11 Autocorrelación
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras los efectos de la autocorrelación sobre los estimadores MCO.
- Realizar en R diferentes tipos de análisis gráficos que revelen la posibilidad de autocorrelación en los residuos.
- Efectuar las pruebas estadísticas necesarias para detectar la violación del supuesto de no autocorrelación en los residuos empleando R. En especial las pruebas de Rachas, Durbin Watson, Box-Pierce y de Ljung-Box.
- Corregir el problema de autocorrelación empleando estimadores consistentes para los errores estándar en R.
11.1 Introducción
En los dos capítulos anteriores hemos analizado las consecuencias de violar algunos de los supuestos del modelo de regresión. Analizamos las consecuencias de la violación del supuesto de independencia lineal entre variables explicativas en un modelo de regresión múltiple (Capítulo 8), posteriormente nos enfocamos en las consecuencias de un error homoscedástico (Capítulo 9).
Finalmente, y para concluir nuestra discusión de la violación de los supuestos que garantizan el cumplimiento del Teorema de Gauss-Markov nos concentraremos en los efectos que tiene la violación del supuesto de no autocorrelación (no existe relación entre los diferentes errores). Este supuesto garantiza la no presencia de un patrón predecible en el comportamiento de los errores. Cuando este supuesto es violado, lo cual ocurre comúnmente cuando trabajamos con datos de series de tiempo, se dice que los errores presentan autocorrelación (o correlación serial); en otras palabras, están relacionados entre sí.
Supuestos del modelo de regresión múltiple
En resumen, los supuestos del modelo de regresión múltiple son:
1 Relación lineal entre \(y\) y \({X_2},{X_3},...,{X_k}\)
2 \({X_2},{X_3}, \cdots,{X_k}\) son fijas y linealmente independientes (la matriz \(X\) tiene rango completo)
3 El vector de errores \({\bf {\varepsilon}}\) satisface:
- Media cero \(E\left[ {\bf {\varepsilon}} \right] = 0\)
- Varianza constante
- No autocorrelación.
Es decir, \(\varepsilon_i \sim i.i.d\left( {0,\sigma^2} \right)\) o \(\varepsilon_{n \times 1} \sim \left( \bf {0_{n \times 1}},\sigma^2{\bf {I_n}} \right)\).
Si existe autocorrelación entre los errores, entonces los estimadores MCO siguen siendo insesgados pero no son eficientes107.
Veamos más en detalle qué significa la autocorrelación. Y para simplificar, estudiemos inicialmente el caso más sencillo. Cuando existe una relación lineal “grande” entre las observaciones adyacentes, pero esta relación (lineal) tiende a desaparecer a medida que se consideran errores más lejanos. Formalmente tenemos: \[\begin{equation} {\bf{y}} = {\bf{X}}\beta + \varepsilon \tag{11.1} \end{equation}\] donde el término del error tiene media cero y se encuentra correlacionado con el error del periodo anterior108: \(E\left[ {{\varepsilon_t}} \right] = 0\); \({\varepsilon_t} = \rho {\varepsilon_{t - 1}} + {\nu_t}\quad \forall t\) con \(0 \le \left| \rho \right| < 1\) y \(Var\left( {{v_t}} \right) = \sigma_v^2\).
Este tipo de autocorrelación es conocido como un proceso auto-regresivo de orden uno o AR(1) para abreviar. Si seguimos asumiendo que la varianza de los errores es constante, entonces se puede probar fácilmente que: \[\begin{equation*} \sigma_\varepsilon ^2 = \frac{{\sigma_\nu ^2}}{{\left( {1 - {\rho ^2}} \right)}} \end{equation*}\] Por otro lado, dado que el valor esperado del error es cero se puede mostrar fácilmente que: \[\begin{equation*} Cov\left( {{\varepsilon_t},{\varepsilon_{t - 1}}} \right) = \rho \sigma_\varepsilon ^2 \end{equation*}\] Entonces, la correlación entre los errores adyacentes109 será: \[\begin{equation*} \frac{{Cov\left( {{\varepsilon_t},{\varepsilon_{t - 1}}} \right)}}{{\sqrt {Var\left( {{\varepsilon_t}} \right)Var\left( {{\varepsilon_{t - 1}}} \right)} }} = \frac{{Cov\left( {{\varepsilon_t},{\varepsilon_{t - 1}}} \right)}}{{\sigma_\varepsilon ^2}} = \rho \end{equation*}\] Similarmente es relativamente sencillo demostrar que: \[\begin{equation*} Cov\left( {{\varepsilon_t},{\varepsilon_{t - 2}}} \right) = {\rho ^2}\sigma_\varepsilon ^2 \end{equation*}\] \[\begin{equation*} Cov\left( {{\varepsilon_t},{\varepsilon_{t - 3}}} \right) = {\rho ^3}\sigma_\varepsilon ^2 \end{equation*}\] En términos generales tenemos que en este caso de errores con un proceso AR(1) la autocorrelación para diferentes rezagos está dada por110: \[\begin{equation*} \rho \left( s \right) = {\rho ^s}\sigma_\varepsilon^2 \end{equation*}\] Es decir, en el caso de un proceso AR(1) a medida que se alejan en el tiempo las observaciones (se consideran más rezagos) la correlación entre los errores es menor. Esto lo podemos observar en los ejemplos de las Secciones 11.1.1 y 11.2. El ejemplo de la sección 11.2.1 muestra la situación cuando no existiese un problema de autocorrelación, la autocorrelación para los diferentes rezagos será cero.
11.1.1 Ejemplo: Errores con un proceso AR(1) y autocorrelación positiva
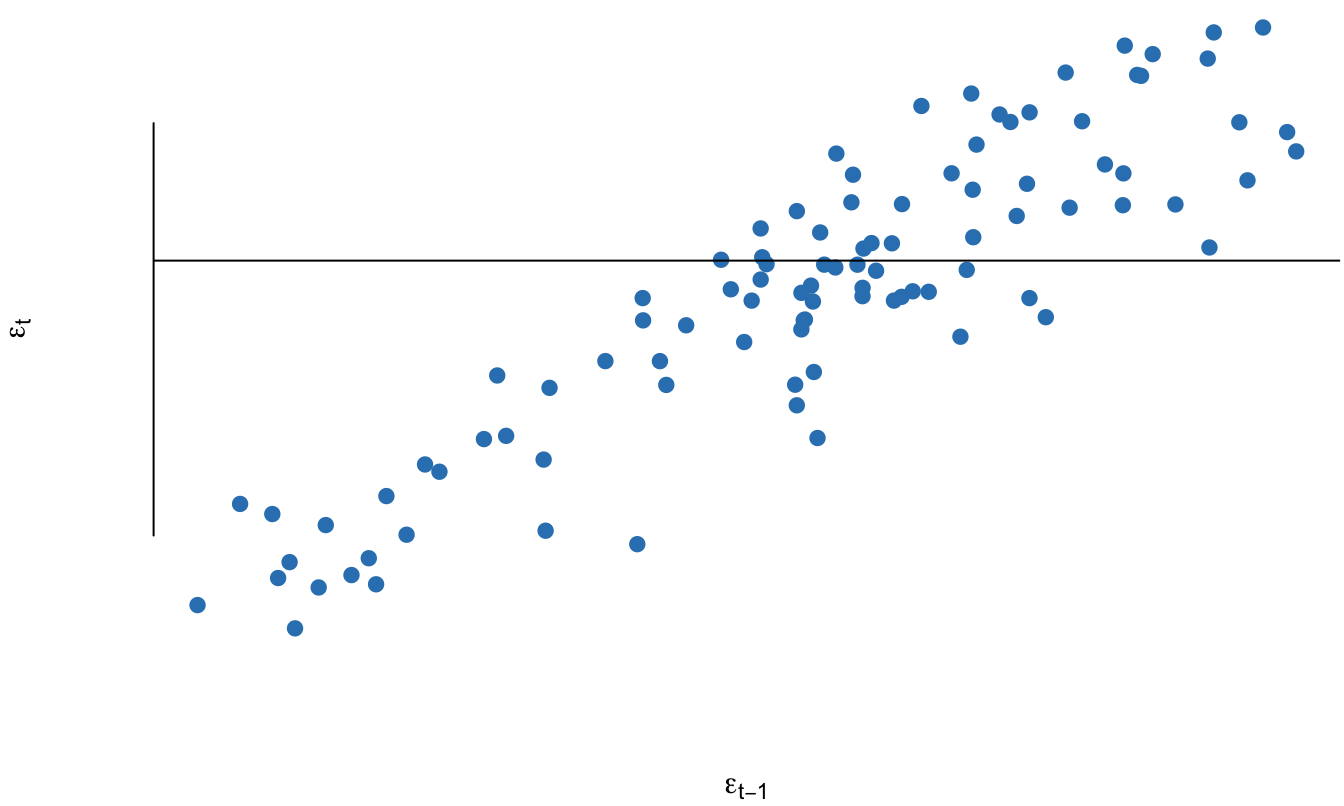
En la Figura 11.1 se presenta un error cuya autocorrelación es de 0.8 (\(\rho = 0.8\)). Noten que para un periodo \(t\) los errores tienden a mantener el signo del error del periodo anterior (\(t-1\)). Esto se puede ver de mejor manera si se visualizan los errores del periodo t (\(\varepsilon_t\)) en función de los del periodo anterior (\(\varepsilon_{t-1}\)) como se presenta en la Figura 11.2. Se observa una relación lineal muy fuerte entre los errores.
Figura 11.1: Comportamiento en el tiempo del error simulado de un proceso AR(1) con \(\rho = 0.8\)
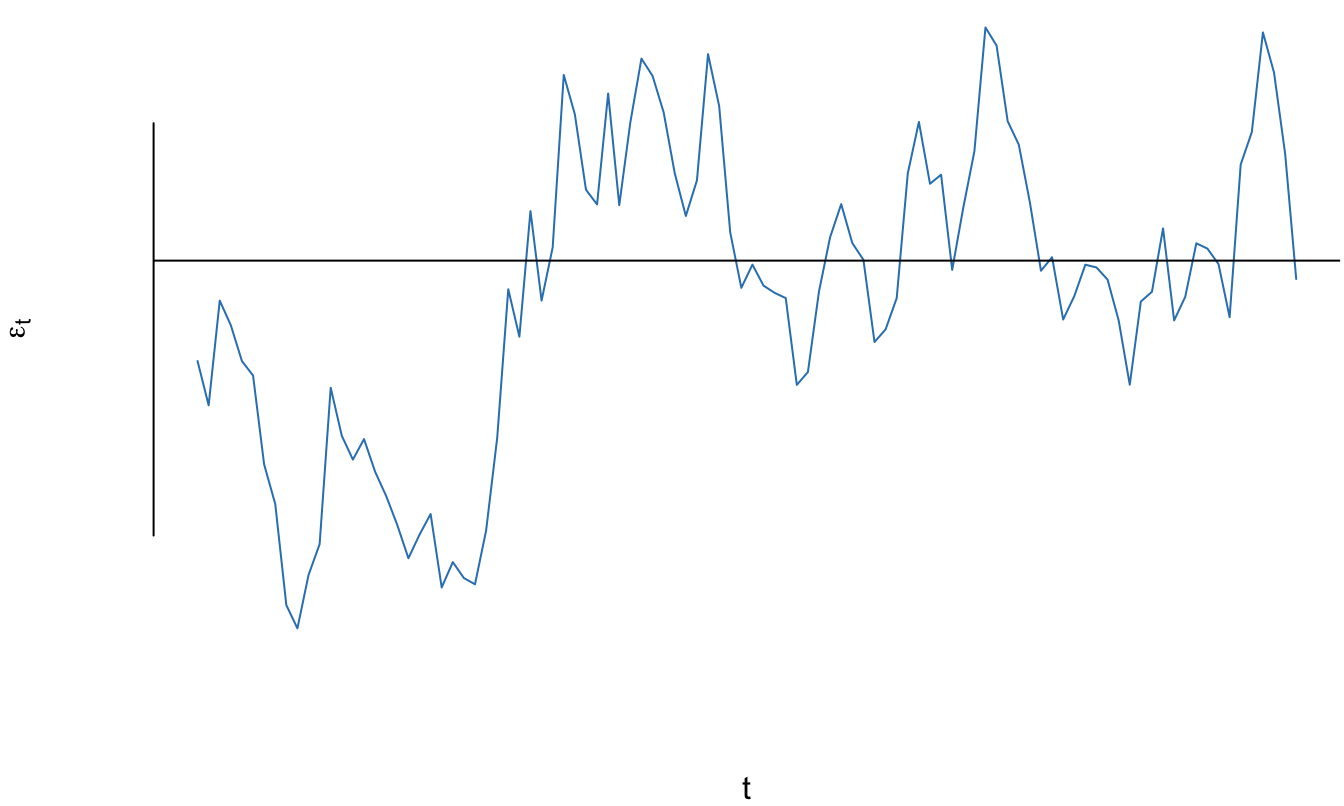
Figura 11.2: Error simulado para el periodo \(t\) versus el mismo error en el periodo anterior (error simulado de un proceso AR(1) con \(\rho = 0.8\))
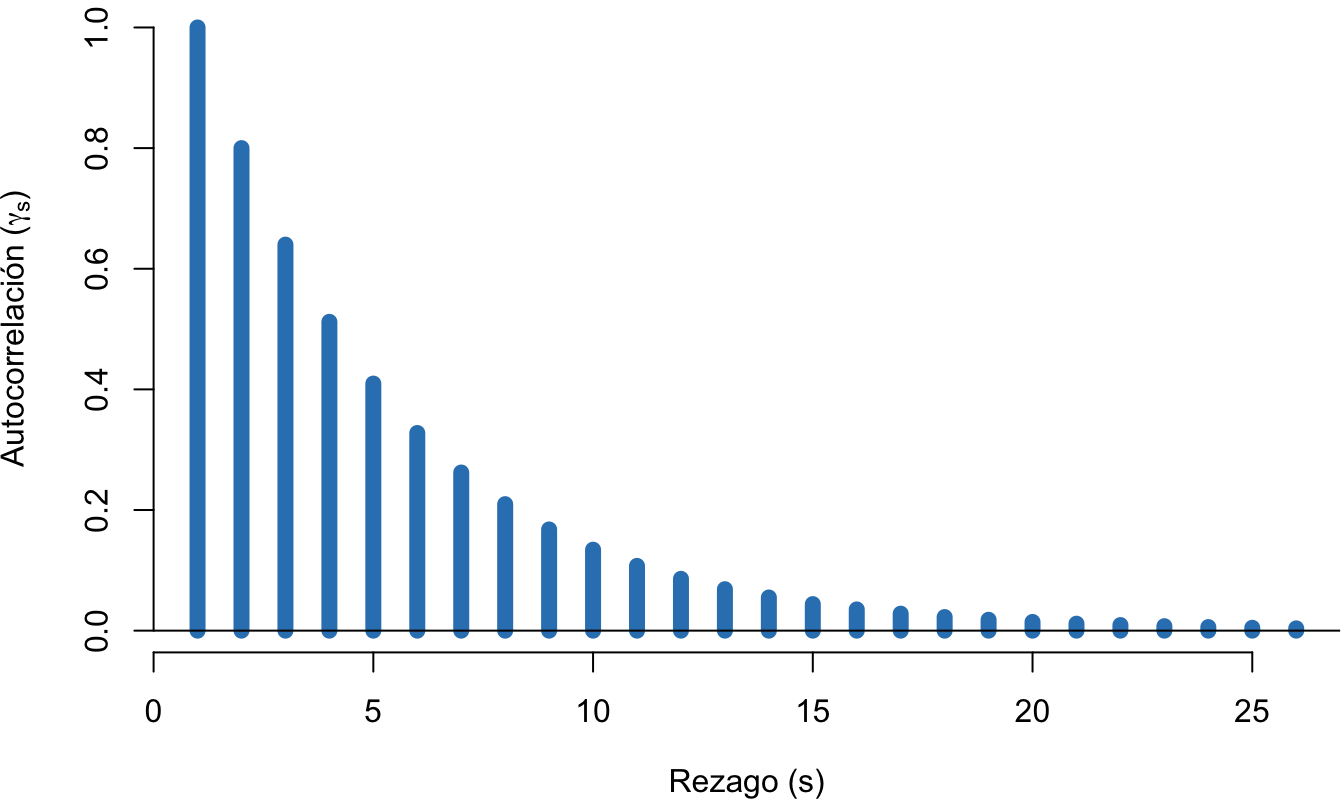
Adicionalmente, podemos observar en la Figura 11.3 la autocorrelación para estos errores para diferentes rezagos. Este gráfico muestra como para errores autocorrelacionados con un proceso AR(1) y con un \(\rho = 0.8\) la correlación entre las observaciones se hace menos fuerte entre más alejados estén.
Figura 11.3: Comportamiento de la autocorrelación para diferentes rezagos del error simulado de un proceso AR(1) con \(\rho = 0.8\)
En general, cuando un error de un modelo sigue un proceso AR(1) y \(0 < \rho < 1\) diremos que el modelo tiene Autocorrelación positiva. En este caso, los errores de períodos adyacentes tienden a tener el mismo signo y esto implicará obtener gráficos similares a los observados en las Figuras 11.1 y 11.2.
11.2 Ejemplo: Errores con un proceso AR(1) y autocorrelación negativa
En la Figura 11.4 se presenta un error cuya autocorrelación es de -0.8 (\(\rho = -0.8\)). Noten que a diferencia del ejemplo anterior, para un periodo \(t\) los errores tienden a cambiar el signo observado en el periodo anterior (\(t-1\)). Esto se puede ver de mejor manera si se visualizan los errores del periodo t (\(\varepsilon_t\)) en función de los del periodo anterior (\(\varepsilon_{t-1}\)) como se presenta en la Figura 11.5. Se observa una relación lineal muy fuerte entre los errores, pero con pendiente negativa.
Figura 11.4: Comportamiento en el tiempo del error simulado de un proceso AR(1) con \(\rho = -0.8\)
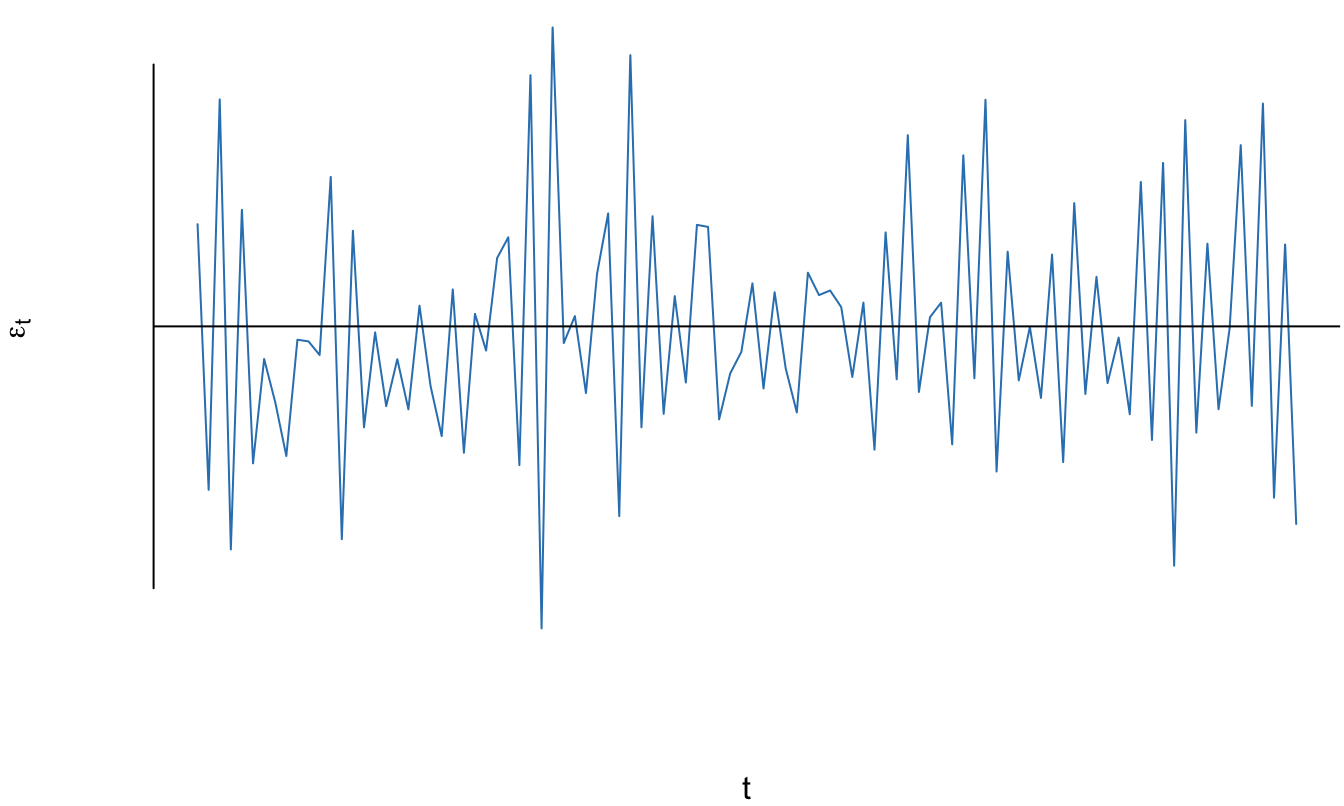
Figura 11.5: Comportamiento en el tiempo del error simulado de un proceso AR(1) con \(\rho = -0.8\)
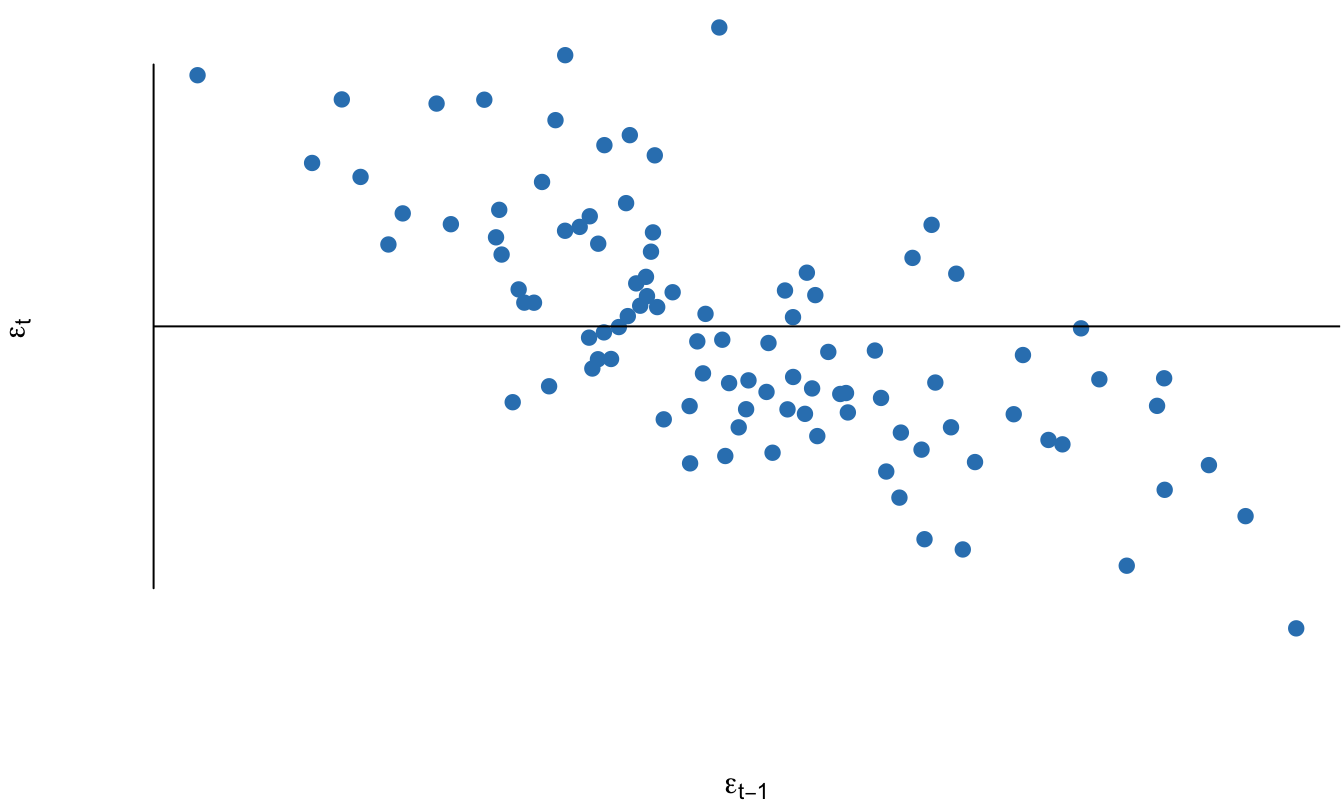
Adicionalmente, podemos observar en la Figura 11.6 la autorrelación para estos errores para diferentes rezagos. Este gráfico muestra como para errores autocorrelacionados con un proceso AR(1) y con un \(\rho = -0.8\) la correlación entre las observaciones se hace menos fuerte entre más alejados estén, pero la correlación tiene signo contrario.
Figura 11.6: Error simulado para el periodo t versus el mismo error en el periodo anterior (error simulado de un proceso AR(1) con \(\rho = -0.8\)

En general, cuando un error de un modelo sigue un proceso AR(1) y \(-1< \rho < 0\) diremos que el modelo tiene Autocorrelación negativa. En este caso, los errores de períodos adyacentes tienden a tener signo contrario y esto implicará obtener gráficos similares a los observados en las Figuras 11.4 y 11.5.
11.2.1 Ejemplo: Errores sin autocorrelación
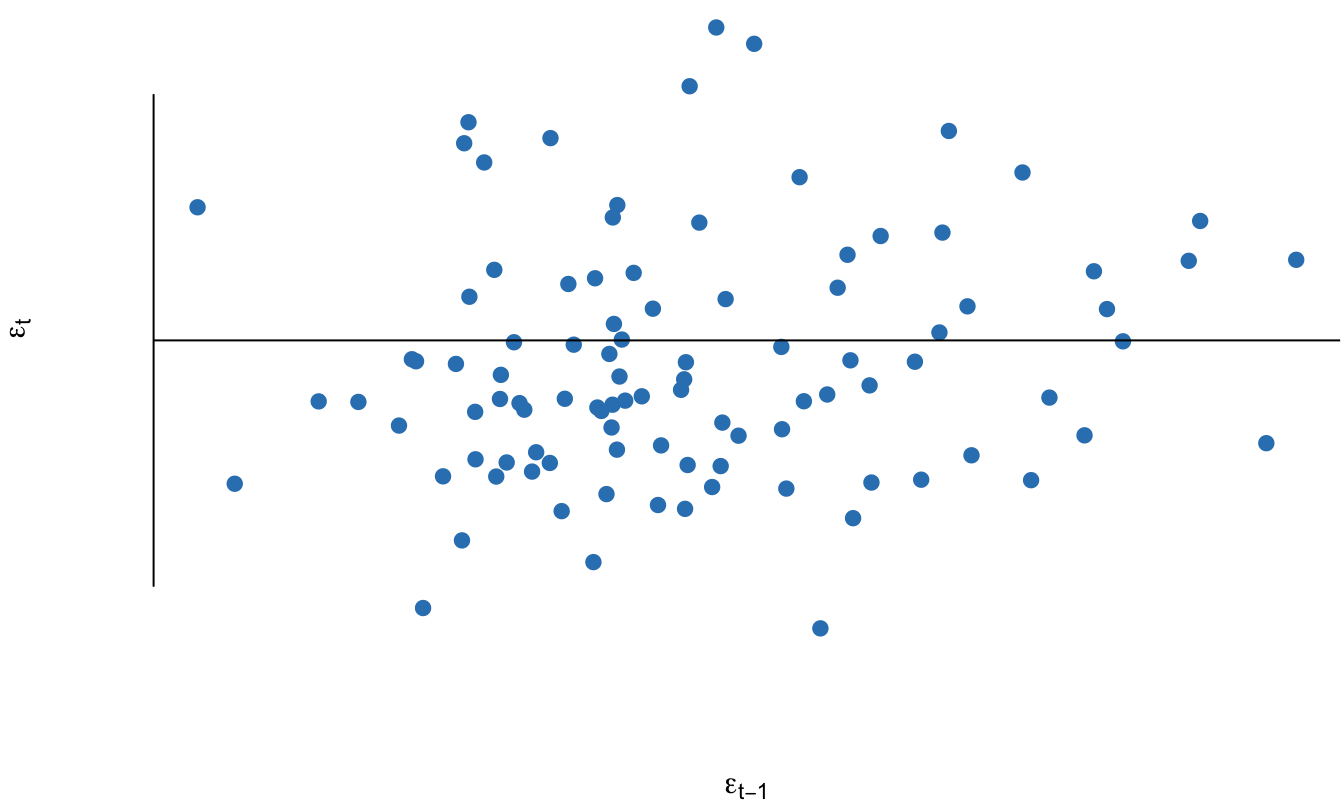
En la Figura 11.7 se presenta un error sin autocorrelación (\(\rho = 0\)). En este caso el patrón de los residuales es totalmente aleatorio. Al visualizar los errores del periodo t (\(\varepsilon_t\)) en función de los del periodo anterior (\(\varepsilon_{t-1}\)) no se observa ningún patrón (Ver Figura 11.8). Tampoco existirán autocorrelaciones y por eso no las graficaremos.
Figura 11.7: Comportamiento en el tiempo del error simulado sin autocorrelación

Figura 11.8: Error simulado no autocorrelacionado para el periodo \(t\) versus el mismo error en el periodo anterior (\(t-1\))
11.3 Formalmente
Regresando al problema de autocorrelación, este problema puede ser causado porque las relaciones entre las variables pueden ser dinámicas. Es decir, todo el ajuste entre las variables no se hace en un mismo período. La autocorrelación también se puede deber a que la información no está disponible instantáneamente y por tanto, la variable dependiente puede depender de errores previos. Por ejemplo, la información de las utilidades no se encuentra disponible sino después de varios períodos, y los individuos tendrán que esperar unos periodos para ajustar sus decisiones. En general, la autocorrelación es un problema muy común en modelos que emplean series de tiempo.
Es poco probable que exista autocorrelación en datos de corte transversal, pero de existirlo es muy fácil de eliminarlo. Simplemente podríamos reorganizar las observaciones para eliminar la relación entre las observaciones adyacentes. Por otro lado, esto es imposible en el caso de una muestra de serie de tiempo, pues el orden de las observaciones es importante en las series de tiempo y no se puede modificar.
La autocorrelación entre los errores puede tomar muchas formas. En general, se dirá que los errores siguen un proceso autorregresivo de orden \(p\) (\(AR(p)\)) cuando el error depende de los \(p\) períodos anteriores. Por ejemplo, si el término de error tiene el siguiente comportamiento \({\varepsilon_t} = {\rho _1}{\varepsilon_{t - 1}} + {\rho _2}{\varepsilon_{t - 2}} + {\nu_t}\) \((\forall t)\), entonces se dirá que el error es auto-regresivo de orden 2 (\(AR(2)\)). Si el comportamiento es \({\varepsilon_t} = {\rho _1}{\varepsilon_{t - 1}} + {\rho _2}{\varepsilon_{t - 2}} + {\rho _3}{\varepsilon_{t - 3}} + {\nu_t}\), entonces los errores seguirán un proceso \(AR(3)\). En general, si el comportamiento del error es \({\varepsilon_t} = {\rho _1}{\varepsilon_{t - 1}} + {\rho _2}{\varepsilon_{t - 2}} + {\rho _3}{\varepsilon_{t - 3}} + \cdots {\rho _p}{\varepsilon_{t - p}} + {\nu_t}\) entonces el error sigue un proceso AR(p).
Matricialmente, la presencia de autocorrelación implica que la matriz de varianzas y covarianzas del término de error no es \({\sigma ^2}{I_n}\), sino una matriz cuadrada con la misma constante sobre la diagonal (dado que hay homoscedasticidad) pero por fuera de la diagonal ya no se tienen ceros. Por ejemplo, en el caso de un error que sigue un proceso \(AR(1)\) la siguiente matriz de varianzas y covarianzas de los errores será: \[\begin{equation*} E\left[ {{\varepsilon ^T}\varepsilon } \right] = \Omega = \sigma_\varepsilon ^2\left[ {\begin{array}{*{20}{c}} 1 & \rho & {{\rho ^2}} & \cdots & {{\rho ^{n - 1}}} \\ \rho & 1 & \rho & \cdots & {{\rho ^{n - 2}}} \\ {{\rho ^2}} & \rho & 1 & \cdots & {{\rho ^{n - 3}}} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ {{\rho ^{n - 1}}} & {{\rho ^{n - 2}}} & {{\rho ^{n - 3}}} & \rho & 1 \\ \end{array}} \right] \ne {\sigma ^2}{I_n} \end{equation*}\]
Como se mencionó anteriormente, en presencia de autocorrelación los estimadores MCO continúan siendo insesgados pero no tienen la mínima varianza posible111. Es más, en presencia de autocorrelación, el estimador MCO de la matriz de varianzas y covarianzas del vector \(\beta\) será sesgado112. Por lo tanto, si usamos este último estimador en pruebas de hipótesis (individuales o conjuntas) o intervalos de confianza para los coeficientes estimados, entonces obtendremos conclusiones erróneas en torno a los verdaderos \(\beta\)s.
11.4 Pruebas para la detección de autocorrelación
En el análisis tradicional el primer paso, antes de realizar pruebas estadísticas formales, es verificar gráficamente si los residuales presentan síntomas de la presencia del problema. No obstante, así como en el caso de los dos problemas anteriormente estudiados, es posible que el científico de datos se enfrente a tener que estimar muchos modelos de manera automática y, por tanto, no tenga sentido realizar un análisis preliminar gráfico.
Los síntomas de autocorrelación en una regresión se pueden observar en el vector de errores. Pero dicho vector no es observable, por tanto la mejor aproximación es examinar los errores estimados. Las gráficas más empleadas son:
Los errores contra el tiempo \(\hat \varepsilon\) vs \(t = 1,2,...n\). Como por ejemplo las Figuras 11.1, 11.4 y 11.7.
Los errores contra los errores del periodo anterior \(\hat \varepsilon_t\) vs \(\hat \varepsilon_{t - 1}\). Como por ejemplo las Figuras 11.2, 11.5 y 11.8.
Estos gráficos permiten identificar algún tipo de regularidad como los que se presentan en el ejemplo de la Sección 11.1.1. Por un lado, en los dos primeros gráficos se observa el comportamiento típico de errores con un proceso \(AR(1)\) y con autocorrelación positiva, observamos que el signo de los residuos persiste en periodos prolongados de tiempo. Por otro lado, en el caso de presencia de autocorrelación negativa sucede lo contrario (ver ejemplo en la sección 11.2), ya que el signo de los residuos cambia de un periodo a otro. Si no existe autocorrelación, en estos gráficos (Ver ejemplo en la Sección 11.2.1) no podremos observar patrón claro de comportamiento en el signo de los residuales y en su relación con valores pasados.
Así como en el caso de la heteroscedasticidad, el análisis gráfico es un análisis informal que nos permite intuir la presencia del problema; sin embargo, para un análisis más formal existen diferentes pruebas para identificar la autocorrelación. El científico de datos tendrá que decidir si este tipo de análisis gráfico agrega o no valor al análisis y la presentación de resultados que está realizando para cada pregunta de negocio en particular.
11.4.1 Prueba de Rachas (Runs test)
La prueba de rachas (o Runs test en inglés), propuesta por Wald & Wolfowitz (1940), es una prueba de independencia lineal no paramétrica cuya idea es relativamente sencilla. Si no hay autocorrelación, entonces no deberían observarse muchos errores seguidos con el mismo signo (autocorrelación positiva), ni tampoco muchos cambios de signo seguido (autocorrelación negativa). En otras palabras, debe existir la cantidad adecuada de cambios de signo en una serie de datos: ni muchos, ni pocos.
Esta prueba tiene además la ventaja de no necesitar suponer una distribución de los errores. Para probar la hipótesis nula de que los errores son totalmente aleatorios (\(H_0:\rho = 0\)) versus la alterna de que existe algún tipo de autocorrelación en los errores, se requiere seguir los siguientes pasos a partir de los errores estimados:
- Contar el número de errores con signo positivo (\(N_+\)) y con signo (\(N_-\))
- Contar el número rachas (k), es decir de “seguidillas” de signo. Por ejemplo, si tenemos que los signos de los errores son: - - - - - + + + - +++ - ++. Entonces se tendrán seis rachas (k =6). (- - - - -)(+ + +)(-)(+++)(-)(++). Note que el número de rachas es igual al número de cambios de signo.
- Finalmente, se toma la decisión de rechazar la hipótesis nula o no empleando el correspondiente valor p que calcularemos en R113.
11.4.2 Prueba de Durbin-Watson
Durbin & Watson (1951) diseñaron una prueba de autocorrelación con gran poder para detectar errores con autocorrelación de primer orden. Esta prueba se ha convertido en la más común para detectar este problema por ser relativamente intuitiva. Los autores definen el siguiente estadístico de prueba a partir de los errores estimados:
\[\begin{equation*} DW = \frac{{\sum\limits_{t = 2}^n {\left( {\hat \varepsilon_t - \hat \varepsilon_{t - 1} } \right)^2 } }}{{\hat \varepsilon ^T \hat \varepsilon }} \end{equation*}\]
Si la muestra es lo suficientemente grande es posible demostrar que \(DW \approx 2\left( {1 - \hat \rho } \right)\). De esta expresión se puede deducir que este estadístico estará acotado entre cero y 4 (\(0 \le DW \le 4\)). De hecho, como se muestra en el Cuadro 11.1, intuitivamente se puede conocer el tipo de problema presente en la regresión a partir del valor del estadístico \(DW\). Naturalmente, será necesario efectuar una prueba formal para determinar con mayor certeza si existe o no autocorrelación.
| Tipo de problema | \(\rho\) | \(\hat \rho\) | valor aproximado del \(DW\) |
|---|---|---|---|
| No correlación | \(\rho = 0\) | \(\hat \rho \approx 0\) | \(DW \approx 2\) |
| Correlación positiva | 1 > \(\rho\) > 0 | 1 >\(\hat \rho\) > 0 | \(DW\) < 2 |
| Correlación negativa | -1 < \(\rho\) < 0 | -1 < \(\hat \rho\) < 0 | \(DW\) > 2 |
| Fuente: elaboración propia. |
Naturalmente la regla que se presenta en el Cuadro 11.1 es únicamente intuitiva. Para tener una decisión con mayor grado de certidumbre se deberá efectuar una prueba de hipótesis.
El estadístico \(DW\) nos permite contrastar tres diferentes hipótesis nulas, como se reportan en el Cuadro 11.2.
| Hipótesis nula (\(H_0\)) | \(H_0\) en términos de \(\rho\) | Hipótesis alterna (\(H_A\)) |
|---|---|---|
| No autocorrelación | \(\rho = 0\) | \(\rho \ne 0\) |
| No autocorrelación Positiva | 0 < \(\rho\) < 1 | \(\rho\) > 0 |
| No autocorrelación Negativa | -1 < \(\rho\) < 0 | \(\rho\) < 0 |
| Fuente: elaboración propia. |
Durbin & Watson (1951) encontraron la distribución de su estadístico DW y la tabularon. Tradicionalmente se empleaba una tabla para poder tomar la decisión de rechazar o no la hipótesis nula de no autocorrelación. En la actualidad, es más común que la decisión se tome empleando un valor p como lo discutiremos más adelante.
Sobre esta prueba es importante destacar varios aspectos:
- El \(DW\) no tiene sentido si no hay intercepto (Ver Durbin & Watson (1951)).
- El \(DW\) depende del supuesto que las X’s sean no estocásticas (Ver Durbin & Watson (1951)).
- La prueba tiene un mayor poder ante procesos AR(1).
- Esta prueba tampoco aplica en los casos en que existen variables dependientes rezagadas en la derecha del modelo; por ejemplo, para el modelo \({Y_t} = {\beta_0} + {\beta_1}{X_t} + {\beta_2}{Y_{t - 1}} + {\varepsilon_t}\) este estadístico no aplica.
11.4.3 Prueba h de Durbin
Como se mencionó anteriormente, si el modelo emplea la variable dependiente rezagada como explicativa, la prueba de Durbin-Watson no aplica. Para solucionar este problema Durbin (1970) sugirió el siguiente estadístico: \[\begin{equation*} h = \hat \rho \sqrt {\frac{n}{1 - n \left( {\widehat{Var\left( {\hat \alpha } \right)}} \right)}} \end{equation*}\] donde: \[\begin{equation*} Y_t = \beta_0 + \beta_1 X_{1i} + ... + \beta_k X_{ki} + \alpha Y_{t - 1} + \varepsilon_t \end{equation*}\] Por lo tanto, es relativamente sencillo demostrar que: \[\begin{equation} h = \left( {1 - \frac{{DW}}{2}} \right)\sqrt {\frac{n}{{1 - n\left( \widehat{Var\left( {\hat \alpha } \right)} \right)}}} \tag{11.2} \end{equation}\]
Durbin (1970) demostró que este estadístico de prueba sigue una distribución estándar normal (\(h \sim N\left( {0,1} \right)\)) y, por lo tanto, si se cumple que \(\left| h \right| > z_\frac{\alpha }{2}\) entonces es posible rechazar \(H_0: \rho = 0\) a favor de la \(H_A : \rho \ne 0\). Finalmente, como podemos apreciar en la ecuación (11.2), esta prueba no es válida en los casos en que \(n\left( \widehat{ Var\left( \hat \alpha \right)} \right) \ge 1\).
11.4.4 Prueba de Box-Pierce y Ljung-Box
Otra aproximación para comprobar la existencia o no de autocorrelación es determinar si las autocorrelaciones a diferentes rezagos son o no iguales a cero114. Box & Pierce (1970) diseñan una prueba basada en la autocorrelación muestral de los errores que permite detectar la existencia de errores con procesos más persistentes que AR(1). Recordemos que la autocorrelación poblacional se define de la siguiente forma: \[\begin{equation*} {\gamma _j} = \frac{{Cov({\varepsilon_t},{\varepsilon_{t - j}})}}{{\sqrt {Var\left( {{\varepsilon_t}} \right)Var\left( {{\varepsilon_{t - j}}} \right)} }} = \frac{{Cov({\varepsilon_t},{\varepsilon_{t - j}})}}{{\sigma_\varepsilon ^2}} \end{equation*}\] Y la correspondiente autocorrelación muestral es: \[\begin{equation*} {\hat \gamma _j} = \frac{{\sum\limits_{t = k + 1}^n {\left( {{{\hat \varepsilon }_t} - \bar \varepsilon } \right)\left( {{{\hat \varepsilon }_{t - j}} - \bar \varepsilon } \right)} }}{{\sum\limits_{t = 1}^n {{{\left( {{{\hat \varepsilon }_t} - \bar \varepsilon } \right)}^2}} }} = \frac{{\sum\limits_{t = j + 1}^n {{{\hat \varepsilon }_t}{{\hat \varepsilon }_{t - j}}} }}{{\sum\limits_{t = 1}^n {{{\left( {{{\hat \varepsilon }_t}} \right)}^2}} }} \end{equation*}\]
Box & Pierce (1970) definen una prueba que permite determinar si las primeras \(s\) autocorrelaciones son conjuntamente iguales a cero o no. Es decir, permite comprobar la hipótesis nula de un error no autocorrelacionado (las correlaciones en los primeros \(s\) rezagos son cero), versus la hipótesis alterna de la existencia de algún tipo de autocorrelación (por lo menos una autocorrelación no es cero). Para comprobar esta hipótesis nula, Box & Pierce (1970) sugieren el estadístico \(Q\): \[\begin{equation*} Q = n\sum\limits_{j = 1}^s {r_k^2} { \sim _a}\chi _s^2 \end{equation*}\] donde \(s\) corresponde al número de rezagos que se desean considerar dentro de la prueba. Ellos demuestran que su estadístico sigue una distribución Chi-cuadrado con \(s\) grados de libertad (\(\chi _s^2\)). Por lo tanto, será posible rechazar la \(H_0\) (error no autocorrelacionado) si se cumple que \(Q > \chi _s^2\).
Sin embargo, la prueba de Box-Pierce sólo es válida para muestras grandes (\(n>20\)), para resolver este inconveniente Ljung & Box (1979) proponen una modificación del estadístico anterior para que presente un mejor comportamiento en muestras pequeñas. El estadístico de Ljung-Box corresponde a: \[\begin{equation*} Q' = n\left( {n + 2} \right)\sum\limits_{k = 1}^s {\frac{{r_j^2}}{{n + j}}} \end{equation*}\] Este estadístico funciona y posee la misma distribución que el de la prueba de Box-Pierce.
Finalmente, es importante mencionar que una práctica muy común es realizar esta prueba para un número relativamente grande de rezagos. Es decir, hacer las correspondientes pruebas para diferentes rezagos; por ejemplo, se calculan los correspondientes estadísticos para comprobar las siguientes hipótesis alternas:
\[\begin{align*} H_0:\gamma_1 = &0\\ H_0:\gamma_1 = &\gamma_2 = 0 \\ \vdots &\\ H_0:\gamma_1 =& \gamma_2= \cdots =\gamma_n =0 \end{align*}\]
La decisión de si los errores están o no autocorrelacionados se toma teniendo en cuenta las decisiones de cada una de estas pruebas.
11.4.5 Prueba de Breusch-Godfrey
Breusch (1978) y Godfrey (1978) diseñaron una prueba que permite comprobar la hipótesis nula de no autocorrelación versus la alterna de que el error sigue un proceso auto-regresivo de orden \(p\). Esta prueba también es conocida como la prueba del multiplicador de Lagrange o prueba \(LM\) (por su sigla en inglés: Lagrange Multiplier Test).
Esta prueba se basa en una idea muy sencilla. Si existe autocorrelación en los errores, entonces estos son explicados por sus valores pasados, pero si no hay autocorrelación entonces los valores pasados de los errores no pueden explicar el comportamiento actual del error.
Así, para probar la hipótesis nula de no autocorrelación versus la alterna de unos errores con un proceso \(AR(s)\), se pueden emplear los residuos estimados de la regresión bajo estudio para comprobar si los valores pasados del error sirven o no para explicar el error del periodo \(t\). Es decir, la prueba \(LM\) implica los siguientes pasos:
- Estimar el modelo de regresión original: \[\begin{equation*} {y_t} = {\beta_1} + {\beta_2}{X_{2,t}} + {\beta_3}{X_{3,t}} + \ldots + {\beta_k}{X_{k,t}} + {\varepsilon_t} \end{equation*}\] y obtener la serie de los errores estimados (\({\hat \varepsilon_t}\)).
- Estimar la siguiente regresión auxiliar: \[\begin{equation*} {\hat \varepsilon_t} = {\alpha _1} + {\alpha _2}{X_{2,t}} + {\alpha _3}{X_{3,t}} + \ldots + {\alpha _k}{X_{k,t}} + {\omega _1}{\hat \varepsilon_{t - 1}} + {\omega _2}{\hat \varepsilon_{t - 2}} + \ldots + {\omega _s}{\hat \varepsilon_{t - s}} + {\xi_t} \end{equation*}\]
- Empleando el \(R^2\) de la regresión auxiliar calcular el estadístico LM de la siguiente manera115: \[\begin{equation*} LM = \left( {n - s} \right) \times {R^2} \end{equation*}\]
- Comparar el estadístico \(LM\) con el valor crítico de la distribución Chi-cuadrado con \(s\) grados de libertad. Se rechazará la hipótesis nula si \(LM > \chi _{s,\alpha }^2\).
Al igual que la prueba de Box-Pierce, cuando se emplea esta prueba normalmente se realizan las pruebas para diferentes hipótesis nulas y se toma la decisión basándose en el conjunto de los resultados.
11.5 Solución a la autocorrelación
Así como en el caso de la heteroscedasticidad (Ver Capítulo 9), existen dos formas de solucionar la existencia de autocorrelación. La primera solución es tratar de resolver de raíz el problema modificando la muestra. Este método se conoce como el Método de Diferencias Generalizadas que hace parte de la familia de los Mínimos Cuadrados Generalizados (MCG). Esta aproximación implica conocer exactamente cómo es la autocorrelación; algo que típicamente es difícil para el científico de datos. Una breve introducción a este método se presenta en el anexo al final del capítulo (Ver sección 11.8).
La segunda opción implica solucionar los síntomas de la autocorrelación, tratando de estimar de manera consistente la matriz de varianza y covarianzas de los coeficientes estimados. Esto permite corregir los errores estándar de los coeficientes, y de esta manera los t calculados serán recalculados y, por tanto, los valores p serán diferentes. Una aproximación muy similar a la de White para solucionar el problema de heteroscedasticidad.
11.5.1 Estimación Consistente en presencia de Autocorrelación de los errores estándar.
De manera similar a la solución de White (1980) para la heteroscedasticidad, Newey & West (1987) sugieren un estimador para la matriz de varianzas y covarianzas.
Recordemos, que en presencia de perturbaciones no esféricas116 tendremos que: \[\begin{equation*} \Psi = Var\left[ {{\hat \beta}\left| {\bf{X}} \right.} \right] = {\left( {{{\bf{X}}^T}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^T}\Omega {\bf{X}}{\left( {{{\bf{X}}^T}{\bf{X}}} \right)^{ - 1}} \end{equation*}\] Esto se puede reescribir como: \[\begin{equation*} \Psi = {\left( {\frac{1}{n}{{\bf{X}}^T}{\bf{X}}} \right)^{ - 1}}\frac{1}{n}\Phi {\left( {\frac{1}{n}{{\bf{X}}^T}{\bf{X}}} \right)^{ - 1}} \end{equation*}\] donde, \[\begin{equation*} \Phi = \frac{1}{n}{{\bf{X}}^T}\Omega {\bf{X}} \end{equation*}\] Y eso se puede escribir de la siguiente manera: \[\begin{equation*} \hat \Phi = \frac{1}{n}\sum\limits_{i,j = 1}^n {{w_{\left| {i - j} \right|}}{{{\bf{\hat V}}}_i}{\bf{\hat V}}_j^T} \end{equation*}\] donde \(w = {\left[ {\begin{array}{*{20}{c}} {{w_0}}& \ldots &{{w_{n - 1}}} \end{array}} \right]^T}\) corresponde a un vector de pesos.
Newey-West (1987) sugieren: \[\begin{equation*} {w_\ell } = 1 - \frac{\ell }{{L + 1}} \end{equation*}\] donde \(L\) corresponde al número máximo de rezagos. Generalmente \(L \approx N^{1/4}\).
Este estimador se caracteriza por ser consistente; es decir, ser sesgado en muestras pequeñas, pero esto desaparece cuando la muestra se vuelve grande. Por eso este estimador es conocido como estimador H.A.C. (heteroskedasticity and autocorrelation consistent). De manera similar a lo discutido para el caso de los H.C., estos estimadores no hacen que los MCO se conviertan nuevamente en MELI. La varianza del estimador MCO sigue siendo más grande que por ejemplo los del estimador GLS.
De manera similar al caso de la heteroscedasticidad, el estimador de Newey-West genera varianzas de los estimadores que son relativamente más pequeñas y, por tanto, los t calculados son más grandes. Es decir, los t calculados y los correspondientes valores p deben ser corregidos.
En otras palabras, debemos modificar nuestras pruebas individuales y conjuntas empleando la correspondiente matriz H.A.C.. Por ejemplo, la prueba de Wald para una restricción de la forma \({\mathbf{R}}\beta = {\mathbf{q}}\) será: \[\begin{equation*} W = \left( \mathbf{R} \hat \beta \right)^T \left[ \mathbf{R} \left( \text{Est} \text{.Asy} \text{.} Var \left[ \hat \beta \right] \right) \mathbf{R}^T \right]^{ - 1} \left( \mathbf{R}\hat \beta \right) \end{equation*}\]
Por otro lado, así como en el caso de la corrección H.A.C. diversos autores han intentado mejorar la aproximación provista por Newey-West:
- Andrews (1991) sugiere: \({w_\ell } = \frac{3}{{{z^2}}}\left( {\frac{{\sin \left( z \right)}}{z} - \cos \left( z \right)} \right)\), donde \(z = {6\pi }/ 5 \cdot {\ell / B}\). Esta aproximación es conocida como H.A.C de kernel.
- Lumley y Heagerty (1999) sugieren otra forma de pesar los datos que es conocida como la aproximación H.A.C de weave.
Las dos últimas aproximaciones son las más usadas en la actualidad. Pero existe poca documentación de cuándo es mejor uno u otro caso. Esto es aún materia de investigación.
Finalmente, es importante anotar que otra forma común para solucionar el problema de autocorrelación en una regresión es emplear la variable dependiente como variable explicativa, pero rezagada unos periodos. Es decir, de encontrar autocorrelación se acostumbra incluir la variable y rezagada \(y_{t-1}\) como variable explicativa117. Esto implica probar nuevamente si existe o no autocorrelación en los nuevos residuales. Si el problema de autocorrelación persiste, se sigue incluyendo la variable dependiente rezagada más periodos hasta que el problema de autocorrelación desaparezca. Esta aproximación implica diferentes iteraciones y estar probando la autocorrelación en cada paso.
En la actualidad los científicos de datos prefieren la aproximación de emplear H.A.C para hacer analítica diagnóstica. Si se desea hacer analítica predictiva para hacer proyecciones es más común emplear técnicas de series de tiempo que emplean esta lógica de incluir las autocorrelaciones como los modelos ARIMA o ARIMAX. Estas técnicas no las cubriremos en este libro pero pueden consultar Alonso & Hoyos (2024) para una introducción a los métodos de proyección.
11.6 Práctica en R: Explicando los rendimientos de una acción (continuación)
En el Capítulo 3 construimos un modelo para responder una pregunta de negocio que tenían en el área financiera de una organización. La pregunta era ¿Cómo está relacionado el rendimiento de la acción grupo SURA con el rendimiento de aquellas acciones en la que ya tenemos inversiones? Las acciones que ya se tenían en el portafolio eran: ECOPETROL, NUTRESA, ÉXITO, ISA, GRUPOAVAL, CONCONCRETO, VALOREM y OCCIDENTE. Esta pregunta nació de la necesidad de diversificar el riesgo del portafolio. Ahora, tras unas semanas, contamos con una variable más que puede ser útil en el análisis la tasa de depósitos a término fijo a 90 días (DTF). Esta variable es común que se incluya en este tipo de modelos como una variable que captura el rendimiento de un activo libre de riesgo, poner el dinero en un CDT. Esta variable está disponible en el archivo DataCDTs.xlsx118 y la adicionaremos a nuestro modelo. Entonces el modelo que estimaremos será:
\[\begin{gathered}
{\text{GRUPOSUR}}{{\text{A}}_t} = {\beta_1} + {\beta_2}{\text{ECOPETRO}}{{\text{L}}_t} + {\beta_3}{\text{NUTRES}}{{\text{A}}_t} \hfill \\
{\text{ }} + {\beta_4}{\text{EXIT}}{{\text{O}}_t} + {\beta_5}{\text{IS}}{{\text{A}}_t} + {\beta_7}{\text{GRUPOAVA}}{{\text{L}}_t} \hfill \\
{\text{ }} + {\beta_8}{\text{CONCONCRET}}{{\text{O}}_t} + {\beta_9}{\text{VALORE}}{{\text{M}}_t} \hfill \\
{\text{ }} + {\beta_{10}}{\text{OCCIDENT}}{{\text{E}}_t} + {\beta_{11}}{\text{DT}}{{\text{F}}_t} + {\varepsilon _t}, \hfill \\
\end{gathered} \]
Nuestra misión en esta ocasión es terminar el análisis y responder la pregunta de negocio incluyendo la nueva variable, pero antes debemos estar seguros que el modelo estimado está libre de autocorrelación.
11.6.1 Construcción de la base de datos
Nuestra primera tarea es cargar los datos y consolidar todos los datos (los de los rendimientos y los de la \(DTF\) en un solo objeto). Los datos de los rendimientos se encuentran en un archivo RetornosDiarios.RData, así que lo podemos cargar empleando la función load().
El objeto retornos.diarios es de la clase xts, lo cual permite manejar fácilmente las fechas.
Los datos de la \(DTF\) la podemos cargar con la función read_excel() del paquete readxl (Wickham & Bryan, 2019). Esta función tiene una característica importante para este ejercicio, pues nos permite cargar un archivo y especificarle el tipo de variable que deberá aplicar a cada columna al momento de cargar los datos. Esto se puede hacer mediante el argumento col_types. El otro argumento que requiere esta función es el nombre del archivo que contiene los datos y su correspondiente ruta. En nuestro caso, la primera columna del archivo de Excel corresponde a las fechas y la segunda a los datos como tal de la \(DTF\). Para evitar que se pierda la información de la fecha podemos emplear el siguiente código:
library(readxl)
#carga los datos
DTF <-read_excel("./Data/DataCDTs.xlsx", col_types = c("date", "numeric") )
head(DTF, 2)## # A tibble: 2 × 2
## `Fecha(dd/mm/aaaa)` DTF90dias
## <dttm> <dbl>
## 1 2012-01-02 00:00:00 0.0513
## 2 2012-01-03 00:00:00 0.0558## [1] "tbl_df" "tbl" "data.frame"Noten que el nombre de la primera columna fue modificado para hacer más fácil la manipulación de esa variable. Por otro lado, la clase del objeto DTF no es de clase xts. Ésta es una clase que permite manipular fácilmente objetos de series de tiempo. Procedamos a cambiar dicha clase para hacer más fácil la unión de las dos bases de datos.
Carguemos el paquete xts (Ryan & Ulrich, 2020). En dicho paquete tenemos una función con el mismo nombre del paquete (xts()) que permite crear objetos de la clase xts. Esta función requiere dos argumentos. El primero es el objeto que se quiere transformar y el segundo (order.by) es un vector que contiene las fechas que se le asignarán al objeto. Estas fechas deben ser de un formato fecha. Por ahora, tenemos el objeto para ser convertido en objeto xts y nos falta el vector con las correspondientes fechas. Esto lo podemos crear con la función as.Date() del paquete base de R.
Creemos las fechas de la variable Fecha del objeto DTF empleando la función as.Date() y luego procedamos a crear un objeto con el nombre DTF90dias que sea de clase xts.
#Carga librería
library(xts)
#se crea objeto con fechas
DTF$Fecha <- as.Date(DTF$Fecha)
# se verifica la clase de la fecha
class(DTF$Fecha)## [1] "Date"# se crea el nuevo objeto de clase xts
DTF90dias<- xts(DTF$DTF90dias, order.by = DTF$Fecha)
#se verifica la clase del nuevo objeto
class(DTF90dias)## [1] "xts" "zoo"Antes de unir los dos objetos podemos constatar que ambos objetos tienen la misma periodicidad y cubren el mismo periodo. La función periodicity() del paquete xts nos muestra la periodicidad de un objeto de serie de tiempo.
## Daily periodicity from 2012-01-02 to 2019-01-14## Daily periodicity from 2012-01-02 to 2019-01-14Ya podemos unir los dos objetos por medio de la función merge() del paquete xts (es decir, merge.xts()). Esta función permite pegar dos objetos de clase xts de diferentes maneras empleando el argumento join. Si join= “outer”, se crea una base de datos con todas las fechas incluidas en los dos objetos. Si en uno de los objetos no existía una fecha, entonces los valores faltantes se reemplazan por “NA”119 Si join= “inner” se construirá una nueva base de datos únicamente con las filas (fechas) que están en común en ambos objetos. Si join= “left” el nuevo objeto tendrá solo las fechas del primer objeto. Si el segundo objeto no tiene información para una de esas fechas, se rellenará esa información con un “NA”. De manera similar, Si join= “right”, el nuevo objeto tendrá las fechas del segundo objeto.
En nuestro caso, pueden constatar que los dos objetos, si bien cubren el mismo periodo, no tienen la misma cantidad de datos. Esto ocurre porque hay unos días hábiles en los que la Bolsa de Valores no se encuentra abierta, pero sí se recoge información para la DTF. Así, dado que nuestro objetivo, será más conveniente unir los objetos de tal manera que tengamos observaciones para los días en los que la Bolsa de Valores estuvo abierta. Es decir:
## GRUPOSURA ECOPETROL NUTRESA EXITO ISA GRUPOAVAL
## 2012-01-02 1.2779727 -0.3565066 -0.9216655 2.02184181 -1.983834 0.0000000
## 2012-01-03 2.5079684 2.0036027 -0.2781643 0.07695268 1.626052 -2.4292693
## 2012-01-04 0.4324999 1.0446990 -0.5586607 1.07116556 2.478003 -0.4106782
## CONCONCRET VALOREM OCCIDENTE DTF90dias
## 2012-01-02 0 0.000000 0 0.05131078
## 2012-01-03 0 12.583905 0 0.05576149
## 2012-01-04 0 1.342302 0 0.04769692Ahora ya tenemos un objeto con la base de datos.
11.6.2 Residuales del modelo y análisis gráfico de los residuales
Ya podemos correr el modelo y examinar los respectivos residuos120. Esto lo podemos hacer con un gráfico de líneas de los residuos en función del tiempo y uno de dispersión de los residuos en el periodo actual versus los residuos rezagados121.
# estimación del modelo
modelo1 <- lm(GRUPOSURA ~ ., datos.ejeauto)
# se extraen los residuales
e <- residuals(modelo1)
# creamos los gráficos
par(mfrow = c(2, 1))
ts.plot(e, main = "Errores estimados", xlab = "tiempo", ylab = "errores")
plot(e, lag.xts(e), xlab = "errores (t)", ylab = "errores (t-1)", xlim = c(-6, 6),
ylim = c(-6, 6))
reg <- lm(e ~ lag.xts(e))
abline(reg, col = "blue")Figura 11.9: Gráfico de residuales
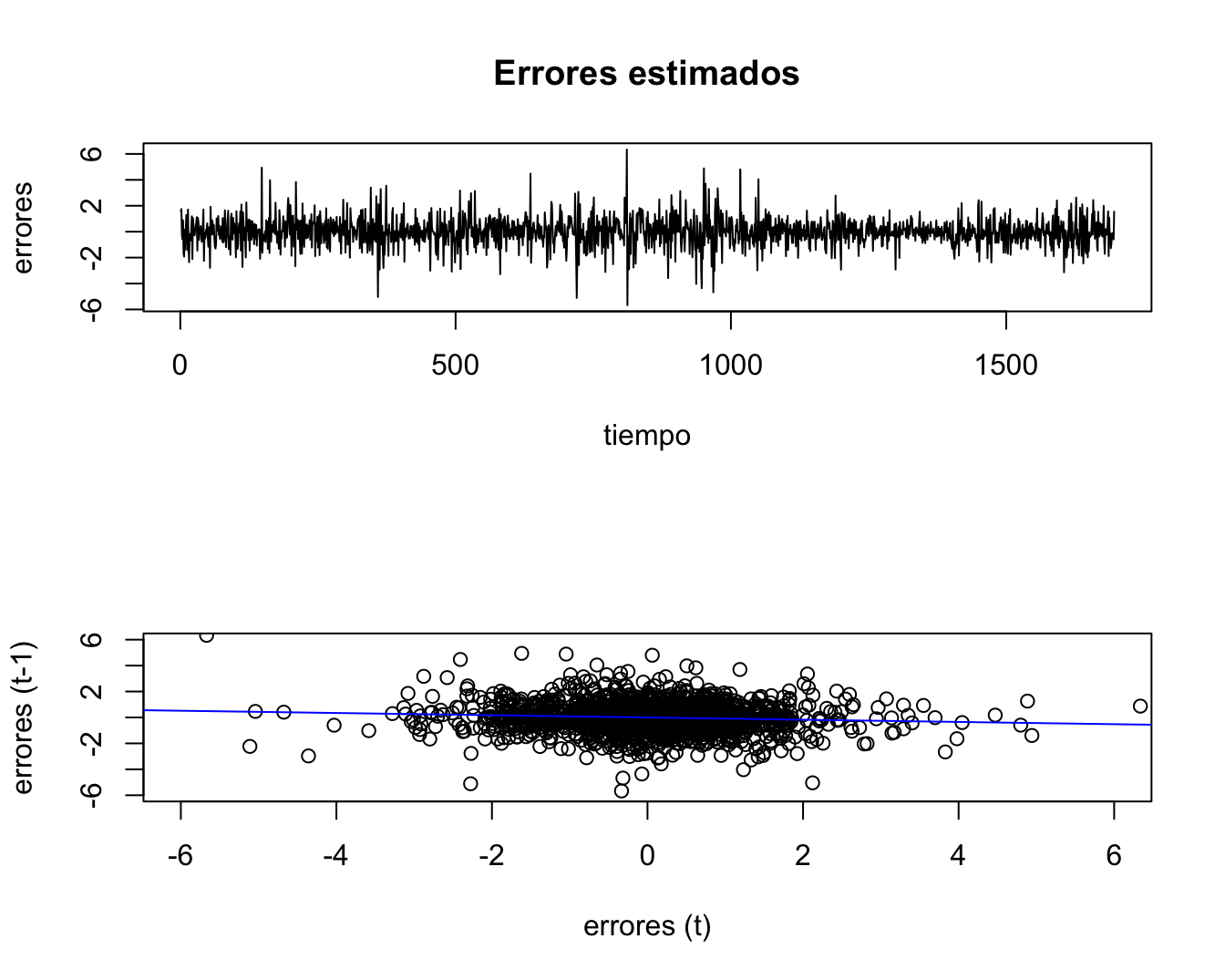
El primer gráfico muestra unos errores que alternan “mucho” su signo, esto puede ser muestra de una autocorrelación negativa. Por otro lado, el segundo gráfico no presenta una fuerte relación negativa entre los errores. Naturalmente, los gráficos nunca serán concluyentes, pero sí nos permiten tener una intuición de lo que está ocurriendo con los residuos. A continuación, se presentan las pruebas de autocorrelación discutidas anteriormente.
11.6.3 Pruebas de Autocorrelación
Recordemos que todas las pruebas descritas anteriormente tienen como hipótesis nula el cumplimiento del supuesto (no autocorrelación) y la alterna la violación de alguna manera del supuesto. Procedamos a efectuar dichas pruebas.
11.6.4 Prueba de Rachas
Para realizar la prueba de rachas, podemos emplear la función runs.test() del paquete tseries (Trapletti & Hornik, 2019). Los argumentos más importantes de esta función son:
donde:
- x: objeto que contiene una variable de clase factor que muestre si el error es positivo o negativo.
- alternative: no es obligatorio y determina cuál es la hipótesis alterna que se desea probar. Si alternative = “two.sided”, la alterna será que existe algún tipo de autocorrelación. Esta es la opción por defecto, es decir si no se especifica este argumento, se efectuará esta prueba. Si alternative = “less” la alterna es que la autocorrelación es positiva (menos cambios de signos que los esperados) y si alternative = “greater”, la alterna es que existe autocorrelación negativa (más cambios de signos que los esperados).
Así, nuestro primer paso para efectuar esta prueba es convertir los residuos estimados en una variable de clase factor que muestre si el signo del residual es positivo o no para cada periodo.
# se crea la variable tipo factor
signo.error <- factor(e>0)
# chequeo de la variable creada
head(signo.error, 3)## 2012-01-02 2012-01-03 2012-01-04
## TRUE TRUE FALSE
## Levels: FALSE TRUE##
## Runs Test
##
## data: signo.error
## Standard Normal = 2.7324, p-value = 0.006288
## alternative hypothesis: two.sided##
## Runs Test
##
## data: signo.error
## Standard Normal = 2.7324, p-value = 0.9969
## alternative hypothesis: less##
## Runs Test
##
## data: signo.error
## Standard Normal = 2.7324, p-value = 0.003144
## alternative hypothesis: greaterLos resultados permiten rechazar con un 99% de confianza (valor p de 0.0063) la no autocorrelación y por tanto se puede concluir que existe algún tipo de autocorrelación. Por otro lado, no se puede rechazar la hipótesis nula de que no existe autocorrelación o autocorrelación negativa (en favor de la alterna de autocorrelación positiva) dado que el correspondiente valor p es 0.9969. Finalmente, podemos concluir con esta prueba que existe autocorrelación negativa con un 99% de confianza (valor p de 0.0031).
11.6.5 Prueba de Durbin-Watson
Esta prueba se puede implementar empleando la función dwtest() del paquete AER (Kleiber & Zeileis, 2008). Los argumentos más importantes de esta función son:
donde:
- formula objeto de clase lm que contenga el modelo al cual se le quiere efectuar la prueba, este argumento es obligatorio.
- alternative no es obligatorio y permite escoger cuál es la hipótesis alterna que se desea probar (Ver Cuadro 11.2). Si alternative = “two.sided”, la alterna será que existe algún tipo de autocorrelación. Si alternative = “greater” la alterna es que la autocorrelación es positiva. Esta es la opción por defecto, es decir si no se especifica este argumento, se efectuará esta prueba.Y si alternative = “less”, la alterna es que existe autocorrelación negativa. Noten que este argumento funciona algo diferente a lo descrito con la prueba de rachas, y por tanto requiere mucho cuidado al momento de emplearlas.
La prueba se puede implementar de la siguiente manera:
# se carga la librería
library(AER)
# prueba de Durbin-Watson
# dos colas
dwtest(modelo1, alternative = "two.sided")##
## Durbin-Watson test
##
## data: modelo1
## DW = 2.1703, p-value = 0.0004734
## alternative hypothesis: true autocorrelation is not 0##
## Durbin-Watson test
##
## data: modelo1
## DW = 2.1703, p-value = 0.9998
## alternative hypothesis: true autocorrelation is greater than 0##
## Durbin-Watson test
##
## data: modelo1
## DW = 2.1703, p-value = 0.0002367
## alternative hypothesis: true autocorrelation is less than 0Estos resultados son similares a los obtenidos por la prueba de rachas. Se rechaza la nula de no autocorrelación (valor p de 5^{-4}) y también se concluye que existe autocorrelación negativa (valor p de 2^{-4}).
Antes de continuar con la siguiente prueba, es importante mencionar que al no contar en este modelo con la variable dependiente rezagada como variable explicativa, no es relevante la prueba h de Durbin. Cuando sea necesario, esta prueba se puede efectuar empleando la función durbinH() del paquete ecm (Bansal, 2021).
11.6.6 Prueba de Box-Pierce y Ljung-Box
La prueba de Box-Pierce y la modificación de Ljung-Box pueden calcularse empleando la misma función de la base de R: Box.test(). Esta función tiene los siguientes tres argumentos importantes:donde:
- x el vector al que se le quiere hacer la prueba.
- lag el número de rezagos para incluir en la hipótesis nula y alterna. Por defecto
lag = 1. - type el tipo de prueba. Las opciones son
type = "Box-Pierce"para realizar la prueba de Box-Pierce (la opción por defecto de la función) ytype = "Ljung-Box"para el de la prueba de Ljung-Box.
Entonces para probar la hipótesis \(H_0: \gamma_1 =0\) con la prueba de Box-Pierce podemos emplear el siguiente código
##
## Box-Pierce test
##
## data: e
## X-squared = 12.642, df = 1, p-value = 0.0003772Así, podemos rechazar la hipótesis nula de no autocorrelación (para el primer rezago). Como se mencionó anteriormente, es común probar esta hipótesis para los primeros rezagos, por lo menos los primeros 20. Es decir: \[\begin{equation*} \begin{array}{l} H_0: \gamma_1 = 0 \\ H_0: \gamma_1 = \gamma _2 = 0 \\ \vdots \\ H_0: \gamma_1 = \gamma _2 = \ldots \gamma _{20} = 0 \\ \end{array} \end{equation*}\]
Para realizar estas pruebas podemos crear una función para construir una tabla con todas las pruebas que se deseen. A continuación, se presenta la función tabla.Box.Pierce().
# se crea función
tabla.Box.Pierce <- function(residuo, max.lag = 20,
type = "Box-Pierce"){
# se crean objetos para guardar los resultados
BP.estadistico <- matrix(0,max.lag,1)
BP.pval <-matrix(0,max.lag,1)
# se calcula la prueba para los diferentes rezagos
for (i in 1:max.lag) {
BP<- Box.test(residuo, lag = i, type = type)
BP.estadistico[i]<-BP$statistic
BP.pval[i]<-round(BP$p.value,5)
}
labels<- c( "Rezagos", type, "p-valor")
Cuerpo.Tabla <- cbind(matrix(1:max.lag,max.lag,1),
BP.estadistico, BP.pval)
TABLABP <- data.frame(Cuerpo.Tabla)
names(TABLABP) <- labels
return(TABLABP)
}Ahora podemos emplear la función para obtener los resultados que se presentan en el Cuadro 11.3.
| Rezagos | Box-Pierce | p-valor |
|---|---|---|
| 1 | 12.642 | 0.000 |
| 2 | 17.533 | 0.000 |
| 3 | 17.621 | 0.001 |
| 4 | 18.527 | 0.001 |
| 5 | 22.762 | 0.000 |
| 6 | 25.180 | 0.000 |
| 7 | 26.344 | 0.000 |
| 8 | 28.830 | 0.000 |
| 9 | 28.897 | 0.001 |
| 10 | 29.917 | 0.001 |
| 11 | 30.074 | 0.002 |
| 12 | 31.092 | 0.002 |
| 13 | 31.093 | 0.003 |
| 14 | 37.819 | 0.001 |
| 15 | 37.820 | 0.001 |
| 16 | 39.308 | 0.001 |
| 17 | 42.405 | 0.001 |
| 18 | 43.893 | 0.001 |
| 19 | 43.914 | 0.001 |
| 20 | 43.964 | 0.002 |
| Fuente: elaboración propia. |
Los resultados nos permiten concluir que las autocorrelaciones de los errores no son cero. Así podemos concluir que existe autocorrelación.
Ahora generar el Cuadro 11.4 que contiene los resultados de la prueba de Ljung-Box aplicada a los mismos residuos.
| Rezagos | Ljung-Box | p-valor |
|---|---|---|
| 1 | 12.664 | 0.000 |
| 2 | 17.567 | 0.000 |
| 3 | 17.655 | 0.001 |
| 4 | 18.564 | 0.001 |
| 5 | 22.817 | 0.000 |
| 6 | 25.247 | 0.000 |
| 7 | 26.417 | 0.000 |
| 8 | 28.917 | 0.000 |
| 9 | 28.985 | 0.001 |
| 10 | 30.012 | 0.001 |
| 11 | 30.170 | 0.001 |
| 12 | 31.196 | 0.002 |
| 13 | 31.198 | 0.003 |
| 14 | 37.988 | 0.001 |
| 15 | 37.988 | 0.001 |
| 16 | 39.492 | 0.001 |
| 17 | 42.625 | 0.001 |
| 18 | 44.130 | 0.001 |
| 19 | 44.152 | 0.001 |
| 20 | 44.202 | 0.001 |
| Fuente: elaboración propia. |
No es sorprendente que los resultados de esta prueba sean los mismos que los obtenidos con la prueba de Box-Pierce, pues en este caso la muestra es grande. Así, la corrección para muestras pequeñas no era importante.
11.6.7 Prueba de Breusch-Godfrey
Esta prueba se puede realizar empleando la función bgtest() del paquete lmtest (Zeileis & Hothorn, 2002). Similar a las anteriores pruebas, esta función tiene dos argumentos. El primero es el objeto de clase lm al que se le quiere hacer la prueba. El segundo argumento es el orden (order) de la autocorrelación que se desea probar. Por defecto este argumento es igual a uno. Para probar la hipótesis nula de no autocorrelación versus la alterna de unos errores con un proceso \(AR(1)\) podemos emplear el siguiente código:
# se carga la librería
library(lmtest)
# prueba Breusch-Godfrey para AR(1)
bgtest(modelo1, order = 1) ##
## Breusch-Godfrey test for serial correlation of order up to 1
##
## data: modelo1
## LM test = 12.818, df = 1, p-value = 0.0003434Los resultados muestran que se puede rechazar la hipótesis nula. En otras palabras, podríamos concluir que los errores pueden seguir un proceso \(AR(1)\), o lo que es equivalente, existe autocorrelación. De manera similar a la anterior prueba, es usual realizar la prueba para diferentes órdenes del proceso AR. En la práctica no es muy común que esta prueba se realice para muchos rezagos. A continuación, se presenta una función que permite realizar la prueba para los rezagos deseados.
# se crea función
tabla.Breusch.Godfrey <- function(modelo, max.order = 5){
# se crean objetos para guardar los resultados
BG.estadistico <- matrix(0, max.order, 1)
BG.pval <-matrix(0, max.order, 1)
# se calcula la prueba para los diferentes rezagos
for (i in 1:max.order) {
BG<- bgtest(modelo, order = i)
BG.estadistico[i]<--BG$statistic
BG.pval[i]<-round(BG$p.value,5)
}
labels<- c( "Orden AR(s)", "Breusch-Godfrey", "p-valor")
Cuerpo.Tabla <- cbind(matrix(1:max.order,max.order,1),
BG.estadistico, BG.pval)
TABLABP <- data.frame(Cuerpo.Tabla)
names(TABLABP) <- labels
return(TABLABP)
}Ahora podemos emplear la función para crear el Cuadro 11.5.
| Orden AR(s) | Breusch-Godfrey | p-valor |
|---|---|---|
| 1 | -12.818 | 0 |
| 2 | -19.287 | 0 |
| 3 | -19.843 | 0 |
| 4 | -21.313 | 0 |
| 5 | -26.854 | 0 |
| Fuente: elaboración propia. |
Esta prueba también permite concluir que existe un problema de autocorrelación.
11.6.8 Solución al problema de autocorrelación con H.A.C.
Todas las pruebas nos llevan a concluir que tenemos un problema de autocorrelación. Este problema lo podemos solucionar empleando estimadores H.A.C. para la matriz de varianzas y covarianzas. Al igual que lo hicimos con la heteroscedasticidad, esto se puede hacer empleando el paquete sandwich (Zeileis, 2004) y las siguientes funciones:
- NeweyWest(): para obtener la corrección de Newey & West (1987).
- kernHAC(): para obtener la corrección de Andrews (1991).
- weave(): para obtener la corrección de Lumley & Heagerty (1999).
Las tres funciones tienen como argumento el objeto de clase lm al que se le quiere corregir la matriz de varianzas y covarianzas.
Por ejemplo, para obtener la matriz de varianzas y covarianzas con la corrección de Newey & West (1987) podemos emplear la siguiente línea de código.
## (Intercept) ECOPETROL NUTRESA EXITO
## (Intercept) 9.251428e-03 -1.868819e-04 7.256654e-05 -6.857704e-05
## ECOPETROL -1.868819e-04 3.123882e-04 3.780966e-05 1.318300e-06
## NUTRESA 7.256654e-05 3.780966e-05 1.226507e-03 -4.168024e-05
## EXITO -6.857704e-05 1.318300e-06 -4.168024e-05 7.578591e-04
## ISA 2.647414e-04 -1.091065e-04 -2.535839e-04 -1.779598e-04
## GRUPOAVAL -5.466807e-05 3.521443e-05 -1.406924e-04 3.037862e-05
## CONCONCRET -1.218345e-05 -5.385873e-06 -6.182498e-05 -1.947145e-05
## VALOREM -1.496096e-04 -6.511587e-06 -5.742468e-05 -9.317952e-05
## OCCIDENTE -3.419532e-05 -5.897218e-06 8.906229e-06 -1.145985e-04
## DTF90dias -1.665297e-01 4.001086e-03 -3.423908e-04 1.317957e-03
## ISA GRUPOAVAL CONCONCRET VALOREM
## (Intercept) 2.647414e-04 -5.466807e-05 -1.218345e-05 -1.496096e-04
## ECOPETROL -1.091065e-04 3.521443e-05 -5.385873e-06 -6.511587e-06
## NUTRESA -2.535839e-04 -1.406924e-04 -6.182498e-05 -5.742468e-05
## EXITO -1.779598e-04 3.037862e-05 -1.947145e-05 -9.317952e-05
## ISA 7.044014e-04 -5.601628e-05 -3.467629e-05 3.369104e-05
## GRUPOAVAL -5.601628e-05 2.960277e-04 2.009650e-08 6.656075e-06
## CONCONCRET -3.467629e-05 2.009650e-08 2.094780e-04 5.700092e-06
## VALOREM 3.369104e-05 6.656075e-06 5.700092e-06 2.199244e-04
## OCCIDENTE -3.396612e-05 -1.318819e-06 4.102452e-07 5.590307e-05
## DTF90dias -6.602825e-03 1.326814e-03 5.690392e-04 1.835562e-03
## OCCIDENTE DTF90dias
## (Intercept) -3.419532e-05 -0.1665296873
## ECOPETROL -5.897218e-06 0.0040010864
## NUTRESA 8.906229e-06 -0.0003423908
## EXITO -1.145985e-04 0.0013179571
## ISA -3.396612e-05 -0.0066028252
## GRUPOAVAL -1.318819e-06 0.0013268136
## CONCONCRET 4.102452e-07 0.0005690392
## VALOREM 5.590307e-05 0.0018355623
## OCCIDENTE 9.564615e-04 -0.0008530728
## DTF90dias -8.530728e-04 3.1537629951Ahora, como no es muy útil la matriz de varianzas y covarianzas sola, sino más bien los respectivos t individuales y sus correspondientes valores p, podemos emplear la función coeftest() del paquete lmtest para realizar las pruebas individuales. Esta función ya la habíamos estudiado en el Capítulo 9. Por ejemplo:
##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.092275 0.096184 0.9594 0.33752
## ECOPETROL 0.121392 0.017675 6.8682 9.112e-12 ***
## NUTRESA 0.141372 0.035022 4.0367 5.664e-05 ***
## EXITO 0.122549 0.027529 4.4516 9.082e-06 ***
## ISA 0.188444 0.026541 7.1002 1.829e-12 ***
## GRUPOAVAL 0.084369 0.017205 4.9036 1.032e-06 ***
## CONCONCRET 0.021385 0.014473 1.4775 0.13973
## VALOREM 0.035525 0.014830 2.3955 0.01671 *
## OCCIDENTE 0.030765 0.030927 0.9948 0.31999
## DTF90dias -1.695802 1.775884 -0.9549 0.33976
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Para este caso podemos ver como individualmente, los coeficientes asociados a los rendimientos de CONCONCRETO, OCCIDENTE y la DTF a 90 días no son significativos individualmente.
Ahora hagamos lo mismo para las correcciones de Andrews (1991) y Lumley & Heagerty (1999).
##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.092275 0.121312 0.7606 0.44698
## ECOPETROL 0.121392 0.018125 6.6975 2.879e-11 ***
## NUTRESA 0.141372 0.035605 3.9705 7.472e-05 ***
## EXITO 0.122549 0.027337 4.4829 7.860e-06 ***
## ISA 0.188444 0.024900 7.5679 6.204e-14 ***
## GRUPOAVAL 0.084369 0.019500 4.3266 1.603e-05 ***
## CONCONCRET 0.021385 0.016233 1.3174 0.18790
## VALOREM 0.035525 0.015976 2.2236 0.02631 *
## OCCIDENTE 0.030765 0.035191 0.8742 0.38212
## DTF90dias -1.695802 2.268825 -0.7474 0.45490
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.092275 0.133149 0.6930 0.48839
## ECOPETROL 0.121392 0.016945 7.1639 1.167e-12 ***
## NUTRESA 0.141372 0.033778 4.1853 2.995e-05 ***
## EXITO 0.122549 0.024031 5.0997 3.786e-07 ***
## ISA 0.188444 0.023324 8.0795 1.227e-15 ***
## GRUPOAVAL 0.084369 0.018810 4.4853 7.774e-06 ***
## CONCONCRET 0.021385 0.015415 1.3872 0.16556
## VALOREM 0.035525 0.016485 2.1550 0.03131 *
## OCCIDENTE 0.030765 0.036069 0.8529 0.39381
## DTF90dias -1.695802 2.488200 -0.6815 0.49562
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Las tres correcciones coinciden en concluir que las siguientes variables no son significativas: CONCONCRETO, OCCIDENTE y la DTF a 90 días.
Ahora miremos si conjuntamente todos los coeficientes que acompañan a dichas variables son significativos. Estimemos el correspondiente modelo anidado y comparemos los modelos
modelo2 <- lm(GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + VALOREM,
datos.ejeauto)
waldtest(modelo2, modelo1, vcov = NeweyWest(modelo1))## Wald test
##
## Model 1: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + VALOREM
## Model 2: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + CONCONCRET +
## VALOREM + OCCIDENTE + DTF90dias
## Res.Df Df F Pr(>F)
## 1 1689
## 2 1686 3 1.3719 0.2496## Wald test
##
## Model 1: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + VALOREM
## Model 2: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + CONCONCRET +
## VALOREM + OCCIDENTE + DTF90dias
## Res.Df Df F Pr(>F)
## 1 1689
## 2 1686 3 0.9793 0.4016## Wald test
##
## Model 1: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + VALOREM
## Model 2: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + CONCONCRET +
## VALOREM + OCCIDENTE + DTF90dias
## Res.Df Df F Pr(>F)
## 1 1689
## 2 1686 3 1.055 0.3672Los resultados muestran, con todas las correcciones que las tres variables son conjuntamente no significativas. En otras palabras, el modelo restringido es mejor que el sin restringir. Así, podemos afirmar que la DTF a 90 días, los rendimientos de CONCONCRETO y OCCIDENTE no afectan el rendimiento de la acción de Suramericana. Los resultados finales se presentan en el Cuadro 11.6.
| MCO | NW | Kenel | Wave | |
|---|---|---|---|---|
| (Intercept) | 0.005 | 0.005 | 0.005 | 0.005 |
| (0.027) | (0.022) | (0.025) | (0.027) | |
| ECOPETROL | 0.122*** | 0.122*** | 0.122*** | 0.122*** |
| (0.014) | (0.018) | (0.018) | (0.017) | |
| NUTRESA | 0.145*** | 0.145*** | 0.145*** | 0.145*** |
| (0.028) | (0.035) | (0.035) | (0.034) | |
| EXITO | 0.123*** | 0.123*** | 0.123*** | 0.123*** |
| (0.018) | (0.028) | (0.028) | (0.024) | |
| ISA | 0.188*** | 0.188*** | 0.188*** | 0.188*** |
| (0.019) | (0.027) | (0.025) | (0.023) | |
| GRUPOAVAL | 0.086*** | 0.086*** | 0.086*** | 0.086*** |
| (0.020) | (0.017) | (0.020) | (0.019) | |
| VALOREM | 0.036* | 0.036* | 0.036* | 0.036* |
| (0.014) | (0.015) | (0.016) | (0.016) | |
| R2 | 0.260 | 0.260 | 0.260 | 0.260 |
| Adj. R2 | 0.258 | 0.258 | 0.258 | 0.258 |
| Num. obs. | 1696 | 1696 | 1696 | 1696 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||||
11.7 Ejercicios
Las respuestas a los ejercicios seleccionados se encuentran en la sección 16.6.
11.7.1 Experimento de Monte Carlo 1
Diseñen un experimento de Monte Carlo similar al que se realizó en el Capítulo 9 en la Introducción. Supongan que existe una autocorrelación en el error que sigue un proceso AR(1) con \(\rho = 0.7\).
11.7.2 Experimento de Monte Carlo 2
Ahora continuando con el mismo \(DGP\) diseñen un experimento de Monte Carlo que nos permita estudiar cuál es la proporción de veces que se rechaza la hipótesis nula de las pruebas individuales para las dos pendientes con los estimadores MCO sin autocorrelación, los estimadores MCO con autocorrelación y la corrección NeweyWest en parecencia de autocorrelación. Realice el experimento para una muestra de tamaño 500, 100, 50 y 20. ¿Qué pueden concluir?
11.7.3 Automóviles
Un científico de datos es contratado por el área de gestión humana de una de las principales empresas que venden automóviles del fabricante WMB en todo el mundo. El interés del gerente del área es entender si la cantidad de vendedores depende de las unidades fabricadas (en miles). Para esto cuenta con datos mensuales de 5 años que se encuentran en el archivo autoEmployee.txt122.
Estimen el modelo y reporten sus resultados en una tabla. Efectúen el análisis gráfico de los errores estimados. ¿Qué tipo de problema pueden intuir a partir de este análisis? Expliquen su respuesta.
Adicionalmente, realicen las pruebas que consideren necesarias para determinar la existencia o no de un problema de autocorrelación en el modelo. De ser necesario corrijan el problema y saquen sus conclusiones.
11.8 Anexos
11.8.1 Demostración de la insesgadez de los estimadores en presencia de autocorrelación
En presencia de autocorrelación los estimadores MCO siguen siendo insesgados. Esta afirmación se puede demostrar fácilmente. Sin perder generalidad consideremos un modelo lineal con un término de error homoscedástico y con autocorrelación de orden uno. Es decir, \[\begin{equation*} {\bf{y}} = {\bf{X}}\beta + \varepsilon \end{equation*}\] Donde \(E\left[ {{\varepsilon_t}} \right] = 0\), \(Var\left[ {{\varepsilon_t}} \right] = \sigma_\varepsilon ^2\) y \({\varepsilon_t} = \rho {\varepsilon_{t - 1}} + {\nu_t}\), \(\forall t\). Ahora determinemos si \(\hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}\) sigue siendo insesgado o no. Así, \[\begin{equation*} E\left[ {\hat \beta } \right] = E\left[ {{{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)}^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}} \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}E\left[ {\bf{y}} \right] \end{equation*}\] \[\begin{equation*} E\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}E\left[ {{\bf{X}}\beta + \varepsilon } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{X}}\beta + {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}E\left[ \varepsilon \right] \end{equation*}\] \[\begin{equation*} E\left[ {\hat \beta } \right] = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{X}}\beta = I \bullet \beta \end{equation*}\] \[\begin{equation*} E\left[ {\hat \beta } \right] = \beta \end{equation*}\]
11.8.2 Sesgo de la matriz de varianzas y covarianzas en presencia de autocorrelación
En presencia de autocorrelación el estimador de la matriz de varianzas y covarianzas de MCO (\(\widehat{Var\left[ {\hat \beta } \right]} = s^2 \left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)\)) es sesgado. Es más el estimador MCO para los coeficientes (\(\hat \beta = \left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} {\bf{X}}^{\bf T} {\bf{y}}\)) no es eficiente; es decir no tiene la mínima varianza posible. Esta afirmación se puede demostrar fácilmente.
Continuando con el modelo considerado en el Apéndice anterior (error con una autocorrelación de orden uno), en este caso tenemos que: \[\begin{equation} Var\left[ \varepsilon \right] = E\left[ {\varepsilon ^T \varepsilon } \right] = \Omega = \sigma_\varepsilon ^2 \left[ {\begin{array}{*{20}c} 1 & \rho & {\rho ^2 } & \cdots & {\rho ^{n - 1} } \\ \rho & 1 & \rho & \cdots & {\rho ^{n - 2} } \\ {\rho ^2 } & \rho & 1 & \cdots & {\rho ^{n - 3} } \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ {\rho ^{n - 1} } & {\rho ^{n - 2} } & {\rho ^{n - 3} } & \rho & 1 \\ \end{array}} \right] \tag{11.3} \end{equation}\]
Ahora podemos calcular la varianza de los estimadores MCO. Es decir,
\[\begin{equation} Var\left[ {\hat \beta } \right] = Var\left[ {\left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} {\bf{X}}^{\bf T} {\bf{y}}} \right] \tag{11.4} \end{equation}\]
Por tanto tendremos que \[\begin{equation} Var\left[ {\hat \beta } \right] = \left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} {\bf{X}}^{\bf T} Var\left[ {\bf{y}} \right]{\bf{X}}\left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} \tag{11.5} \end{equation}\]
\[\begin{equation} Var\left[ {\hat \beta } \right] = \left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} {\bf{X}}^{\bf T} Var\left[ \varepsilon \right]{\bf{X}}\left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} \tag{11.6} \end{equation}\] \[\begin{equation} Var\left[ {\hat \beta } \right] = \left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} {\bf{X}}^{\bf T} \Omega {\bf{X}}\left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} \tag{11.7} \end{equation}\]
Por tanto la varianza no es la mínima posible. Y por otro lado, al emplear el estimador MCO para la matriz de varianzas y covarianzas de los betas (\(\widehat{Var\left[ {\hat \beta } \right]} = s^2 \left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1}\)) en presencia de autocorrelación se obtendrá un estimador cuyo valor esperado no es igual a la varianza real; es decir, será insesgado.
11.8.3 Solución por el método de diferencias generalizadas
Si conocemos la naturaleza de la autocorrelación entonces podemos usar una transformación de la muestra del modelo original para construir una muestra sin este problema. Este método se conoce como transformación de diferencias generalizadas.
Es decir, partiendo del modelo (11.2) con errores \(AR(1)\), se le puede restar el mismo modelo (11.2) rezagado un período y multiplicado por la correlación. De tal manera que se obtiene: \[\begin{equation*} Y_t - \rho {Y_{t - 1}} = {\beta_1}\left( {1 - \rho } \right) + {\beta_2}\left( {{X_{2t}} - \rho {X_{2t - 1}}} \right) + {\beta_3}\left( {{X_{3t}} - \rho {X_{3t - 1}}} \right) + \ldots + {\beta_k}\left( {{X_{kt}} - \rho {X_{kt - 1}}} \right) + {\varepsilon_t} - \rho {\varepsilon_{t - 1}} \end{equation*}\] Reparametrizando tenemos: \[\begin{equation*} Y_t^* = {\beta_1}\left( {1 - \rho } \right) + {\beta_2}X_{2t}^* + {\beta_3}X_{3t}^* + \ldots + {\beta_k}X_{kt}^* + {\nu_t} \end{equation*}\] donde \[\begin{equation} Y_t^* = {Y_t} - \rho {Y_{t - 1}}, \quad X_{2t}^* = {X_{2t}} - \rho {X_{2t - 1}}\quad \rm y \quad X_{3t}^* = {X_{3t}} - \rho {X_{3t - 1}} \tag{11.8} \end{equation}\]
Así, el modelo transformado (11.8) ya no tiene problemas de autocorrelación. Esto es emplear el método de Mínimos Cuadrados Generalizados en su versión especial denominado Método de diferencias generalizadas.
Sin embargo, en la práctica es imposible que conozcamos la naturaleza del problema de autocorrelación con certeza y mucho menos el valor de \(\rho\). Durbin (1960) plantea la solución a este problema, método que tomó el nombre de Método de Durbin. El método de Durbin (1960) permite implementar el método de diferencias generalizadas al estimar en un primer paso el valor de \(\rho\). Por eso se le conoce como un método de Mínimos Cuadrados Factibles . Este método implica los siguientes tres pasos:
- Correr la regresión de la variable dependiente en función de las variables explicativas del modelo original, además incluir las mismas variables independientes rezagadas un período y la variable dependiente rezagada un período. Es decir: \[\begin{equation*} \begin{split} {Y_t} =& {\beta_1} + {\beta_2}{X_{2t}} + {\beta_3}{X_{3t}} + \ldots + {\beta_k}{X_{kt}} + {\rm{ }}{\beta_{k + 1}}{X_{2t - 1}} \\ +& {\beta_{k + 2}}{X_{3t - 1}} + \ldots + {\beta_{k + (k - 1)}}{X_{kt - 1}} + \rho {Y_{t - 1}} + {\varepsilon_t} \end{split} \end{equation*}\]
- De la anterior estimación se obtiene el valor estimado de \(\rho\). A partir de ese valor estimado, realizar las siguientes transformaciones: \[\begin{equation*} Y_t^* = {Y_t} - \hat \rho {Y_{t - 1}}, \quad X_{2t}^* = {X_{2t}} - \hat \rho {X_{2t - 1}}\quad \rm y \quad X_{3t}^* = {X_{3t}} - \hat \rho {X_{3t - 1}} \end{equation*}\]
- Finalmente estimar el siguiente modelo: \[\begin{equation*} Y_t^* = \beta_1^* + {\beta_2}X_{2t}^* + {\beta_3}X_{3t}^* + \ldots + {\beta_k}X_{kt}^* + {\nu_t} \end{equation*}\] donde \(\beta_1^* = {\beta_1}\left( {1 - \hat \rho } \right)\).
Una vez se estima el modelo con el método de Durbin, a los nuevos residuales se les debe hacer las pruebas para asegurarnos que el problema fue solucionado. Si la autocorrelación en los residuales no es de orden uno, es muy probable que esta solución no funcione. En la práctica es aconsejable para los científicos de datos emplear una solución H.A.C.. Dados los grandes volúmenes de observaciones que se emplean, ésta solución provee errores estándar insesgados (robustos) y se garantiza una solución aceptable al problema.
Referencias
Una demostración de esta afirmación se presenta en el anexo al final de capítulo en la sección 11.8 para la demostración de estos resultados.↩︎
A la observación del periodo anterior se le conoce como la variable rezagada. Es decir, \(Y_{t-1}\) es la variable rezagada de \(Y_t\); rezagada un periodo. En este orden de ideas \(Z_{t-2}\) está rezagada dos periodos. En general es común emplear la letra \(p\) para representar el número de rezagos de una variable.↩︎
La correlación entre errores inmediatamente adyacentes también se domina la autocorrelación a un rezago. Por ejemplo, la correlación entre \(\varepsilon_2\) y \(\varepsilon_1\) o la correlación entre \(\varepsilon_3\) y \(\varepsilon_2\). Y en general será la correlación entre \(\varepsilon_t\) y \(\varepsilon_{t-1}\). Si se considera la relación entre errores separados por dos periodos se denomina autocorrelación a dos rezagos (\(\varepsilon_t\) y \(\varepsilon_{t-2}\)), etc.↩︎
A la función que muestra la correlación para diferentes rezagos de un proceso se le denomina función de autocorrelación. ↩︎
En el anexo al final del capítulo (Ver sección 11.8) se presenta una demostración de esta afirmación.↩︎
En el anexo al final del capítulo (Ver sección 11.8) se presenta una demostración de esta afirmación.↩︎
Antes era común construir un intervalo de confianza del 95% para el número de rachas “razonable” bajo la hipótesis nula a partir de los valores críticos provistos por Swed & Eisenhart (1943). Pero esto no es necesario cuando se emplea el valor p.↩︎
Esto explota las características observadas en las Figuras 11.3 y 11.6. ↩︎
Algunos paquetes estadísticos calculan el estadístico \(LM\) multiplicando el \(R^2\) por \(n\) y no por (\(n-s\)). Si el tamaño de la muestra es grande, estas dos aproximaciones son equivalentes, en caso contrario es mejor multiplicar por (\(n-s\)).↩︎
Esta es otra forma de decir que no se cumplen los supuestos del Teorema de Gauss-Markov.↩︎
Esto se puede hacer en R empleando la función tslm() del paquete forecast (Hyndman & Khandakar, 2008). ↩︎
Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/.↩︎
La función permite cambiar como se rellena los datos faltantes empleando el argumento fill. Por defecto fill = NA.↩︎
En el Capítulo 9 vimos que podemos extraer los residuales de un objeto
LMcon la función resid() del paquete central de R. ↩︎Recuerda que el término rezagado implica que la variable se observa en un periodo anterior. Por ejemplo, cuando hablamos de la variable \(y_t\) rezagada un periodo, nos estamos refiriendo a \(y_{t-1}\). Esto se puede hacer en R empleando la función lag.xts() del paquete xts. ↩︎
Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/. ↩︎