \beta\), se encuentra solucionando el siguiente problema: \[\begin{equation} \mathop {Min}\limits_{\hat \beta } \left \{ \left [ \bf{y} - \bf {\hat y} \right ]^T \left [ \bf{y} - \bf {\hat y} \right ] \right \} \tag{2.20} \end{equation}\] Es decir, minimizando el error del modelo cuadrado del modelo (la distancia entre el valor real y el estimado por el modelo). Esto es equivalente a: \[\begin{equation} \mathop {Min}\limits_{\hat \beta } \left\{ {{{\left[ {{\bf{y}} - {\bf{X}}\hat \beta } \right]}^T}\left[ {{\bf{y}} - {\bf{X}}\hat \beta } \right]} \right\} \tag{2.21} \end{equation}\] donde \(\bf{X}\hat \beta\) corresponde al vector de valores estimados por el modelo para la variable dependiente; en otras palabras, el modelo estimado. Así, el estimador de MCO del vector de coeficientes \(\beta\) es24: \[\begin{equation} \hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}} \tag{2.22} \end{equation}\] La ecuación estimada estará dada por: \[\begin{equation} {\bf{\hat y}} = {\bf{X}}\hat \beta \tag{2.23} \end{equation}\] La diferencia entre el vector de valores observados de la variable dependiente \(\bf{y}\) y los correspondientes valores estimados \(\bf{\hat y}\) se denomina el error estimado, residuos o residuales y se denota por \(\hat \varepsilon\); en otras palabras: \[\begin{equation} {\bf {\hat \varepsilon}} = {\bf {y}} - {\bf \hat {y}} = {\bf {y}} - {\bf {X}}\hat \beta \tag{2.24} \end{equation}\] En el Anexo al final de este capítulo se discuten algunas propiedades importantes del vector \(\bf{\hat \varepsilon}\).
Por otro lado, el estimador de MCO para la varianza del error \({\sigma ^2}\) es: \[\begin{equation} {s^2} = {\hat \sigma ^2} = \frac{{\sum\limits_{i = 1}^n {\hat \varepsilon _i^2} }}{{n - k}} = \frac{{{{\hat \varepsilon }^T}\hat \varepsilon }}{{n - k}} = \frac{{{{\bf{y}}^{\bf{T}}}{\bf{y}} - {{\hat \beta }^T}{{\bf{X}}^{\bf{T}}}{\bf{y}}}}{{n - k}} \tag{2.25} \end{equation}\] Y el estimador de MCO para la matriz de varianzas y covarianzas de \(\hat \beta\): \[\begin{equation} \widehat{Var\left[ \beta \right]} = {s^2}{\left( {{{\bf {X^T}}}{\bf {X}}} \right)^{ - 1}} \tag{2.26} \end{equation}\] Puesto que \({\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}\) es simétrica, la matriz de varianzas y covarianzas también lo será. Esta matriz tiene la varianza de los estimadores en la diagonal principal y las covarianzas en las posiciones fuera de la diagonal principal. En otras palabras: \[\begin{equation} \widehat{Var\left[ { \beta } \right]} = \left[ {\begin{array}{*{20}{c}} \widehat{Var\left[ {{{ \beta }_1}} \right]} & \widehat{Cov\left[ {{{ \beta }_1},{{ \beta }_2}} \right]} & \cdots & \widehat{Cov\left[ {{{ \beta }_1},{{ \beta }_k}} \right]} \\ {} & \widehat{Var\left[ {{{ \beta }_2}} \right]} & \cdots & \widehat{Cov\left[ {{{ \beta }_2},{{ \beta }_k}} \right]} \\ {} & {} & \ddots & \vdots \\ {} & {} & {} & \widehat{Var\left[ {{{ \beta }_k}} \right]} \end{array}} \right] \tag{2.27} \end{equation}\]
2.2.3 Propiedades de los estimadores MCO
El estimador de MCO de \(\beta\) es el estimador lineal insesgado con la mínima varianza posible, por esto, el estimador de MCO se conoce como el Mejor Estimador Lineal Insesgado (MELI)25. Este resultado se conoce como el Teorema de Gauss-Markov (ver recuadro abajo). La propiedad de que el estimador de MCO de \(\beta\) sea insesgado implica que en promedio el estimador obtendrá el valor real \(\beta\). Formalmente: \[\begin{equation} E\left[ {\hat \beta } \right] = \beta \tag{2.28} \end{equation}\] Y la segunda propiedad que tiene el estimador MCO de \(\beta\) se denomina eficiencia. Es decir, que tiene la mínima varianza posible cuando se compara con todos los otros posibles estimadores lineales. En otras palabras, estas dos propiedades implican que el estimador MCO de \(\beta\) es el mejor estimador lineal disponible, pues en promedio no se equivoca y cuando éste se equivoca tiene la mínima desviación posible.
Teorema de Gauss-Markov
Si se considera un modelo lineal \({{\bf{y}}_{n \times 1}} = {{\bf{X}}_{n \times k}}{\beta_{k \times 1}} + {\varepsilon _{n \times 1}}\) y se supone que:
- Las \({X_2},{X_3},...,{X_k}\) son fijas y linealmente independientes (es decir \(X\) tiene rango columna completo y es una matriz no estocástica).
- El vector de errores \(\varepsilon\) tiene media cero, varianza constante y no autocorrelación. Es decir: \(E\left[ \varepsilon \right] = 0\) y \(Var\left[ \varepsilon \right] = {\sigma ^2}{I_n}\)
Entonces, el estimador de MCO \(\hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}\) es el Mejor Estimador Lineal Insesgado (MELI).
En la práctica, el Teorema de Gauss-Markov implica que si garantizamos que se cumplen los supuestos entorno al error y de una matriz de regresores con rango completo, entonces el estimador de MCO será MELI.
2.3 Práctica en R
En todos los capítulos de este libro, encontrarás ejercicios que serán resueltos paso a paso mediante el uso de R (R Core Team, 2023). En este capítulo explicaremos detenidamente desde ¿cómo cargar los datos?, hasta ¿cómo estimar un modelo por MCO?.
Para este ejercicio, nos enfrentamos a una situación en la que un gerente de mercadeo quiere determinar el efecto de aumentar en un dólar el precio del azúcar sobre la demanda de ésta, el principal producto de esta organización. En otras palabras, la pregunta de negocio es ¿qué efecto tiene un aumento de un dólar sobre la demanda de azúcar?. Esta pregunta de negocio claramente implica emplear analítica diagnóstica y una tarea de estimar regresiones .
Cuando tenemos una pregunta de negocio a responder, de inmediato tenemos qué preguntarnos que datos tenemos. En este caso tenemos a nuestra disposición una base de datos relativamente limitada. Contamos con datos mensuales para los últimos 60 meses26 de las siguientes variables:
Q= las toneladas de azúcar vendidas a los minoristas27 (\(Q_t\))p= precio por libra en dólares que cobra la organización a sus distribuidores (\(p_t\))pcomp= precio por libra en dólares que cobra el principal competidor a sus distribuidores (\(p_{comp,t}\))IA= índice de actividad económica (\(IA_t\)).
Los datos están disponibles en el archivo adjunto (DataCap1.csv)28. Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/. Lastimosamente no contamos con más datos.
Con los datos disponibles podemos proceder a construir un primer posible modelo candidato a describir el comportamiento de las cantidades demandadas. El modelo sería: \[\begin{equation} Q_t = {\beta_1} + {\beta_2}p_t + {\beta_3}p_{comp,t} + {\beta_4} IA_t + {\varepsilon_t}. \tag{2.29} \end{equation}\]
De esta manera dados los datos disponibles en el archivo adjunto, se desea estimar el modelo (2.29). Y para poder responder la pregunta de negocio, será necesario concentrar nuestra atención sobre \(\beta_2\) que representa el efecto de un aumento de un dólar en el precio de la organización por libra del azúcar sobre su demanda. Noten que es importante incluir más variables que \(p_t\) en el modelo de regresión, pues como se discutió en la sección 1.3 nuestro primer objetivo es encontrar el DGP. Y con este DGP responder las preguntas de negocio. Por otro lado, otra razón técnica para tratar de emplear todas aquellas variables que afectan a la variable dependiente es que esto minimizará el tamaño del error de nuestro modelo.
2.3.1 Lectura de datos
Recuerde que usted puede importar los datos de un archivo csv (archivo delimitado por comas) utilizando la función read.csv() del paquete base de R. Esta función como mínimo necesita los siguientes argumentos:donde:
- file: es el nombre del archivo y su ruta que se debe poner entre comillas.
- header: es un operador lógico que le dice a la función si la primera fila del archivo csv contiene el encabezado con el nombre de las variables. Por defecto
header = TRUEse espera que la primera fila del archivo contenga el nombre de las variables. - sep: Es el delimitador de los campos que emplea el archivo csv. Por defecto, se espera una coma.
Para este ejemplo, descargue el archivo DataCap1.csv en su computador en el directorio de trabajo o en una ubicación que le sea conveniente (recuerde que si el archivo no se encuentra en el directorio de trabajo, usted tendrá que especificar toda la ruta del fólder donde se encuentra el archivo). Importemos los datos empleando la función read.csv() y guardemos los datos en el objeto DatosCap1.
Para asegurarse de que R haya leído sus datos correctamente, resulta importante mirar qué es lo que efectivamente el programa guardó en el objeto que hemos denominado DatosCap1. Para ello podemos ver las primeras filas del objeto y la clase de objeto de la siguiente manera:
## ...1 Q p pcomp IA
## 1 1 529.904 8.81 8.40 1.8
## 2 2 1041.318 7.46 10.85 1.7
## 3 3 874.360 9.14 6.52 3.6
## 4 4 821.920 8.68 11.77 2.7
## 5 5 953.396 7.27 10.20 2.5
## 6 6 651.249 8.67 5.54 1.1## [1] "data.frame"Noten que el objeto DatosCap1 fue leído como un data.frame que contiene una primera columna con un índice (esta fue denominada ..1), y cuatro columnas más que contienen las variables Q, p, pcomp e IA. Procedamos a eliminar la primera columna que no serán necesarias. Y constatemos que las variables que nos quedan en el data.frame son numéricas. Esto se puede hacer de diferentes maneras.
## Q p pcomp IA
## 1 529.904 8.81 8.40 1.8
## 2 1041.318 7.46 10.85 1.7
## 3 874.360 9.14 6.52 3.6
## 4 821.920 8.68 11.77 2.7
## 5 953.396 7.27 10.20 2.5
## 6 651.249 8.67 5.54 1.1## Q p pcomp IA
## "numeric" "numeric" "numeric" "numeric"## 'data.frame': 60 obs. of 4 variables:
## $ Q : num 530 1041 874 822 953 ...
## $ p : num 8.81 7.46 9.14 8.68 7.27 8.67 7.96 7.53 6.34 9.56 ...
## $ pcomp: num 8.4 10.85 6.52 11.77 10.2 ...
## $ IA : num 1.8 1.7 3.6 2.7 2.5 1.1 1.5 1.3 3.1 2 ...2.3.2 Estimación del modelo
Recordemos que se desea estimar el modelo presentado en (2.29). Antes de estimar el modelo, una buena práctica cuando se tiene pocas variables en la base de datos es graficar las variables y su relación con la variable dependiente. Típicamente se emplea un diagrama de dispersión, en nuestro caso tendremos.
plot(DatosCap1$p, DatosCap1$Q, xlab = "precio (dólares por libra)",
ylab = "Cantidades de azúcar (ton)")Otra opción es emplear los paquetes ggplot229 (Wickham, 2016) y GGally (Schloerke et al., 2021) para tener una visualización más agradable como la que se presenta en las Figuras 2.9 y 2.10.
# Cargar paquetes
library(ggplot2)
library(GGally)
# Figura 2.9
ggpairs(DatosCap1)+theme_minimal()
# Figura 2.10
ggplot(DatosCap1, aes( Q, p)) + geom_point(color='blue') +
labs(x = "precio (dólares por libra)",
y = "Cantidades de azúcar (ton)") +
geom_smooth(method = "lm", se = FALSE) + theme_minimal()Figura 2.9: Relación entre todas las variables de la base de datos
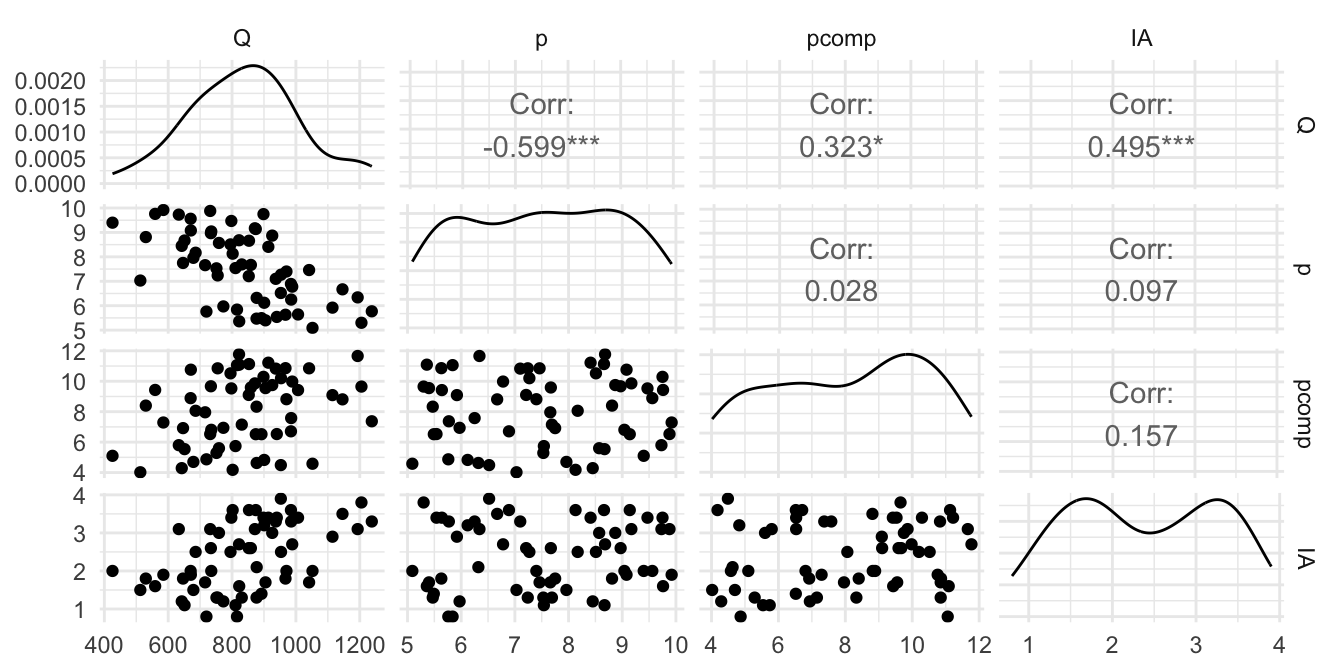
Figura 2.10: Relación entre las cantidades demandas de azúcar y el precio
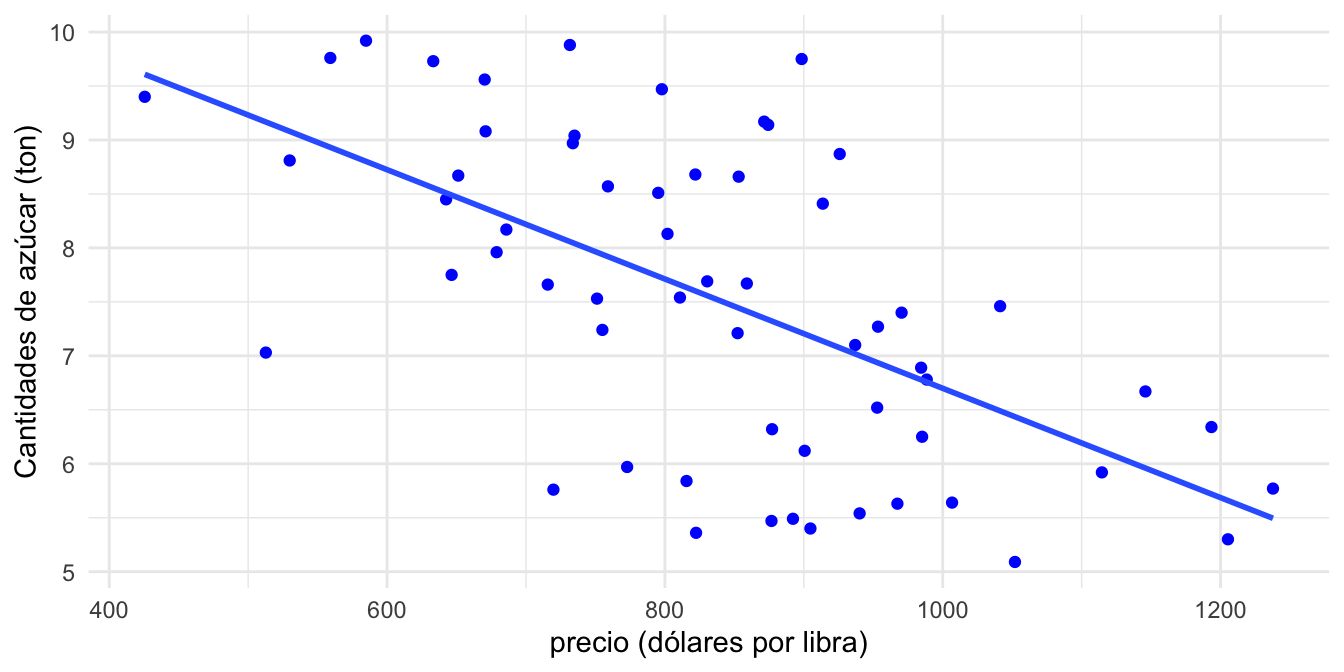
La Figura 2.10 nos sugiere la existencia de una relación lineal por lo menos entre estas dos variables. Procedamos a estimar el modelo.
Para estimar este modelo por el método de mínimos cuadrados ordinarios la forma más simple es utilizando la función lm() . Esta función se utiliza para ajustar modelos lineales y hace parte del paquete stats que a su vez hace parte del núcleo de paquetes pre instalados en R, motivo por el cual éste ya se encuentra cargado. Los dos principales argumentos de la función lm() son dos: el modelo a estimar denominado fórmula y los datos que se emplearán. En nuestro caso:
# Estimar el modelo
R1 <- lm(formula = Q ~ p + pcomp + IA, data = DatosCap1)
# Chequear la clase del objeto
class(R1)## [1] "lm"##
## Call:
## lm(formula = Q ~ p + pcomp + IA, data = DatosCap1)
##
## Coefficients:
## (Intercept) p pcomp IA
## 1026.37 -77.62 19.27 100.46En este caso hemos guardado en el objeto R1 los resultados de estimar (2.29). Este objeto será de clase lm. Noten que se empleo la virgulilla (palito de la eñe) para representar el signo igual de la expresión (2.29), también es importante anotar que no fue necesario escribir todos los parámetros deseados, R por defecto incluye un intercepto y los correspondientes coeficientes (elementos del vector \(\beta\)) que representan pendientes. Para observar los resultados del modelo estimado se puede emplear la función summary() de la siguiente manera:
##
## Call:
## lm(formula = Q ~ p + pcomp + IA, data = DatosCap1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -196.09 -50.92 -16.91 69.17 214.16
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1026.371 76.634 13.393 < 2e-16 ***
## p -77.624 8.195 -9.472 3.15e-13 ***
## pcomp 19.270 5.177 3.722 0.00046 ***
## IA 100.458 13.606 7.384 8.04e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 91.27 on 56 degrees of freedom
## Multiple R-squared: 0.7337, Adjusted R-squared: 0.7194
## F-statistic: 51.42 on 3 and 56 DF, p-value: 4.264e-16Otras formas de expresar la fórmula que llevarán al mismo resultado (compruébelo) son:
R1a <- lm( Q ~ p + pcomp + IA, DatosCap1)
formula1 <- Q ~ p + pcomp + IA
R2 <- lm( formula1 , DatosCap1)
R3 <- lm( Q ~ ., DatosCap1)La última forma de expresar la fórmula con un punto implica emplear todas las variables que se encuentran en la base de datos (diferentes a la que se seleccionó para ser la dependiente) como variables explicativas. Dado que en nuestro caso solo tenemos las tres variables explicativas, por eso el resultado es el mismo que en los casos anteriores.
Sin embargo, si se necesita que el resultado de la estimación se muestre como la tabla que regularmente se utiliza en la presentación de documentos y está empleando LaTex o formato html, usted puede utilizar el paquete stargazer (Hlavac, 2018) . Una vez instalado el paquete, podemos utilizar la función del mismo nombre para obtener la tabla en el formato deseado (Ver Cuadro 2.2) de la siguiente manera.
library(stargazer)
stargazer(R1, t.auto=TRUE, p.auto = TRUE,
title="Modelo estimado por MCO",
label ="res2.Hetero",
header= FALSE, table.placement="H",
notes.align = "l", type = "latex")| (Intercept) | 1026.37*** |
| (76.63) | |
| p | -77.62*** |
| (8.20) | |
| pcomp | 19.27*** |
| (5.18) | |
| IA | 100.46*** |
| (13.61) | |
| R2 | 0.73 |
| Adj. R2 | 0.72 |
| Num. obs. | 60 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Nota que en este caso la ecuación estimada será:
\[\begin{equation} {\hat Q_t} = 1026.37 + -77.62 {p_t} + 19.27 p_{comp,t} + 100.46 IA_t \end{equation}\]
Así, el resultado implica que por cada dólar por libra adicional en el precio del producto la demanda caerá en promedio en 77.62 toneladas mes.
Para obtener la matriz de varianzas y covarianzas del intercepto y las pendientes, que son otras cantidades que desconocíamos, se puede emplear la función vcov() de la siguiente manera:
Esto quiere decir que en este caso, se tiene que:
\[\begin{equation} \hat \beta_1 = 1026.37 \end{equation}\] \[\begin{equation} \hat \beta_2 = -77.62 \end{equation}\] \[\begin{equation} \hat \beta_3 = 19.27 \end{equation}\] \[\begin{equation} \hat \beta_4 =100.46 \end{equation}\] \[\begin{equation} \sqrt{ \widehat{Var\left ( \beta_1 \right )}} = {S_{{{\hat \beta }_{_1}}}} = 76.63 \end{equation}\]
\[\begin{equation} \sqrt{ \widehat{Var\left ( \beta_2 \right )}} = {S_{{{\hat \beta }_{_2}}}} = 8.2 \end{equation}\]
\[\begin{equation} \sqrt{ \widehat{Var\left (\beta_3 \right )}} = {S_{{{\hat \beta }_{_3}}}} = 5.18 \end{equation}\]
\[\begin{equation} \sqrt{ \widehat{Var\left (\beta_4 \right )}} = {S_{{{\hat \beta }_{_4}}}} = 13.61 \end{equation}\]
Como se discutirá en el próximo capítulo, del Cuadro 2.2 podemos concluir que el coeficiente asociado al precio es significativo ya que el estadístico t es relativamente alto (y el valor p asociado a este es muy pequeño). Así, este coeficiente es estadísticamente diferente de cero. Esto hace que nuestra respuesta a la pregunta de negocio sea correcta. Pero esto se discutirá en detalle en el próximo capítulo en el que discutiremos la inferencia a partir del modelo de regresión múltiple.
2.4 Ejercicios
Las respuestas a estos ejercicios se encuentran en la sección 16.1.
2.4.1 Función Cobb-Douglas
Demuestre que los coeficientes de una función Cobb-Douglas como la representada en (2.10) se puede interpretar como elasticidades.
2.4.2 Ejercicio práctico
El gobierno de una pequeña República está reconsiderando la viabilidad del transporte ferroviario, para lo cual contrata un estudio que determine un modelo que permita comprender de una forma más precisa el comportamiento de los ingresos del sector (\(I\) medidos en millones de dólares). Un científico de datos, plantea el siguiente modelo, dada la disponibilidad de datos existente:
\[\begin{equation} {I_t} = {\alpha _1} + {\alpha _2}{CE_t} + {\alpha _3}{CD_t} + {\alpha _4}{LDies_t} + {\alpha _5}{LEI_t} + {\alpha _6}{V_t} + {\varepsilon _t} \tag{2.30} \end{equation}\]
donde, \(CE_t\), \(CD_t\), \(LDies_t\), \(LEI_t\) y \(V_t\) representan el consumo de electricidad medido en millones de Kilovatios/hora, el consumo de diésel medido en millones de galones, el número de locomotoras diésel en el país, el número de locomotoras eléctricas y el número de viajeros (medido en miles de pasajeros) en el año \(t\), respectivamente.
Para efectuar este estudio se cuenta con los datos disponibles en el archivo regmult.csv. Su misión es estimar el modelo (2.30) empleando el método MCO y reportar sus resultados en una tabla. Posteriormente, interprete cada uno de los coeficientes estimados.
2.5 Anexos
2.5.1 Derivación de los estimadores MCO
Formalmente, el estimador de MCO para el vector de coeficientes \(\beta\) en el modelo (2.21), denotado por \(\hat \beta\), se encuentra minimizando la distancia cuadrada entre cada valor observado del vector de realizaciones de la variable aleatoria dependiente (\(\bf y\)) y el vector de estimaciones del modelo (\({{\bf{\hat y}}} = {\bf{X}}\hat \beta\)). Formalmente, el problema es: \[\begin{equation} \mathop {Min}\limits_{\hat \beta } \left\{ {{{\left[ {{\bf{y}} - {\bf{X}}\hat \beta } \right]}^T}\left[ {{\bf{y}} - {\bf{X}}\hat \beta } \right]} \right\} \tag{2.31} \end{equation}\] Antes de encontrar las condiciones de primer orden y las de segundo orden para un mínimo, podemos simplificar un poco el problema expresado en la ecuación (2.31). Así, tenemos que: \[\begin{equation} \mathop {Min}\limits_{\hat \beta } \left\{ {\left[ {{{\bf{y}}^{\bf{T}}} - {{\hat \beta }^T}{{\bf{X}}^{\bf{T}}}} \right]\left[ {{\bf{y}} - {\bf{X}}\hat \beta } \right]} \right\} \end{equation}\] Al multiplicar los elementos dentro de los corchetes cuadrados obtenemos: \[\begin{equation} \mathop {Min}\limits_{\hat \beta } \left\{ {{{\bf{y}}^{\bf{T}}}{\bf{y}} - {{\hat \beta }^T}{{\bf{X}}^{\bf{T}}}{\bf{y}} - {{\bf{y}}^{\bf{T}}}{\bf{X}}\hat \beta + {{\hat \beta }^T}{{\bf{X}}^{\bf{T}}}{\bf{X}}\hat \beta } \right\} \end{equation}\]
Observen que \({{\bf{y}}^{\bf{T}}}_{{\bf{1 \times n}}}{{\bf{X}}_{{\bf{n \times k}}}}{\hat \beta_{k \times 1}} = {\left( {{{\hat \beta }^T}_{k \times 1}{{\bf{X}}^{\bf{T}}}_{{\bf{n \times k}}}{{\bf{y}}_{{\bf{1 \times n}}}}} \right)^T}\) y además los productos \({\hat \beta ^T}_{1 \times k}{{\bf{X}}^{\bf{T}}}_{{\bf{k \times n}}}{{\bf{y}}_{{\bf{n \times 1}}}}\) y \({{\bf{y}}^{\bf{T}}}_{{\bf{1 \times n}}}{{\bf{X}}_{{\bf{n \times k}}}}{\hat \beta_{k \times 1}}\) son escalares, por tanto \({{\bf{y}}^{\bf{T}}}_{{\bf{1 \times n}}}{{\bf{X}}_{{\bf{n \times k}}}}{\hat \beta_{k \times 1}} = {\hat \beta ^T}_{1 \times k}{{\bf{X}}^{\bf{T}}}_{{\bf{k \times n}}}{{\bf{y}}_{{\bf{n \times 1}}}}\). Así, el problema (2.31) es equivalente a: \[\begin{equation} \mathop {Min}\limits_{\hat \beta } \left\{ {{{\bf{y}}^{\bf{T}}}{\bf{y}} - 2{{\hat \beta }^T}{{\bf{X}}^{\bf{T}}}{\bf{y}} + {{\hat \beta }^T}{{\bf{X}}^{\bf{T}}}{\bf{X}}\hat \beta } \right\} \tag{2.32} \end{equation}\]
Ya podemos regresar a nuestro problema de minimización y considerar la condición de primer orden para este problema, en este caso la condición es30: \[\begin{equation} \frac{\partial }{{\partial \hat \beta }}\left\{ \bullet \right\} = - 2{{\bf{X}}^{\bf{T}}}{\bf{y}} + 2{{\bf{X}}^{\bf{T}}}{\bf{X}}\hat \beta \equiv 0 \tag{2.33} \end{equation}\] La expresión (2.33) se conoce como las ecuaciones normales. Ahora, despejando \(\hat \beta\), obtenemos: \[\begin{equation} 2{{\bf{X}}^{\bf{T}}}{\bf{X}}\hat \beta = 2{{\bf{X}}^{\bf{T}}}{\bf{y}} \end{equation}\] Multiplicando a ambos lados por la inversa de \({{\bf{X}}^{\bf{T}}}{\bf{X}}\), tendremos: \[\begin{equation} {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)\hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}} \end{equation}\] Así, el estimado de MCO del vector de coeficientes \(\beta\) es: \[\begin{equation} \hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}} \end{equation}\] La condición de segundo orden implica \(\frac{{\partial \left\{ \bullet \right\}}}{{\partial \beta \;\partial \beta }} = 2{\bf{X}}^{\bf{T}} {\bf{X}}\). Noten que \(\left( {{\bf{X}}^{\bf{T}} {\bf{X}}} \right)\) es una matriz positiva semi-definida lo que garantiza que \(\hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}\) es un mínimo.
2.5.2 Demostración del Teorema de Gauss-Markov
El Teorema de Gauss-Markov implica los siguientes supuestos:
Existe una relación lineal entre \(\bf{y}\) y las variables en la matriz \(\bf{X}\) que se puede representar por el modelo lineal \({{\bf{y}}_{{\bf{n \times 1}}}} = {{\bf{X}}_{{\bf{n \times k}}}}{\beta_{k \times 1}} + {\bf{ \varepsilon _{n \times 1}}}\)
\({X_2},{X_3},...,{X_k}\) son no estocásticas y linealmente independientes (es decir \(\bf X\) tiene rango completo y es una matriz no estocástica)
El vector de errores \(\varepsilon\) tiene media cero, varianza constante y no autocorrelación. Es decir, \(E\left[ \varepsilon \right] = 0\) y \(Var\left[ {\bf {\varepsilon}} \right] = {\sigma ^2}{\bf {I_n}}\)
Entonces el estimador de MCO, \(\hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}\), es insesgado y eficiente. En otras palabras, \(\hat \beta\) es el Mejor Estimador Lineal Insesgado (MELI) para el vector de coeficientes poblacionales \(\beta\).
A continuación demostraremos este Teorema. Primero, demostremos que \(\hat \beta\) es un estimador insesgado del vector de coeficientes poblacionales \(\beta\). Formalmente, tenemos que demostrar que \(E\left[ {\hat \beta } \right] = \beta\). Para lograr tal fin calculemos el valor esperado del estimador MCO: \[\begin{equation*} E\left[ {\hat \beta } \right] = E\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}} \right] \end{equation*}\] Empleando el supuesto de que las variables explicativas son no estocásticas tenemos que, \[\begin{equation*} E\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}E\left[ {\bf{y}} \right] \end{equation*}\] Y por tanto, \[\begin{equation*} E\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}E\left[ {{\bf{X}}\beta + \varepsilon } \right] \end{equation*}\] \[\begin{equation*} E\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{X}}\beta + {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}E\left[ \varepsilon \right] \end{equation*}\] Recuerden que habíamos supuesto que \(E\left[ \varepsilon \right] = 0\). Esto implica que \[\begin{equation*} E\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{X}}\beta = I \cdot \beta \end{equation*}\] \[\begin{equation*} E\left[ {\hat \beta } \right] = \beta \end{equation*}\] Así, hemos demostrado que el estimador MCO es insesgado.
Antes de continuar con la demostración del Teorema de Gauss-Markov, encontremos la varianza del estimador de MCO. Es decir, \[\begin{equation*} Var\left[ {\hat \beta } \right] = Var\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}} \right] \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = \left( {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}} \right)Var\left[ {\bf{y}} \right]{\left( {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}} \right)^T} \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = \left( {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}} \right)Var\left[ {\bf{y}} \right]\left( {{\bf{X}}{{\left( {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}} \right)}^T}} \right) \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}Var\left[ {\bf{y}} \right]{\bf{X}}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}} \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}Var\left[ {{\bf{X}}\beta + \varepsilon } \right]{\bf{X}}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}} \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}Var\left[ \varepsilon \right]{\bf{X}}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}} \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\sigma ^2}{\bf{X}}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}} \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = {\sigma ^2}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{X}}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}} \end{equation*}\] \[\begin{equation*} Var\left[ {\hat \beta } \right] = {\sigma ^2}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}} \end{equation*}\]
Ahora retornemos al Teorema de Gauss-Markov, para demostrarlo es necesario probar que este estimador tiene la mínima varianza entre todos los posibles estimadores lineales insesgados de \(\beta\).
Sin perder generalidad, consideremos otro estimador lineal cualquiera \(\tilde \beta = \left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]{\bf{y}}\). Si \(\tilde \beta\) es insesgado, se debe cumplir que \(E\left[ {\tilde \beta } \right] = \beta\). Es decir: \[\begin{equation*} E\left[ {\tilde \beta } \right] = \left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]E\left[ {\bf{y}} \right] \end{equation*}\] \[\begin{equation*} E\left[ {\tilde \beta } \right] = \left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]E\left[ {{\bf{X}}\beta + \varepsilon } \right] = \left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]\left[ {{\bf{X}}\beta + 0} \right] \end{equation*}\] \[\begin{equation*} E\left[ {\tilde \beta } \right] = \left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{X}}\beta + C{\bf{X}}\beta } \right] \end{equation*}\] \[\begin{equation*} E\left[ {\tilde \beta } \right] = \beta + C{\bf{X}}\beta \end{equation*}\] Para que este estimador sea insesgado, tiene que cumplirse que \(C{\bf{X}} = 0\).
Ahora, analicemos la varianza de este nuevo estimador lineal insesgado. \[\begin{equation*} Var\left[ {\tilde \beta } \right] = Var\left[ {\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]{\bf{y}}} \right] \end{equation*}\] \[\begin{equation*} Var\left[ {\tilde \beta } \right] = \left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]Var\left[ {\bf{y}} \right]{\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]^T} \end{equation*}\] \[\begin{equation*} Var\left[ {\tilde \beta } \right] = \left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]{\sigma ^2}{I_n}{\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]^T} \end{equation*}\] \[\begin{equation*} Var\left[ {\tilde \beta } \right] = {\sigma ^2}\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}} + C} \right]\left[ {{\bf{X}}{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}} + {C^T}} \right] \end{equation*}\] \[\begin{equation*} Var\left[ {\tilde \beta } \right] = {\sigma ^2}\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{X}}{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}} + C{\bf{X}}{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}} + {{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}{C^T} + C{C^T}} \right] \end{equation*}\] \[\begin{equation*} Var\left[ {\tilde \beta } \right] = {\sigma ^2}\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}} + C{\bf{X}}{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}} + {{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\left( {C{\bf{X}}} \right)}^T} + C{C^T}} \right] \end{equation*}\] Como la condición \(C{\bf{X}} = 0\) para que \(\tilde \beta\) sea insesgado tiene que cumplirse, entonces: \[\begin{equation*} Var\left[ {\tilde \beta } \right] = {\sigma ^2}\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}} + C{C^T}} \right] \end{equation*}\] \(C{C^T}\) es una matriz cuyos elementos en la diagonal principal serán positivos31. (¿Por qué?) Ahora comparemos la varianza de nuestro estimador de MCO (\(\hat \beta\)) con \(\tilde \beta\). Recuerden que \(Var\left[ {\hat \beta } \right] = {\sigma ^2}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}\), adicionalmente observen que \(Var\left[ {\tilde \beta } \right] = {\sigma ^2}\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}} + C{C^T}} \right]\) no puede ser menor que \({\sigma ^2}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}\), pues:
\(Var\left[ {{{\tilde \beta }_i}} \right] = {\sigma ^2}\left\{ {\left[ {\left( {{\bf{XX}}} \right)_{ii}^{ - 1} + CC_{ii}^T} \right]} \right\}\), donde \({A_{ij}}\) corresponde al elemento en la fila \(i\) y columna \(j\) de la matriz \(A\), y
\(CC_{ii}^T\) es positivo.
Por tanto \(Var\left[ {{{\tilde \beta }_i}} \right] = {\sigma ^2}\left\{ {\left[ {\left( {{\bf{XX}}} \right)_{ii}^{ - 1} + CC_{ii}^T} \right]} \right\} > Var\left[ {{{\hat \beta }_i}} \right] = {\sigma ^2}\left[ {\left( {{\bf{XX}}} \right)_{ii}^{ - 1}} \right]\). En el mejor de los casos \(Var\left[ {\tilde \beta } \right] = {\sigma ^2}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}\) y eso sólo ocurre cuando \(C=0\). En este caso \(\tilde \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}} = \hat \beta\), es decir la mínima varianza posible de un estimador lineal insesgado es igual a la varianza del estimador MCO. Por tanto \(\hat \beta\) es MELI.
2.5.3 Algunas propiedades importantes de los residuos estimados.
Como se discutió anteriormente, se tiene que los residuos estimados están definidos como \[\begin{equation*} \hat \varepsilon = y - {\mathbf{X}}\hat \beta \end{equation*}\] La primera propiedad que cumple el vector de residuos (\(\hat \varepsilon\)) es: \[\begin{equation} {\mathbf{X}}^T \hat \varepsilon = 0 \tag{2.34} \end{equation}\] Para demostrar esta propiedad podemos partir de la definición de los residuos estimados. Es decir, tenemos que: \[\begin{equation*} {\mathbf{X}}^T \hat \varepsilon = {\mathbf{X}}^T \left[ {y - {\mathbf{X}}\hat \beta } \right] = {\mathbf{X}}^T y - {\mathbf{X}}^T {\mathbf{X}}\hat \beta \end{equation*}\] Además, sustituyendo \({\hat \beta }\) se tiene \[\begin{equation*} {\mathbf{X}}^T \hat \varepsilon = {\mathbf{X}}^T y - {\mathbf{X}}^T {\mathbf{X}}\left( {{\mathbf{X}}^T {\mathbf{X}}} \right)^{ - 1} {\mathbf{X}}^T y \end{equation*}\] Por lo tanto, \[\begin{equation*} {\mathbf{X}}^T \hat \varepsilon = {\mathbf{X}}^T y - {\mathbf{X}}^T y = 0 \end{equation*}\]
De esta propiedad se desprende un resultado muy interesante. Dado que esta propiedad implica que:
\[\begin{equation*} {\mathbf{X}}^T \hat \varepsilon = \left[ {\begin{array}{*{20}c} {\sum\limits_{i = 1}^n {X_{1i} \hat \varepsilon _i } } {\sum\limits_{i = 1}^n {X_{2i} \hat \varepsilon _i } } \vdots {\sum\limits_{i = 1}^n {X_{ki} \hat \varepsilon _i } } \end{array} } \right] = \left[ {\begin{array}{*{20}c} 0 0 \vdots 0 \end{array} } \right] \end{equation*}\] Entonces, se desprende un resultado importante. Si el modelo tiene intercepto la suma de los residuos estimados será cero.
Esta afirmación se puede demostrar fácilmente. Noten que en caso de tener intercepto el modelo, \({\mathbf{X}}\) tendrá una columna de unos. Por ejemplo, \(X_{1i} = 1\) y se desprende que: \[\begin{equation} \sum\limits_{i = 1}^n {\hat \varepsilon _i } = 0. \tag{2.35} \end{equation}\] Este último resultado implica que la media del residuo estimado sea cero. En otras palabras: \[\begin{equation} \bar{\hat \varepsilon}= \frac{\sum\limits_{i = 1}^n {\hat \varepsilon _i } } {n}=0 \tag{2.36} \end{equation}\]
La segunda propiedad de los residuos estimados que discutiremos es que: \[\begin{equation} E\left[ {\hat \varepsilon ^T \hat \varepsilon } \right] = E\left[ {\sum\limits_{i = 1}^n {\hat \varepsilon _i^2 } } \right] = \left( {n - 2} \right)\sigma ^2 . \tag{2.37} \end{equation}\] Para demostrar esta propiedad, reescribamos de manera más conveniente los residuos estimados: \[\begin{equation*} \hat \varepsilon = y - {\mathbf{X}}\hat \beta = y - {\mathbf{X}}\left( {{\mathbf{X}}^T {\mathbf{X}}} \right)^{ - 1} {\mathbf{X}}^T y \end{equation*}\] \[\begin{equation*} \hat \varepsilon = \left[ {I - {\mathbf{X}}\left( {{\mathbf{X}}^T {\mathbf{X}}} \right)^{ - 1} {\mathbf{X}}^T } \right]y. \end{equation*}\] Ahora, definamos la matriz \({\mathbf{M}} = I - {\mathbf{X}}\left( {{\mathbf{X}}^T {\mathbf{X}}} \right)^{ - 1} {\mathbf{X}}^T\). Es muy fácil mostrar (hágalo) que \({\mathbf{M}}\) es idempotente y simétrica. Entonces, se tiene que los residuos estimados se pueden expresar de la siguiente manera: \[\begin{equation} \hat \varepsilon = {\mathbf{M}}y = {\mathbf{MX}}\beta + {\mathbf{M}}\varepsilon = {\mathbf{M}}\varepsilon \tag{2.38} \end{equation}\] Es importante anotar que \({\mathbf{MX}}\beta = 0\), dado que \[\begin{equation*} {\mathbf{MX}}\beta = \left[ {I - {\mathbf{X}}\left( {{\mathbf{X}}^T {\mathbf{X}}} \right)^{ - 1} {\mathbf{X}}^T } \right]{\mathbf{X}}\beta = \left[ {{\mathbf{X}}\beta - {\mathbf{X}}\beta } \right] = 0. \end{equation*}\]
Regresando a (2.38), se tiene que: \[\begin{equation*} E\left[ {\hat \varepsilon ^T \hat \varepsilon } \right] = E\left[ {\left( {{\mathbf{M}}\varepsilon } \right)^T {\mathbf{M}}\varepsilon } \right] = E\left[ {\varepsilon ^T {\mathbf{M}}^T {\mathbf{M}}\varepsilon } \right] = E\left[ {\varepsilon ^T {\mathbf{M}}\varepsilon } \right]. \end{equation*}\] Y dado que el producto \({\hat \varepsilon ^T \hat \varepsilon }\) es un escalar tendremos que: \[\begin{equation*} E\left[ {\hat \varepsilon ^T \hat \varepsilon } \right] = trace\left( {\varepsilon ^T {\mathbf{M}}\varepsilon } \right) = trace\left( {{\mathbf{M}}\varepsilon ^T \varepsilon } \right). \end{equation*}\] Empleando las propiedades de la traza, \[\begin{equation*} E\left[ {\hat \varepsilon ^T \hat \varepsilon } \right] = trace\left( {{\mathbf{M}}\sigma ^2 I} \right) = \sigma ^2 trace\left( {\mathbf{M}} \right). \end{equation*}\] Noten que encontrar la traza de la matriz \({\mathbf{M}}\) es muy sencillo pues, \[\begin{equation*} trace\left( {\mathbf{M}} \right) = trace\left( {I_n } \right) - trace\left( {{\mathbf{X}}\left( {{\mathbf{X}}^T {\mathbf{X}}} \right)^{ - 1} {\mathbf{X}}^T } \right) \end{equation*}\] y empleando otras propiedades de la traza sabemos que: \[\begin{equation*} trace\left( {\mathbf{M}} \right) = trace\left( {I_n } \right) - trace\left( {\left( {{\mathbf{X}}^T {\mathbf{X}}} \right)^{ - 1} {\mathbf{X}}^T {\mathbf{X}}} \right). \end{equation*}\] De esta manera se tiene que \[\begin{equation*} trace\left( {\mathbf{M}} \right) = trace\left( {I_n } \right) - trace\left( {I_k } \right) = n - k. \end{equation*}\]
Esto implica que \[\begin{equation} E\left[ {\hat \varepsilon ^T \hat \varepsilon } \right] = \sigma ^2 trace\left( {\mathbf{M}} \right) = \left( {n - k} \right)\sigma ^2 \tag{2.39} \end{equation}\] Este último resultado es importante porque implica que el estimador MCO para la varianza de los errores es insesgado. En otras palabras: \[\begin{equation} E\left[ {s^2 } \right] = E\left[ {\frac{{\hat \varepsilon ^T \hat \varepsilon }} {{n - k}}} \right] = E\left[ {\frac{{\sum\limits_{i = 1}^n {\hat \varepsilon _i^2 } }} {{n - k}}} \right] = \sigma ^2 \tag{2.40} \end{equation}\]
Referencias
No incluyen una variable aleatoria.↩︎
Noten que si no existiera un término aleatorio en nuestro modelo, entonces estaríamos hablando de modelos determinísticos y no requeriríamos de métodos estadísticos para determinar los parámetros del modelo.↩︎
Para ver más justificaciones para la inclusión del término de error, el lector puede consultar Gujarati & Porter (2011).↩︎
Los parámetros corresponden a números (constantes) que describen la relación entre las variables independientes y la variable dependiente. Típicamente se expresan con letras griegas. Más adelante se ampliará esta idea.↩︎
A excepción de la varianza del término de error.↩︎
En el Apéndice de Álgebra Matricial (sección 14.7) se puede refrescar este concepto.↩︎
Una reparametrización es un cambio de nombre de variables y/o parámetros del problema que mantiene la naturaleza de la relación inalterada.↩︎
En caso que el modelo incluya un intercepto, cualquier componente determinístico del error es capturado por el intercepto.↩︎
El supuesto de que las variables explicativas son determinísticas es un supuesto que se puede levantar sin muchas implicaciones. Pero por simplicidad, emplearemos este supuesto a lo largo del libro, a menos que se exprese lo contrario.↩︎
Si el lector no se encuentra familiarizado o requiere un repaso con el lenguaje matricial y vectorial se recomienda revisar el Apéndice de álgebra matricial que se presenta en el Capítulo 14 al final del libro. Así mismo, en el Capítulo 15 se presenta una revisión de los conceptos estadísticos necesarios para comprender este libro.↩︎
En el anexo (ver sección 2.5) al final de este capítulo se presenta la derivación de ésta fórmula.↩︎
Una demostración de este resultado se presenta en el anexo (Ver sección 2.5 al final de este capítulo.↩︎
Noten que esto implica que contaremos con una serie de tiempo y por eso emplearemos el subíndice \(t\) en la formulación del modelo estadístico.↩︎
Esto corresponde a lo que se conoce en la industria como el Sell-in. Es decir, Sell-in se domina la venta del fabricante al canal distribuidor o minorista. El otro término asociado es el Sell-out que corresponde a las ventas que se hacen al consumidor final después de pasar por el canal de distribución. ↩︎
Por razones de confidencialidad, los datos han sido modificados de sus valores originales.↩︎
Para una introducción a este paquete se puede consultar Alonso & Largo (2023).↩︎
{Hay que anotar que la derivada es con respecto a un vector y no a un escalar.↩︎
Una matriz positiva semi-definida.↩︎