3 Inferencia y análisis de regresión
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras porqué es necesario hacer inferencia sobre los valores estimados
- Explicar en sus propias palabras el significado de las métricas de bondad de ajuste de una regresión múltiple
- Realizar pruebas individuales y conjuntas sobre los coeficientes estimados de un modelo de regresión empleando R.
- Valorar mediante la salida de R la bondad estadística del modelo estimado.
- Interpretar y calcular con R de una regresión múltiple.
3.1 Introducción
El término inferencia se refiere a sacar conclusiones para la población (o parámetros poblacionales), a partir de una muestra de la cual hemos estimado nuestro modelo. En este capítulo estudiaremos cómo comprobar restricciones que involucren uno o más parámetros del modelo estudiado. Y en especial discutiremos cómo determinar si una variable o un conjunto de estas afectan o no a la variable dependiente.
En el Capítulo 2 estudiamos el método de Mínimos Cuadrados Ordinarios (MCO) para estimar un modelo lineal de la forma:
\[\begin{equation} \bf{y}_{\bf{n \times 1}} = \bf{X_{\bf{n \times k}}}\beta_{k \times 1} + \varepsilon_{n \times 1} \end{equation}\] Como lo discutimos, el estimador de MCO para el vector de parámetro \(\beta\) está dado por: \[\begin{equation} \hat \beta = \left( \bf{X}^{\bf{T}}\bf{X} \right)^{ - 1}\bf{X}^{\bf{T}}\bf{y} \tag{3.1} \end{equation}\] Adicionalmente, demostramos que si se supone que i) \(X_2, X_3 , \cdots ,{X_k}\) son fijas y linealmente independientes, y ii) \(\left[\varepsilon \right] = 0\), \(Var\left[ \varepsilon \right] = {\sigma ^2}{\bf I_n}\); entonces el estimador de MCO es el mejor estimador lineal insesgado.
Pero, antes de continuar es importante reconocer que la probabilidad de que el estimador de MCO (\(\hat \beta\)) para una muestra dada sea exactamente igual al valor poblacional es cero. Aunque esta última afirmación parezca a primera vista algo contradictoria; si se reflexiona un poco tendrá más sentido. Es imposible “adivinar” correctamente el valor real (con todos los decimales posibles) a partir de un solo intento, cuando el verdadero valor pertenece a un conjunto infinito de valores.
Te debes estar preguntando: si eso es cierto, entonces ¿para qué empleamos estos estimadores si dada una muestra no hay chance que el estimador sea igual al valor real?. La respuesta es clara, como se demostró en el capítulo anterior, en promedio el estimador de MCO es igual al valor poblacional (insesgado); por tanto, si recolectamos un número lo suficientemente grande de muestras podremos encontrar el valor promedio del estimador. Pero evidentemente en la práctica no nos podemos dar el “lujo” de tener más de una muestra para la población en estudio.
Es ahí donde la teoría estadística llega al auxilio del científico de datos. Si bien sabemos que un valor estimado a partir de una muestra tiene una probabilidad de cero de acertar el valor real, si podemos aumentar la certidumbre de nuestra estimación si conocemos la dispersión y la distribución del estimador.
Antes de continuar hagamos un ejercicio para aclarar este punto. Realicemos el siguiente experimento de simulación. Supongamos que se cuenta con el siguiente DGP conocido: \[\begin{equation*} Y_i = 1 + 5 X2_{i} + \varepsilon _i \end{equation*}\]
Ahora supongamos que un científico de datos trata de encontrar ese DGP para lo cual cuenta con observaciones para dos variables explicativas: \(X2_{i}\) y \(X3_{i}\) (Esta última variable sabemos que no afecta a \(Y_i\) pero el científico de datos no lo sabe).
Uno esperaría que al correr una regresión de \(Y_i\) en función de \(X2_i\) y \(X3_i\) y un intercepto, el coeficiente que acompaña \(X2_i\) debería ser igual a 5 y el que acompaña a \(X3_i\) debería ser cero. Veamos si esto ocurre así o no.
Generemos inicialmente una muestra de tamaño 100 (\(n=100\)) del DGP real y además generaremos la variable \(X3_{i}\). El primer paso será generar las variables explicativas. Esto lo haremos, generando números aleatorios de una distribución uniforme entre 2 y 2. Esto lo podemos hacer con la función runif() del paquete base de R. Esta función tiene como argumentos el número de números aleatorios que se quiere generar (n), el valor mínimo que puede tomar el valor aleatorio que se generará (min) y el valor máximo (max).
# se fija una semilla
set.seed(123456)
# se crea la variable explicativa X2
X2 <- runif(n=100, min=-2, max= 2) Noten que estamos empleando la función set.seed() . Esta función genera una semilla aleatoria (random seed en inglés) fija. La semilla aleatoria es un número empleado para inicializar un algoritmo generador de números aleatorios en los computadores. Esto garantiza que siempre que se genere un número aleatorio sea el mismo. De hecho los números aleatorios generados por los computadores no son realmente aleatorios, pues dependen de una función determinística que simula la aleatoriedad que podemos encontrar en la naturaleza. Por eso los números aleatorios generados por un computador se conocen como números pseudoaleatorios.
Regresando a nuestro experimento, ahora generemos el error del modelo. Supongamos que éste fue generado por una distribución normal con media cero y desviación estándar 3. Es decir, \[\begin{equation*} \varepsilon _i \sim N(0,3^2) \end{equation*}\] Los 100 errores que siguen esta distribución los podemos simular empleando la la función rnorm() del paquete base de R. Esta función tiene como argumentos el número de números aleatorios que se quiere generar (n), la media (mean) y la desviación estándar (sd).
Ahora, construyamos la muestra para la variable dependiente empleando el DGP. Es decir,
Noten que hemos generado 100 observaciones para \(Y_i\) y otras 100 para \(X2_i\). Para completar nuestro experimento falta generar \(X3_i\). Hagamos esto y construyamos un data.frame que contenga todas las variables.
# se crea la variable explicativa X3
X3 <- runif(100,3,6)
# se crea el data.frame
data <- data.frame(Y, X2, X3 )
# chequeo del data.frame creado
str(data)## 'data.frame': 100 obs. of 3 variables:
## $ Y : num 1.65 4.6 -0.21 2.21 2.84 ...
## $ X2: num 1.191 1.014 -0.435 -0.634 -0.555 ...
## $ X3: num 4.81 3.2 5.5 3.92 3.93 ...Antes de continuar grafique los datos generados y encontrará una visualización similar a la Figura 3.1.
Figura 3.1: Relación entre los datos simulados
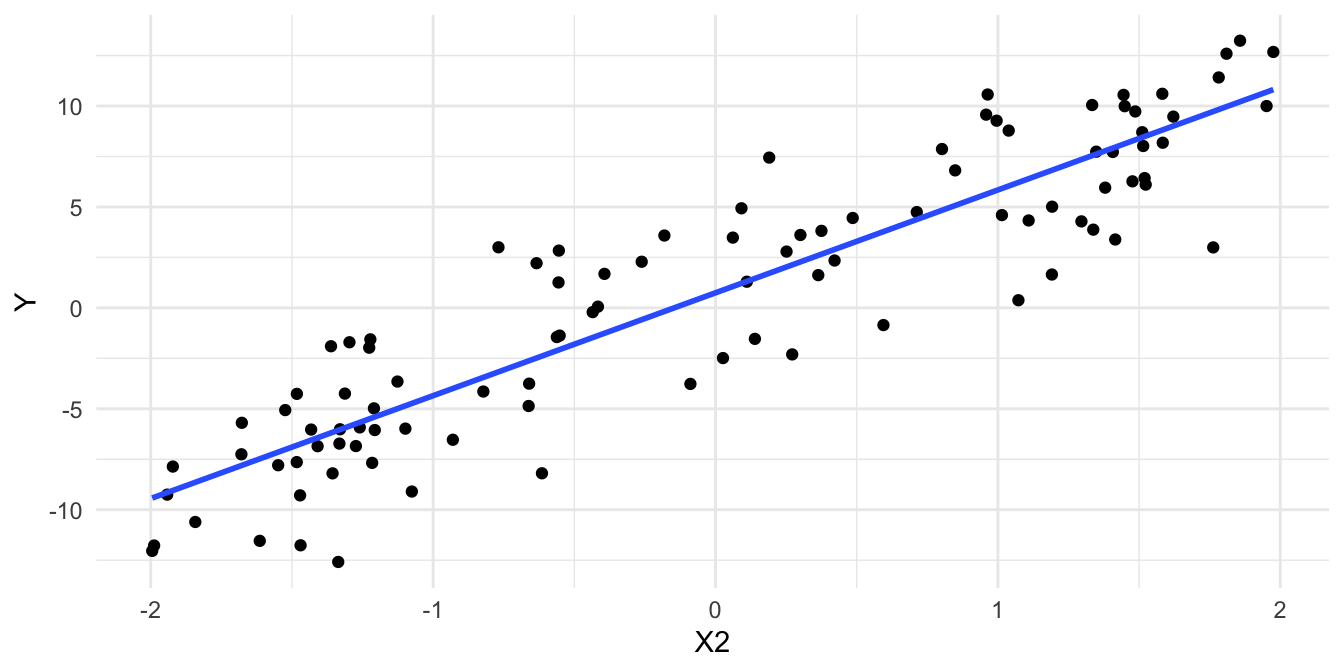
Ahora estimemos el siguiente modelo:
\[\begin{equation*} Y_i = \beta_1 + \beta_2 X2_{i} + \beta_3 X3_{i} + \varepsilon _i \end{equation*}\]
Como lo dijimos anteriormente, se debería esperar que:
- \(\hat \beta_1\) = 1
- \(\hat \beta_2\) = 5
- \(\hat \beta_3\)= 0
Estimemos el modelo.
##
## Call:
## lm(formula = Y ~ X2 + X3, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.9684 -2.0363 0.1182 2.1905 6.2436
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.6305 1.5523 1.05 0.296
## X2 5.0950 0.2395 21.27 <2e-16 ***
## X3 -0.1997 0.3445 -0.58 0.563
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.925 on 97 degrees of freedom
## Multiple R-squared: 0.8237, Adjusted R-squared: 0.82
## F-statistic: 226.5 on 2 and 97 DF, p-value: < 2.2e-16Noten que los valores estimados no coinciden con los valores reales (los del DGP). De aquí nace la afirmación que realizamos anteriormente sobre la probabilidad de cero, que con una muestra podamos obtener un valor estimado exactamente igual al valor poblacional.
Ahora, supongamos que tenemos el lujo de repetir este ejercicio 10 mil veces y guardamos los coeficientes estimados de cada repetición. Es decir, generaremos 10 mil muestras (empleando la misma variable \(X2\) implica suponer que la variable explicatoria es fija) y para cada una de las muestras calculamos los coeficientes y los guardamos32. Para hacer el experimento más interesante generemos el error de cada muestra de una distribución \(\chi^2\) con 5 grados de libertad33.
# se crea objeto para guardar resultados
res <- matrix(, nrow = 10000, ncol = 3)
# se replican los cálculos 10 mil veces
for (N in 1:10000) {
error <- rchisq(100, 5)-5
Y <- 1 + 5 * X2 + error
data <- data.frame(Y, X2, X3 )
res2 <- lm(Y ~ X2 + X3, data = data)
res[N,] <- coef(res2)
}Por otro lado, miremos por un momento los histogramas de la distribución de los coeficientes estimados (Ver Figura 3.2).
## TableGrob (3 x 1) "arrange": 3 grobs
## z cells name grob
## 1 1 (1-1,1-1) arrange gtable[layout]
## 2 2 (2-2,1-1) arrange gtable[layout]
## 3 3 (3-3,1-1) arrange gtable[layout]Figura 3.2: Histograma de los coeficientes estimados (en azul se presenta la media de los coeficientes estimados)
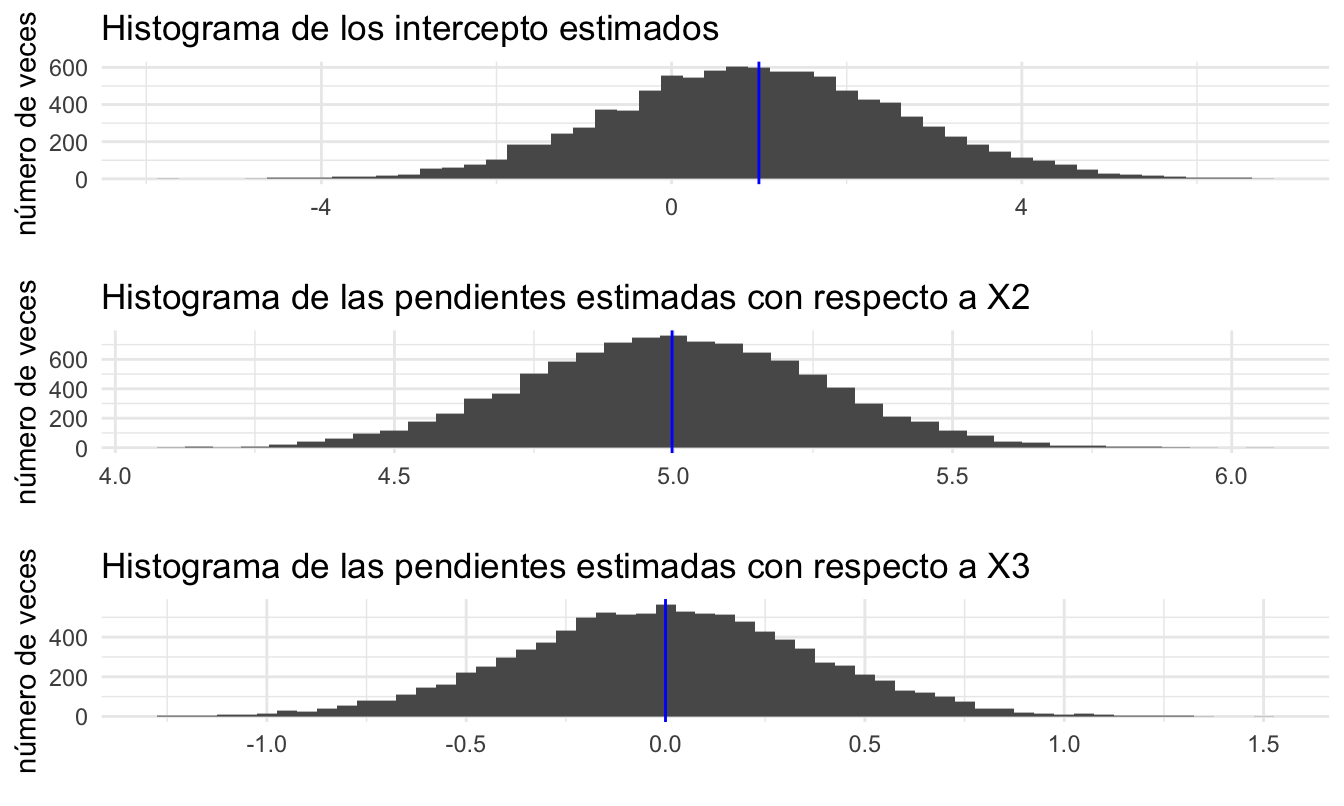
Lo interesante es que la distribución de cada uno de estos coeficientes estimados (distribución muestral del estimador) tiene forma acampanada, de hecho sigue una distribución normal. No obstante, los residuales fueron creados a partir de una distribución \(\chi^2\) con 5 grados de libertad.
Ahora regresemos al caso en que se estima una sola vez el modelo. En ese caso se puede mejorar la precisión del modelo si se realizan pruebas de hipótesis o intervalos de confianza, empleando el resultado anterior.
Con todos los resultados de la simulación en el objeto res podemos, por ejemplo, encontrar la media de los valores estimados.
## b1 b2 b3
## 1 5 0Noten que obtenemos que la media de las 10 mil estimaciones de cada parámetro es igual al valor real. Es decir: \[\begin{equation*} E\left[ {\hat \beta } \right] = \beta \end{equation*}\] En otras palabras, este es un ejemplo de la insesgadez de los coeficientes, tal como se demostró en el capítulo anterior. Este experimento de simulación que acabamos de realizar se conoce como un Experimento o Simulación de Monte Carlo.
¿Qué es un Experimento de Monte Carlo?
Un experimento de Monte Carlo o simulación de Monte Carlo o Método de Monte Carlo es una técnica estadística que se emplea para estimar los posibles resultados de un evento incierto. El método de Monte Carlo fue inventado por John von Neumann y Stanislaw Ulam durante la Segunda Guerra Mundial para mejorar la toma de decisiones en condiciones de incertidumbre. Su nombre proviene de una conocida ciudad de casinos, llamada Mónaco, ya que el elemento de azar es el núcleo del enfoque de este ejercicio, similar al juego de la ruleta.
En la estadística los experimentos de Monte Carlo son empleados, por ejemplo, para:
Comparar el comportamiento y características de estimadores en condiciones de datos realistas.
Proporcionar valores críticos de pruebas estadísticas que sean más ajustadas que aquellos derivados de distribuciones asintóticas.
Los experimentos de Monte Carlo en últimas nos permiten entender el comportamiento de una técnica estadística en las condiciones muy específicas correspondientes al diseño del experimento. Es importante anotar que un experimento de Monte Carlo no corresponde a una demostración, de que un resultado es universal. Y por tanto, no reemplaza una demostración teórica.
En la Figura 3.3 podemos observar cómo las estimaciones del primer modelo (con una sola muestra) pueden ser mejoradas si empleamos un intervalo de confianza que tenga en cuenta la distribución muestral del estimador. Noten que los intervalos contienen los valores reales (poblacionales).
Figura 3.3: Pendientes estimadas para la primera muestra y sus intervalos de confianza
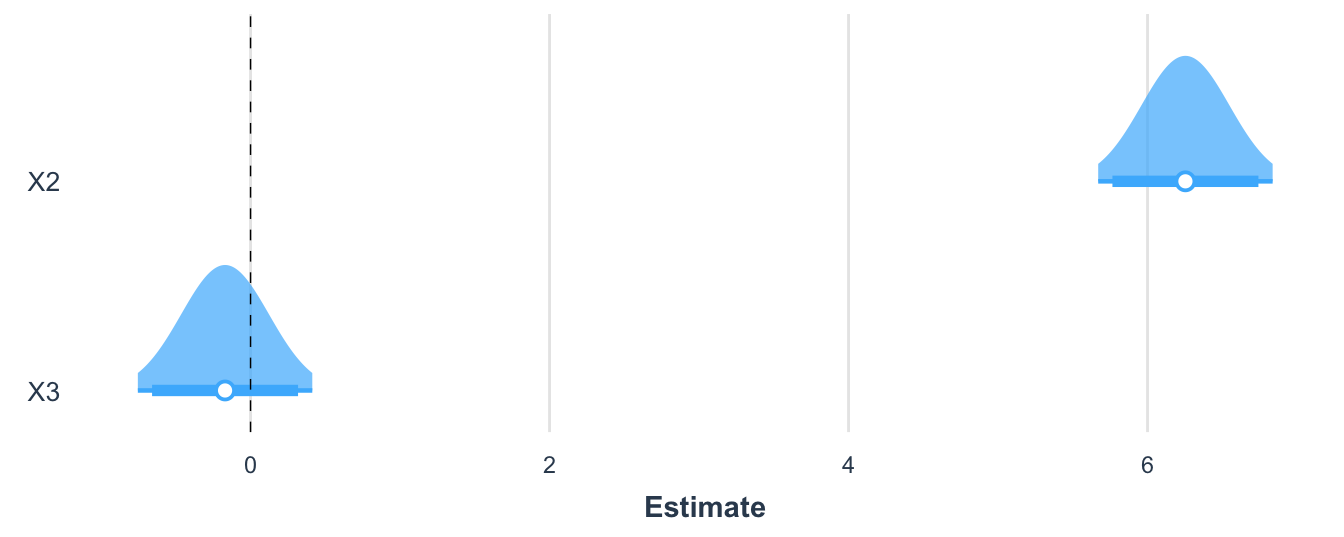
Esto es lo que justifica emplear inferencia como lo veremos en este capítulo.
3.1.1 El Teorema del Límite Central (TLC)]
El teorema del límite central es uno de los resultados más poderosos y asombrosos de la ciencia estadística. La intuición detrás de este teorema es muy sencilla; si se suman un número suficientemente grande de variables aleatorias, entonces sin importar la distribución de las variables aleatorias sumadas, la sumatoria seguirá una distribución normal.
Tal vez, la aplicación más sencilla del TLC es para hacer inferencia sobre la media. Veamos la intuición con un ejercicio mental. Supongamos que quieres conocer el peso medio de una población de estudiantes; es decir, la media poblacional del peso de ellos. En este caso podrán hacer un censo del peso de todos los estudiantes de la universidad y una vez pesados todos, calcular el promedio aritmético. Pero, hacer un censo es muy costoso y dispendioso; por tanto, como aprendieron en sus cursos introductorios de estadística, se acostumbra a seleccionar una muestra aleatoria de tamaño \(n\) y a cada uno de esos \(n\) estudiantes se les pesa (\({W_i}\) para \(i = 1,2,...,n\)). A partir de esta muestra podemos calcular la media muestral, \(\bar w = \frac{{\sum\limits_{i = 1}^n {{W_i}} }}{n}\).
¿Cuál es la probabilidad que \(\bar w\) sea exactamente igual a la media poblacional?. Claramente esta probabilidad es cero; pero gracias al Teorema del Límite Central, si la muestra es lo suficientemente grande, entonces sabemos que \(\bar w\) sigue una distribución normal con una media igual a la media poblacional y varianza igual a la varianza poblacional dividida por el tamaño muestral (\(\frac{{{\sigma ^2}}}{n}\)) (Ver Figura 3.4). Este resultado nos permite aumentar la certidumbre de nuestro pronóstico (\(\bar w\)), para que sea más exacto.
Figura 3.4: Distribución muestral de la media
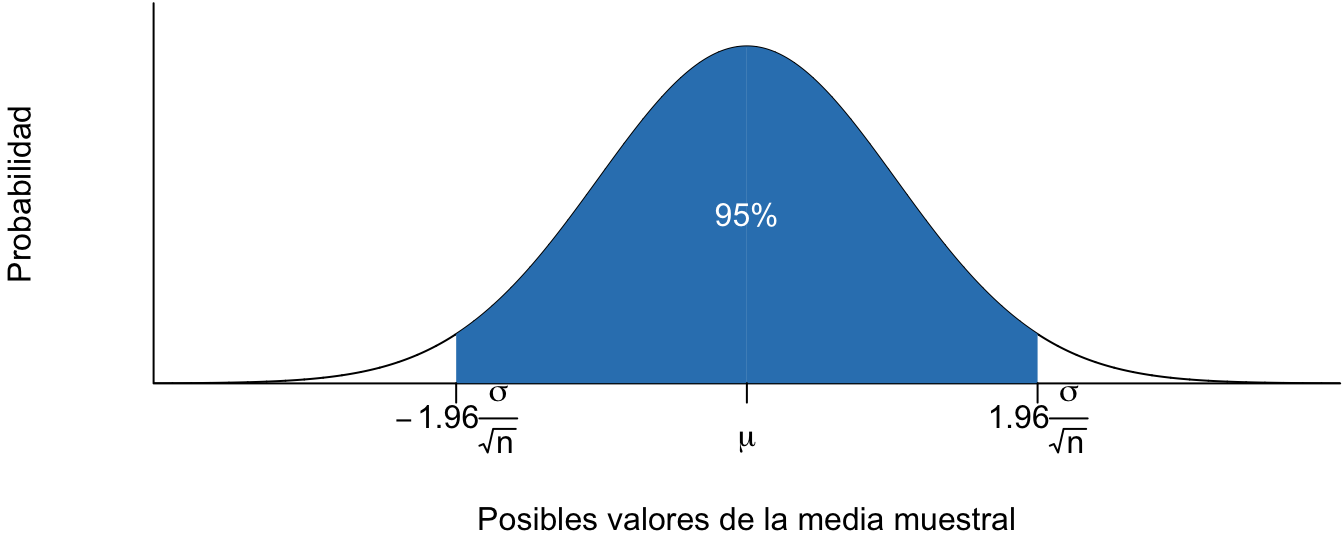
Como la media corresponde a la suma de observaciones que fueron seleccionadas aleatoriamente dividida por una constante (el tamaño de la muestra), entonces el TLC aplica para la media muestral, siempre y cuando la muestra sea seleccionada aleatoriamente. En otras palabras, la distribución muestral de la media seguirá una distribución normal con media igual al valor de la media poblacional (\(\mu\)) y desviación estándar (que para el caso de un estimador se denomina error estándar) \(\frac{\sigma }{{\sqrt n}}\).
De esta manera, sabemos que si nos movemos dos desviaciones estándar (en este caso \(\frac{\sigma }{{\sqrt n }}\)) a la derecha y a la izquierda de nuestro valor estimado, entonces tenemos un 95% de seguridad que el valor real está contenido en ese intervalo. Así, empleando la distribución de nuestro estimador podemos aumentar la certidumbre sobre nuestra estimación.
3.2 Pruebas individuales sobre los parámetros
Regresando al modelo de regresión, empleemos el resultado de la estadística que nos permitirá construir intervalos de confianza y hacer pruebas de hipótesis. Si conocemos la distribución muestral de nuestro estimador de MCO podremos mejorar la certeza en torno a nuestras estimaciones. Estudiemos pues cuál es la distribución de nuestro estimador.
Sabemos que \(E\left[ {\hat \beta } \right] = \beta\) y \(Var\left[ {\hat \beta } \right] = {\sigma ^2}{\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}\). Por tanto, ahora necesitamos conocer la distribución exacta que sigue nuestro estimador de MCO, pues recuerden que una función de distribución no está caracterizada únicamente por su media y varianza. Por otro lado, \(\hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}\) es una combinación lineal de variables no aleatorias y variables aleatorias. Noten que \({\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}\) corresponde a una matriz no aleatoria, pues hemos asumido que \(\bf X\) es una matriz no estocástica. Además, dado que cada uno de los \({{\bf{y}}_{\bf{i}}}\) es una variable aleatoria, pues \({{\bf{y}}_{\bf{i}}}\) depende de \(\varepsilon _i\); tenemos que \({{\bf{X}}^{\bf{T}}}{\bf{y}}\) es un vector cuyos elementos son sumas de variables aleatorias. Es decir: \[\begin{equation*} {{\bf{X}}^{\bf{T}}}{\bf{y}} = \left[ {\begin{array}{*{20}{c}} {\sum\limits_{i = 1}^n {{{\bf{y}}_{\bf{i}}}} } \\ {\sum\limits_{i = 1}^n {{{\bf{y}}_{\bf{i}}}{{\bf{X}}_{{\bf{2i}}}}} } \\ {\sum\limits_{i = 1}^n {{{\bf{y}}_{\bf{i}}}{{\bf{X}}_{{\bf{3i}}}}} } \\ \vdots \\ {\sum\limits_{i = 1}^n {{{\bf{y}}_{\bf{i}}}{{\bf{X}}_{{\bf{ki}}}}} } \\ \end{array}} \right] \end{equation*}\] Por lo tanto, \(\hat \beta = {\left( {{{\bf{X}}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}}{{\bf{X}}^{\bf{T}}}{\bf{y}}\) también será un vector cuyos elementos corresponden a combinaciones lineales de sumas de variables aleatorias. Ahora bien, si tenemos una muestra lo suficientemente grande, podemos emplear el Teorema del Límite Central para concluir que el vector \(\hat \beta\) al ser una combinación de suma de variables aleatorias seguirá una distribución normal.
Así, si hay una muestra lo suficientemente grande tendremos que: \[\begin{equation} \hat \beta \sim {N_k} \left( \beta ,{{\left[ {\sigma ^2} { \left( \bf{X}^{\bf{T}} \bf{X} \right)^{ - 1}}\right]}_{k \times k}} \right) \tag{3.2} \end{equation}\] En otras palabras, los estimadores de MCO seguirán una distribución asintóticamente normal (sigue una distribución Multivariada Normal de orden \(k\)) con media igual al valor poblacional y matriz de varianzas y covarianzas \(\sigma ^2 \left( {{\bf{X}^{\bf{T}}}{\bf{X}}} \right)^{ - 1}\).
De esta manera, cualquier estimador \({\hat \beta_p}\), para \(1 \le p \le k\), seguirá una distribución asintótica normal con media igual al valor poblacional \({\beta_p}\) y varianza igual al elemento en la columna y fila \(p\) de la matriz de varianzas y covarianzas de los estimadores de MCO. En otras palabras: \[\begin{equation} \hat \beta_p \sim N\left( {\beta_p}, \left[ {\sigma ^2} \left \{ {Elemento \:\: de \:\: la \:\: matriz{\left( {\bf{X}^{\bf{T}} \bf{X}} \right)}^{ - 1}} \right \} \right] \right) \tag{3.3} \end{equation}\]
Una vez conocemos la distribución del estimador de MCO podremos hacer inferencia sobre los parámetros poblacionales. En lo que resta de este capítulo discutiremos cómo hacer inferencia respecto a un parámetro (pruebas individuales) y sobre un conjunto de ellos (pruebas conjuntas).
Hay un pequeño inconveniente al emplear el resultado de la ecuación (3.3). En la práctica, no conocemos el valor poblacional de la varianza del error \({\sigma ^2}\), por tanto debemos estimarlo por medio de \({s^2}\). Al estimar este parámetro, estamos introduciendo más incertidumbre en nuestro proceso de inferencia. Esta incertidumbre, agregada al problema de inferencia, implica que la distribución de los estimadores no será tan concentrada hacia la media, como lo es una distribución normal cuyas colas son relativamente pequeñas. La mayor incertidumbre implicará una mayor probabilidad de estar lejos del valor de la media poblacional, que se refleja en unas colas más grandes (más altas). Estas colas más altas, aun manteniendo la simetría y gran masa de probabilidad cercana a la media, se pueden capturar con una distribución t.
Por tanto, cuando no conocemos la varianza poblacional del término aleatorio de error (¡qué es siempre!), cada uno de los estimadores de MCO seguirá una distribución t, con \(n-k\) grados de libertad. De esta manera, tenemos que un intervalo de confianza para \({\beta_k}\) del \(\left( {1 - \alpha } \right)100\%\) de confianza está dado por:
\[\begin{equation} {\hat \beta_p} \pm {t_{\frac{\alpha }{2},n - k}}{s_{{{\hat \beta }_p}}} \tag{3.4} \end{equation}\] donde \({s_{{{\hat \beta }_p}}}\) corresponde a la raíz cuadrada de la varianza estimada del estimador \({\hat \beta_p}\).
Además, la distribución del estimador nos permite probar la hipótesis nula que el valor poblacional \({\beta_p}\) es igual a cualquier constante \(c\), es decir \({H_o}:{\beta_p} = c\); versus la hipótesis alterna que \({\beta_p}\) no es igual a la constante \(c\), \({H_A}:{\beta_p} \ne c\). Para contrastar estas hipótesis, se emplea el siguiente estadístico t de prueba: \[\begin{equation} {t_c} = \frac{{{\hat \beta}_p} - c}{s_{{\hat \beta }_p}} \tag{3.5} \end{equation}\] Este estadístico \({t_c}\) (o t-calculado) sigue una distribución t con \(n-k\) grados de libertad; por tanto, se rechazará la hipótesis nula si el valor absoluto del estadístico \({t_c}\) es lo suficientemente grande. En otras palabras, si \(\left|{t_c} \right| > t_{\frac{\alpha }{2},n-k}\).
Un caso muy especial es cuando \(c=0\), en ese caso la hipótesis nula implicará \({\beta_k} = 0\); es decir, la variable \({X_k}\) no explica la variable dependiente. Por otro lado, la hipótesis alterna implicará que \({\beta_k} \ne 0\); es decir, la variable \({X_k}\) sí ayuda a explicar la variable dependiente. Cuando se concluye a partir de la muestra que \({\beta_k} \ne 0\), entonces se dice que la variable \({X_k}\) es significativa para el modelo, alternativamente se dice que el coeficiente \({\beta_k}\) es significativo. Por esto, este tipo de pruebas se conocen como pruebas de significancia individual.
Estructura de una prueba de hipótesis
En general una prueba de hipótesis siempre tiene la siguiente estructura
- \(H_0\): Hipótesis Nula (hipótesis que se quiere refutar)
- \(H_A\): Hipótesis Alterna (hipótesis que se quiere aceptar)
- Cálculo de un estadístico (depende de la distribución del estimador)
- Decisión (Comparar el estadístico calculado con un valor crítico de la correspondiente función de distribución o tomar decisión con el valor p)
Es importante tener en cuenta que por razones técnicas la hipótesis alterna nunca puede contener un igual. Así, aún si lo que se desea probar es que un \(\beta_i = 0\) no es posible asignar esta opción en la hipótesis alterna y tocará asignarla a la hipótesis nula.
Tipos de error de las pruebas de hipótesis
Dado un nivel de significancia \(\alpha\), si se rechaza la hipótesis nula es posible que incorrectamente hayamos rechazado la hipótesis nula cuando esta era verdadera. A este error lo llamamos error tipo I. Los estadísticos de pruebas están diseñados para que la probabilidad de ocurrencia del error tipo I sea \(\alpha\%\). Supongamos ahora que no es posible rechazar la hipótesis nula, en este caso es factible que no estemos rechazando la hipótesis nula cuando esta en verdad es falsa. En ese caso el error se denomina error tipo II y su probabilidad se denominado con la letra griega \(\beta\). Por tanto, lo ideal al diseñar una prueba de hipótesis es que tanto \(\alpha\) como \(\beta\) sean lo más pequeño posible. Lastimosamente existe un compromiso (trade-off) entre el error tipo I y el error tipo II; pues cuando se disminuye el error tipo I, el error tipo II se aumenta. Típicamente, el tamaño de \(\beta\) no es conocido a priori.
Es por esta razón, que siempre que se plantea una prueba de hipótesis, se trata de construir la hipótesis nula y la alterna, de tal forma que lo que se desea comprobar sea planteado en la hipótesis alterna y no en la hipótesis nula. Así, se pretende cometer un error tipo I mínimo que es más fácilmente controlable por el investigador, dado que los estadísticos para efectuar las pruebas de hipótesis son diseñados para controlar el error tipo I, dejando el error tipo II sin control.
Una manera alternativa de rechazar o no \(H_0\) es empleando el valor p. Este valor corresponde a la probabilidad de obtener un estadístico \(t\) más grande en valor absoluto que el observado (Ver Figura 3.5).
Figura 3.5: Relación entre el p-valor y el nivel de significancia.
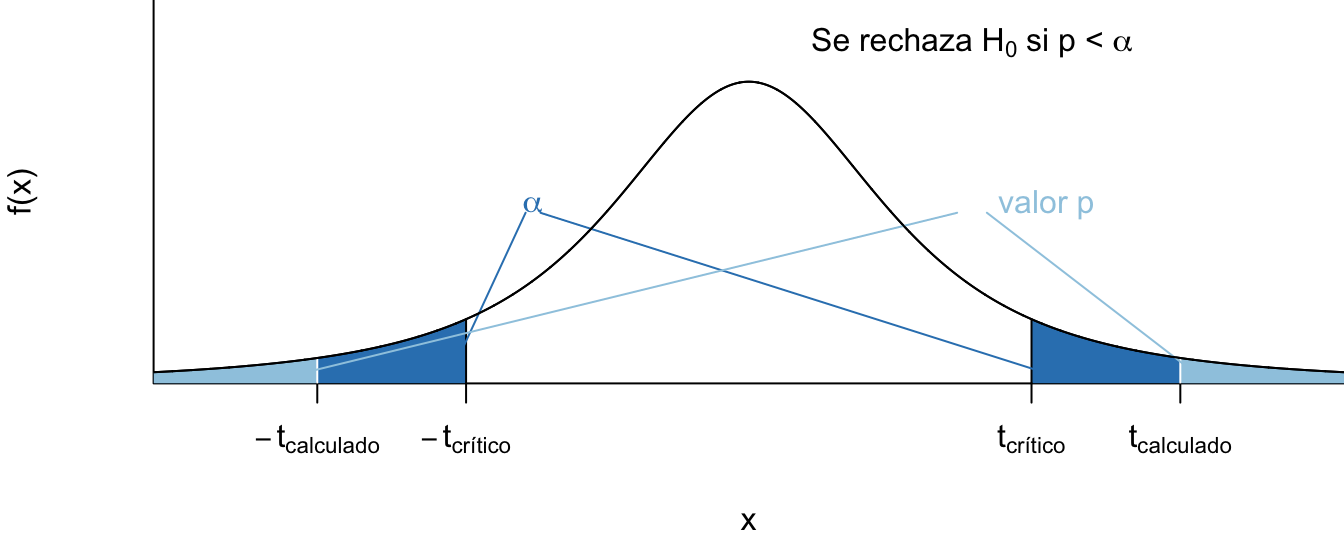
Empleando este criterio, la decisión de rechazar la hipótesis nula se puede tomar de la forma como se describe en el Cuadro 3.1.
| Nivel de significancia (%) | Se rechaza si |
|---|---|
| 10 | valor p < 0.1 |
| 5 | valor p < 0.05 |
| 1 | valor p < 0.01 |
| Fuente: elaboración propia. |
3.2.1 La distribución t de Student y la distribución normal
La distribución t posee una forma similar a la de la distribución normal. La diferencia esta en las colas (los extremos) de las dos distribuciones. La distribución t tiende a tener colas más pesadas34 y, por tanto, un centro con menor probabilidad. Es decir, existe más probabilidad de caer lejos de la media en la distribución t que en la normal. Otra característica importante de la distribución t es que esta depende de un parámetro conocido como los grados de libertad.
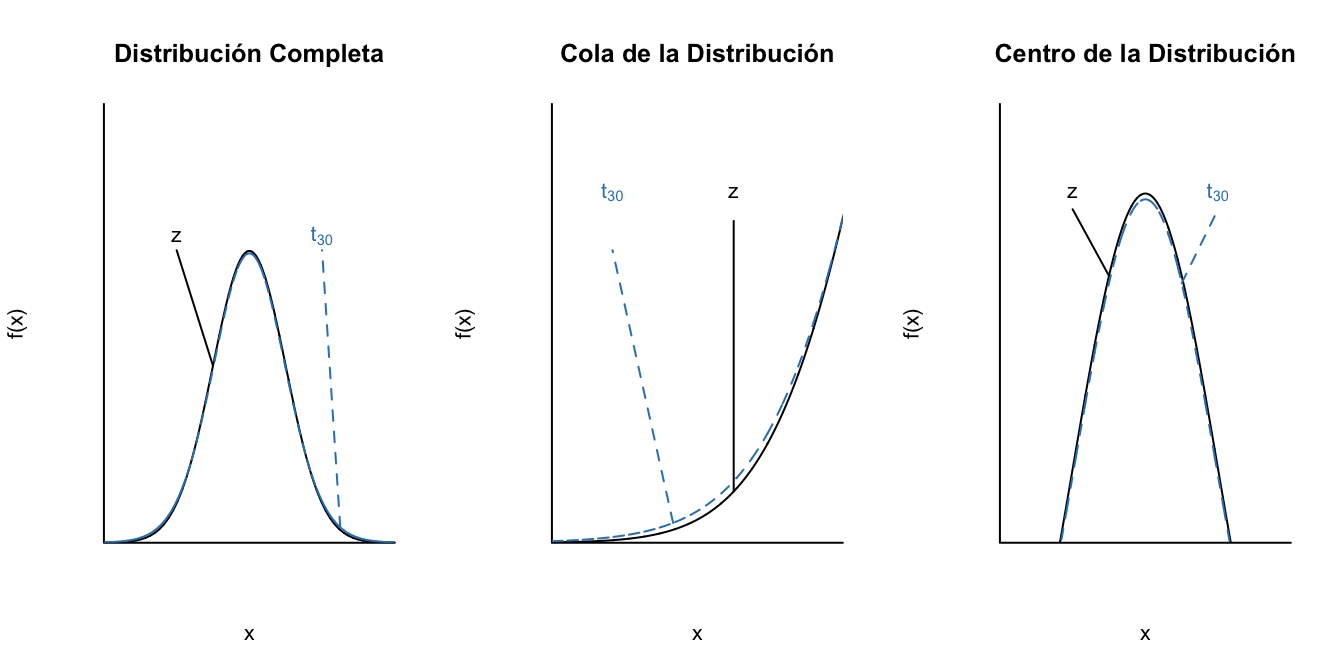
Los grados de libertad pueden ser entendidos como la cantidad de datos que están disponibles para hacer la inferencia y en este contexto para estimar la varianza poblacional del error. Así, entre más grande sea la muestra (o menor número de parámetros a estimar), o sea más grados de libertad, la precisión será mayor y, por tanto, existe una menor probabilidad de obtener valores lejanos del centro de la distribución. Es decir, entre más grados de libertad menos pesadas las colas. Así, más se parecerán la distribución t y la estándar normal. En las Figuras 3.6, 3.7 y 3.8 se presenta este resultado.
Figura 3.6: Diferencia entre la distribución estándar normal y la t con 1 grado de libertad
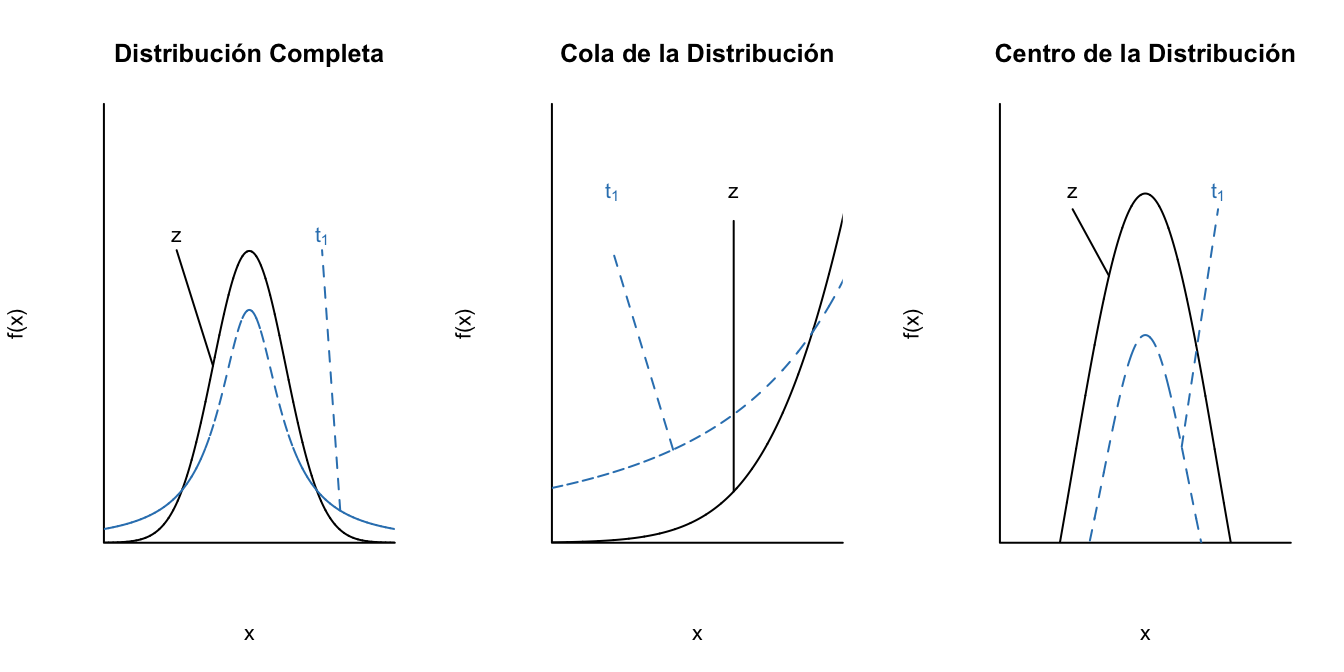
Figura 3.7: Diferencia entre la distribución estándar normal y la t con 10 grado de libertad
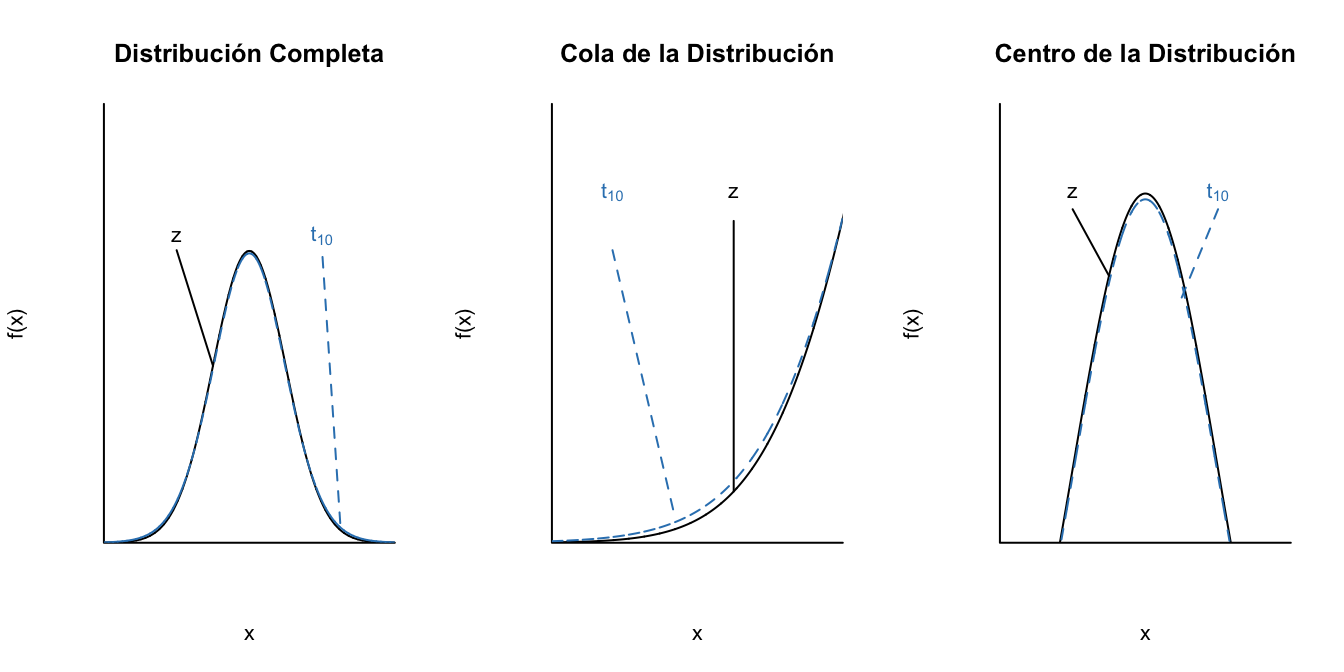
Figura 3.8: Diferencia entre la distribución estándar normal y la t con 30 grado de libertad
Así, teniendo en cuenta la estimación de la varianza, tenemos que un intervalo de confianza del \(100(1-\alpha)\%\) para la media poblacional cuando la varianza es desconocida está dado por: \[\begin{equation} \bar X \mp {t_{n - 1,\frac{\alpha }{2}}}\frac{s}{{\sqrt n }} \tag{3.6} \end{equation}\] donde, \({t_{n - 1,\frac{\alpha }{2}}}\) corresponde al valor de la distribución \(t\) de Student con \(n-1\) grados de libertad tal que \(P\left( {\left| w \right| \le {t_{n - 1,\frac{\alpha }{2}}}} \right) = \alpha\).
3.3 El ajuste del modelo (Fit del modelo)
Antes de continuar, es necesario preguntarnos ¿cómo determinar si el modelo estimado explica satisfactoriamente la muestra bajo estudio? En otras palabras, si el modelo estadístico se ajusta bien a la muestra. En especial, ¿cómo podemos saber si el modelo lineal en efecto es válido para la muestra?, pues recuerde que nuestro primer supuesto es que la relación entre las variables independientes y la dependiente es lineal, supuesto simplificador que en la mayoría de los casos no tiene ningún soporte teórico.
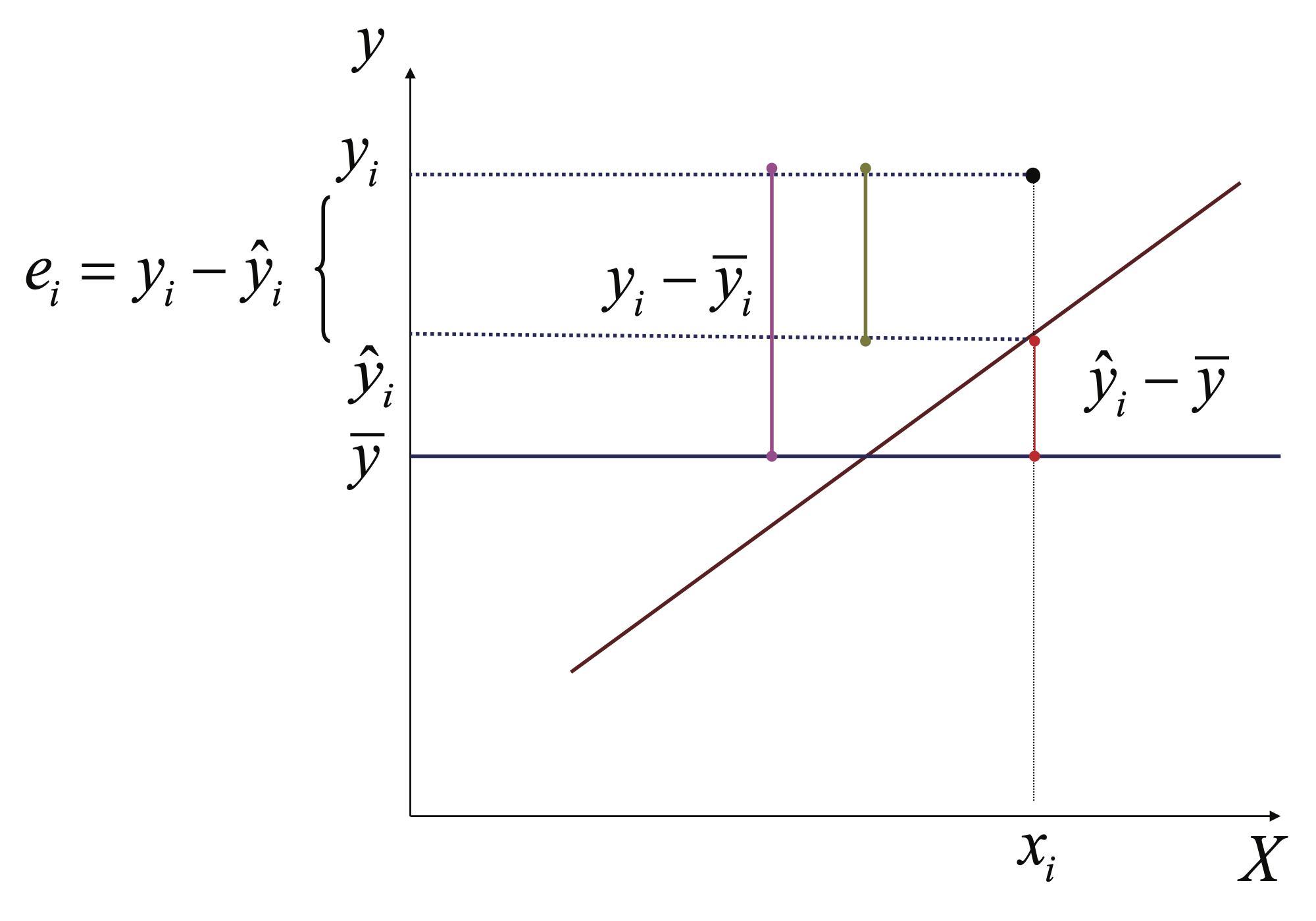
Antes de analizar qué tan bien explica nuestro modelo la variable dependiente, es necesario discutir cómo se puede descomponer la variabilidad de la variable dependiente. Inicialmente consideremos la variación total de la variable dependiente con respecto a su media \(\left( {{y_i} - \bar y} \right)\), esta variación puede ser descompuesta en dos partes35. La primera de ellas es la parte de la variación que es explicada por el modelo; esta parte de la variación es la diferencia que existe entre lo que predice el modelo para la observación36 \(i\) (\({\hat y_i}\)) y nuestra mejor predicción si no contáramos con un modelo, es decir la media de la variable dependiente (\(\bar y\)). En otras palabras, la parte de la variación de la variable dependiente explicada por el modelo corresponde a \(\left( {{{\hat y}_i} - \bar y} \right)\). La segunda parte de la variación de la variable dependiente es la que no puede ser explicada por el modelo, que denominaremos el error o residuo. Formalmente, \({\hat \epsilon_i} = \left( {{y_i} - {{\hat y}_i}} \right)\). Así, \(\left( {{y_i} - \bar y} \right) = \left( {{{\hat y}_i} - \bar y} \right) + \left( {{y_i} - {{\hat y}_i}} \right)\).
Para entender mejor esta descomposición de la de la variación total de la variable dependiente, empleemos una aproximación gráfica. Si no contamos con un modelo, la mejor forma de explicar la variable dependiente es empleando su media. A la diferencia entre la media y cada observación se le conoce como la variación total, representada en color rosado en la Figura 3.9.
Figura 3.9: Ejemplo de la variación total para una observación de la variable dependiente (\(y_i\))
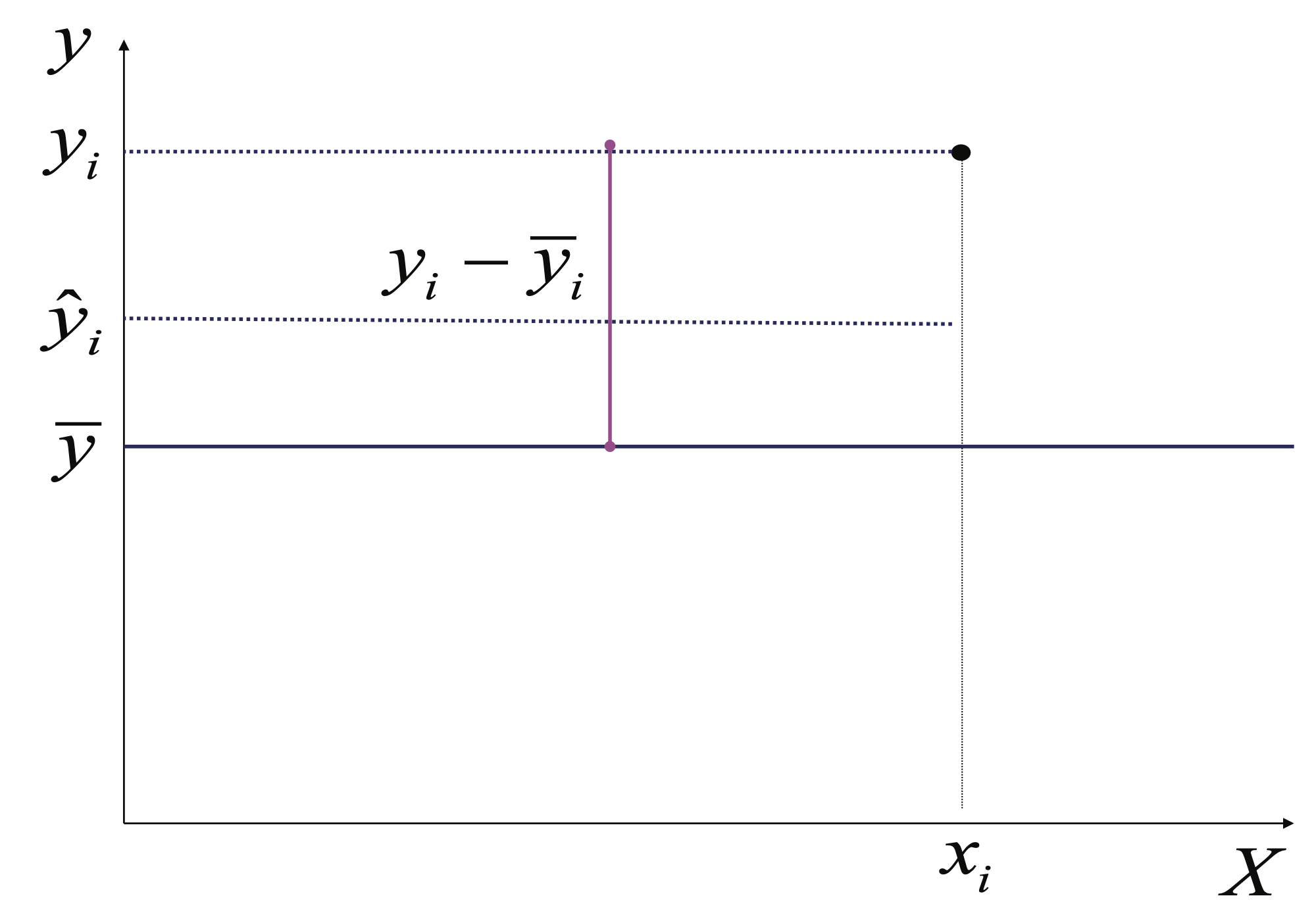
La variación total se puede descomponer en: i) la parte explicada por el modelo \(\left( {{{\hat y}_i} - \bar y} \right)\) (Ver Figura 3.10), y ii) la parte que el modelo no explica (el error) \({\hat \epsilon_i} = \left( {{y_i} - {{\hat y}_i}} \right)\) (Ver Figura 3.11).
Figura 3.10: Ejemplo de la variación explicada por el modelo para una observación de la variable dependiente (\(y_i\))
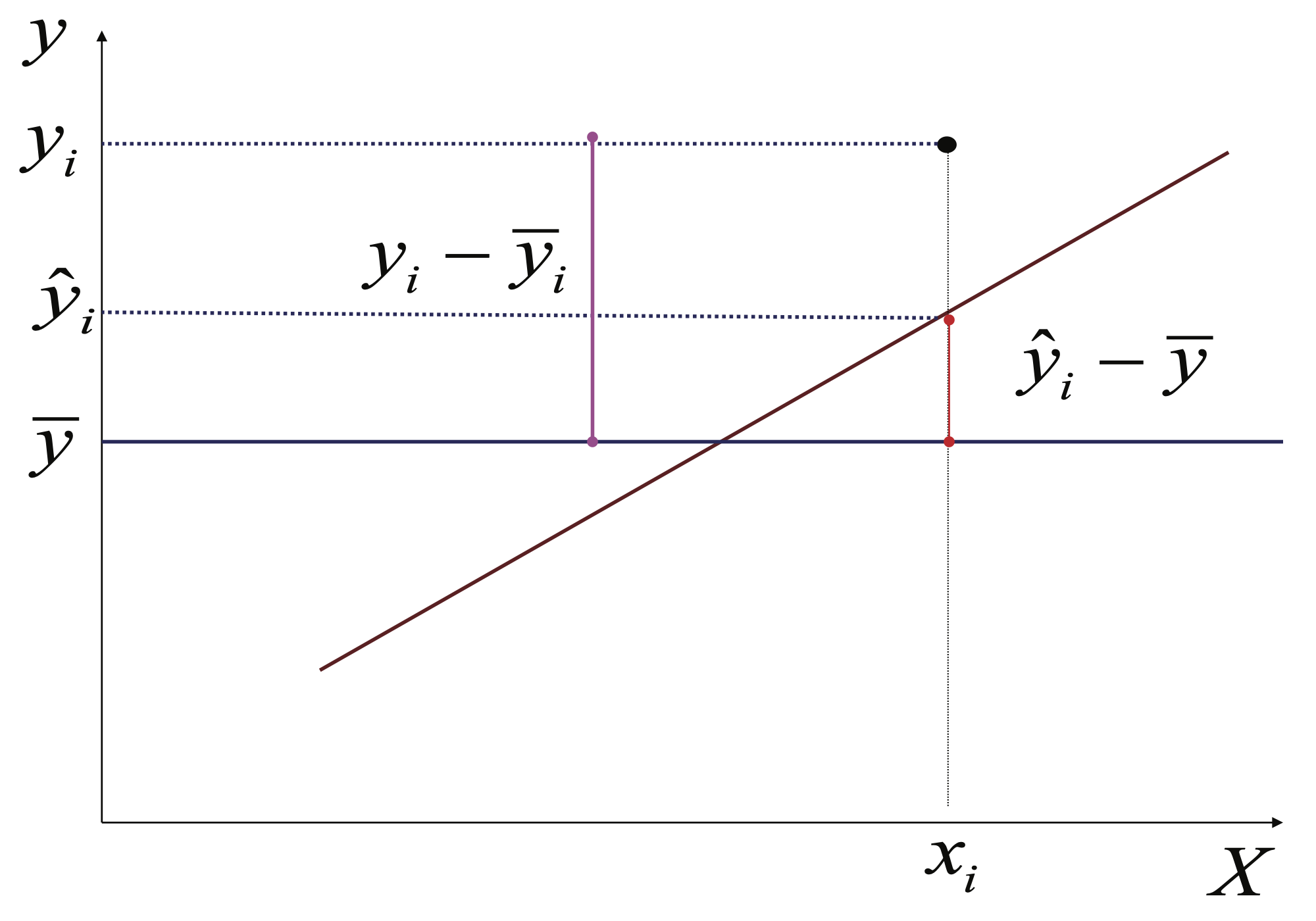
Figura 3.11: Ejemplo de la variación no explicada por el modelo para una observación de la variable dependiente (\(y_i\))
Regresando al análisis de la bondad de ajuste de una regresión, si queremos conocer la variación total de la variable dependiente para toda la muestra, es buena idea considerar la suma de todas las variaciones al cuadrado para evitar el efecto contrario, de variaciones por encima y por debajo de la media. Llamaremos a \(\sum\limits_{i = 1}^n {{{\left( {{y_i} - \bar y} \right)}^2}}\) la Suma Total al Cuadrado (\(SST\) por su nombre en inglés: Sum of Squares Total). Es muy fácil mostrar que en presencia de un modelo con intercepto37: \[\begin{equation} \sum\limits_{i = 1}^n {{{\left( {{y_i} - \bar y} \right)}^2}} = \sum\limits_{i = 1}^n {{{\left( {{{\hat y}_i} - \bar y} \right)}^2}} + \sum\limits_{i = 1}^n {{{\left( {{y_i} - {{\hat y}_i}} \right)}^2}} \tag{3.7} \end{equation}\]
La parte de esta variación total al cuadrado que es explicada por el modelo será \(\sum\limits_{i = 1}^n {{{\left( {{{\hat y}_i} - \bar y} \right)}^2}}\), la denotaremos como \(SSR\) (por su nombre en inglés: Sum of Squares of the Regression). Y la parte que no es explicada por la regresión se denotará por \(SSE\) (por su nombre en inglés: Sum of Squares Error). Estas sumas al cuadrado también se pueden expresar en forma matricial. Es relativamente fácil mostrar que: \[\begin{equation*} SST = \sum\limits_{i = 1}^n {{{\left( {{y_i} - \bar y} \right)}^2}} = {{\bf{y}}^{\bf{T}}}{\bf{y}} - n{{\bf{\bar y}}^2} \end{equation*}\] \[\begin{equation*} SSR = \sum\limits_{i = 1}^n {{{\left( {{{\hat y}_i} - \bar y} \right)}^2}} = {\hat \beta ^T}{{\bf{X}}^{\bf{T}}}{\bf{y}} - n{{\bf{\bar y}}^2} \end{equation*}\] \[\begin{equation*} SSE = \sum\limits_{i = 1}^n {{{\left( {{y_i} - {{\hat y}_i}} \right)}^2}} = {{\bf{y}}^{\bf{T}}}{\bf{y}} - {\hat \beta ^T}{{\bf{X}}^{\bf{T}}}{\bf{y}} \end{equation*}\] Así tendremos que, \[\begin{equation*} SST = SSR + SSE \end{equation*}\]
Una evidente medida de qué tan bueno es nuestro modelo es examinar qué porcentaje de la variación total es explicada por el modelo, a esto se le conoce como el \(R^2\). Formalmente, \[\begin{equation*} {R^2} = \frac{{SSR}}{{SST}} = 1 - \frac{{SSE}}{{SST}}. \end{equation*}\] Dado que el \(R^2\) es un porcentaje, éste estará entre cero y uno; es decir, \(0 \le {R^2} \le 1\). Si \({R^2} = 1\), entonces toda la variación de la variable dependiente es explicada por el modelo; para el caso de dos variables explicativas, esto implicará que todos los puntos se encuentran sobre el plano estimado por el modelo, en caso de tener una sola variable explicativa, este \(R^2\) implicará que todos los puntos están sobre la línea de regresión. Por otro lado, si \({R^2} = 0\) tendremos que nuestro modelo no explica nada de la variación de la variable dependiente.
Antes de continuar, es importante anotar algunas consideraciones para tener en cuenta sobre la medida de bondad de ajuste brindada por el \(R^2\). Primero, es relativamente fácil mostrar que en caso de que el modelo estimado no contenga un intercepto, entonces \(SST \ne SSR + SSE\) (ver Anexo 3.8 al final del capítulo). Por tanto, en ese caso el \(R^2\) no representará la parte de la variabilidad total de la variable dependiente explicada por el modelo, por eso se dice que el \(R^2\) carece de interpretación cuando el modelo estimado no posee intercepto.
Segundo, dado que el \(R^2\) es una medida del ajuste de un modelo lineal estimado a los datos, entonces el \(R^2\) se puede emplear para escoger entre diferentes modelos lineales el que se ajuste mejor a los datos, pero si se cumplen algunas condiciones.
Por ejemplo, supongamos que se quiere estimar la de demanda de un bien \({Q_i}\), para lo cual se cuenta con datos de su precio (\(p_i\)), el precio de un bien sustituto (\(ps_i\)) y un bien complementario (\(pc_i\)) y el nivel ingreso medio de los consumidores de este bien (\(I_i\)). Así, para estimar la demanda de este bien se emplean los siguientes modelos: \[\begin{equation} {Q_i} = {\beta_0} + {\beta_1}{p_i} + {\beta_2}pc_i + {\beta_3}ps_i + {\beta_4}{I_i} + {\varepsilon _i} \tag{3.8} \end{equation}\] \[\begin{equation} \ln \left( {{Q_i}} \right) = {\gamma _0} + {\gamma _1}\ln \left( {{p_i}} \right) + {\gamma _2}\ln \left( {pc_i} \right) + {\gamma _3}\ln \left( {ps_i} \right) + {\gamma _4}\ln \left( {{I_i}} \right) + {\mu _i} \tag{3.9} \end{equation}\] \[\begin{equation} {Q_i} = {\beta_0} + {\beta_1}{p_i} + {\beta_2}pc_i + {\beta_4}{I_i} + {\varepsilon _i} \tag{3.10} \end{equation}\] \[\begin{equation} {Q_i} = {\beta_0} + {\beta_1}{p_i} + {\beta_2}ps_i + {\beta_4}{I_i} + {\varepsilon _i} \tag{3.11} \end{equation}\]
Una vez estimados estos cuatro modelos se cuentan con su correspondiente \(R^2\). Un “impulso natural” es escoger como el “mejor” modelo aquel que tenga el \(R^2\) más grande. Pero tal procedimiento en este caso es erróneo, pues al comparar el modelo (3.9) con los otros modelos nos damos cuenta que la variable dependiente es diferente en este modelo. Así, aún si se emplee la misma muestra para estimar los modelos, las \(SST\) no serán iguales para todos. La \(SST\) del modelo (3.9) es distinta a la de los otros tres modelos, pues para el modelo (3.9) \(SST = \sum\limits_{i = 1}^n {{{\left( {\ln \left( {{Q_i}} \right) - \ln \left( {\bar Q} \right)} \right)}^2}}\) mientras que para los otros modelos tenemos que \(SST = \sum\limits_{i = 1}^n {{{\left( {{Q_i} - \bar Q} \right)}^2}}\).
Por lo tanto, si comparamos el \(R^2\) del modelo (3.9) con el de los otros tres modelos, no estaríamos comparando la explicación de la misma variabilidad total de la variable dependiente. Podemos concluir que los \(R^2\) entre diferentes modelos son comparables si y solamente si la variable dependiente es la misma en los modelos a comparar y se emplea la misma muestra en la estimación de los modelos.
Pero, aún si comparamos modelos con la misma variable dependiente y la misma muestra, como por ejemplo los modelos (3.8), (3.10) y (3.11), es necesario tener cuidado con esta comparación. Es relativamente fácil mostrar que el SSR, y por tanto el \(R^2\), es una función creciente del número de regresores (\(k-1\)). Por tanto, a medida que consideramos modelos con más variables explicativas, el \(R^2\) será más grande.
Entonces, podríamos escoger cuál modelo explica mayor proporción de la variabilidad de la variable dependiente para los modelos (3.10) y (3.11) por medio del \(R^2\), pues en estos dos modelos se tiene el mismo número de variables explicativas (\(k\)) y la variable explicada es la misma. Pero, en general, el \(R^2\) no es un buen criterio para escoger entre los modelos (3.8), (3.10) y (3.11).
3.3.1 La Tabla ANOVA
Una forma de resumir la descomposición de la variabilidad de la variable dependiente es emplear una tabla conocida como la tabla ANOVA (Analysis of Variance). Esta es una alternativa a la Figura 3.11 que no funcionaría para un modelo con más de dos variables explicativas. Aún en el caso de un modelo con una sola variable dependiente, el análisis gráfico se convierte en una situación inmanejable.
La tabla ANOVA no sólo resume la descomposición de la variabilidad de la variable dependiente, sino que también resume información importante como los grados de libertad asociados con cada suma al cuadrado.
Intuitivamente, noten que para calcular el \(SST = \sum\limits_{i = 1}^n {{{\left( {{y_i} - \bar y} \right)}^2}}\) se emplean \(n\) observaciones y se pierde un grado de libertad al emplear la media, por tanto los grados de libertad del \(SST\) son \(n-1\). Por otro lado, para calcular el \(SSE = \sum\limits_{i = 1}^n {{{\left( {{y_i} - {{\hat y}_i}} \right)}^2}}\) se emplean \(n\) observaciones y se pierde \(k\) grados de libertad al calcular \({\hat y_i}\), por tanto los grados de libertad del \(SSE\) son \(n-k\). Finalmente, así como \(SST = SSE + SSR\), también se debe cumplir que los grados de libertad del \(SST\) deben ser iguales a la suma de los grados de libertad del \(SSE\) y el \(SSR\). Así por diferencia, podemos encontrar que los grados de libertad del \(SSR\) son \(k-1\). Una forma alternativa para llegar a este último resultado es advertir que para calcular \(SSR = \sum\limits_{i = 1}^n {{{\left( {{{\hat y}_i} - \bar y} \right)}^2}}\) se emplean \(k\) grados de libertad en el cálculo de cada \({\hat y_i}\) y se pierde un grado de libertad al emplear la media \({\bar y_i}\), por tanto los grados de libertad del \(SSR\) son \(k-1\).
Finalmente, en la tabla ANOVA se reporta la Media Cuadrada (\(MS\)) de los errores y de la regresión que corresponde a las respectivas Sumas al Cuadrado divididas por sus respectivos grados de libertad. En especial, el \(MS\) correspondiente al error, \(MSE\), es exactamente igual al estimador de la varianza del error. Claramente de la tabla ANOVA, también se puede derivar rápidamente el \(R^2\), pues toda la información necesaria para el cálculo de este estadístico está disponible en la tabla.
| Fuente de la Variación | \(SS\) | Grados de libertad | \(MS\) |
|---|---|---|---|
| Regresión | \(SSR\) | \(k-1\) | \(MSR = SSR / (n-k)\) |
| Error | \(SSE\) | \(n-k\) | \(MSE = {s^2} = SSE/(n - k)\) |
| Total | \(SST\) | \(n-1\) | |
| Fuente: elaboración propia. |
3.4 Pruebas conjuntas sobre los parámetros
Hasta aquí hemos discutido cómo comprobar hipótesis individuales en torno a cada uno de los parámetros de un modelo de regresión. Pero, ¿qué hacer con estos resultados individuales? Supongamos la siguiente situación; hemos estimado con una muestra lo suficientemente grande el siguiente modelo: \[\begin{equation*} y_i = \beta_1 +\beta_2 X_{2i} + \beta_3 X_{3i} + \beta_4 X_{4i} + \varepsilon _i \end{equation*}\] Además, suponga que hemos efectuado una serie de pruebas individuales sobre los parámetros estimados y se ha encontrado que:
- La hipótesis nula \({\beta_2} = 0\) es rechazada a un nivel de significancia de \(\alpha\). Llamemos a este el resultado 1 (\(R_1\))
- La hipótesis nula \({\beta_3} = 0\) no se puede rechazar a un nivel de significancia de \(\alpha\). (\(R_2\))
- La hipótesis nula \({\beta_4} = 0\) no se puede rechazar a un nivel de significancia de \(\alpha\). (\(R_3\))
Dados estos tres resultados, parece muy razonable tratar de unir estos tres resultados (\({R_1} \cup {R_2} \cup {R_3}\)) y concluir que el modelo debería ser \({y_i} = {\beta_1} + {\beta_2}{X_{2i}} + {\varepsilon _i}\) con un nivel de significancia de \(\alpha\). Pero si reflexionamos un poco sobre las implicaciones de unir estos resultados, nos daremos cuenta rápidamente lo errado de unirlos. Noten que el primer resultado \(R_1\) implica un error tipo I de tamaño \(\alpha\), mientras que los resultados \(R_2\) y \(R_3\) tienen asociados un error tipo II. Ahora, si unimos estos tres resultados, el nivel de significancia asociado a (\({R_1} \cup {R_2} \cup {R_3}\)) no será simplemente \(\alpha\).
Para evitar ser muy conservador al unir diferentes resultados individuales, se han diseñado pruebas que tengan en cuenta estos múltiples errores. Tales pruebas se conocen como pruebas conjuntas. En esta sección las discutiremos en detalle.
Supongamos que usted quiere determinar si todos los coeficientes asociados a pendientes son o no iguales a cero conjuntamente; es decir, \({H_0}:{\beta_2} = {\beta_3} = ... = {\beta_k} = 0\) versus la hipótesis alterna no \(H_0\). Como lo discutimos anteriormente, este tipo de hipótesis no se puede probar con \(k-1\) hipótesis individuales. Noten que esta hipótesis puede reescribirse de la forma \({\bf R_{\left( {r} \right) \times k}}{\beta_{k \times 1}} = {\bf C_{\left( {r} \right) \times 1}}\), donde \({\beta ^T} = \left[ {\begin{array}{*{20}{c}} {{\beta_1}} & {{\beta_2}} & {...} & {{\beta_k}} \\ \end{array}} \right]\), \({\bf C^T} = \left[ {\begin{array}{*{20}{c}} 0 & 0 & {...} & 0 \\ \end{array}} \right]\) y \[\begin{equation*} {R_{\left( {r - 1} \right) \times k}} = \left[ {\begin{array}{*{20}{c}} 0 & 1 & 0 & \ldots & 0 \\ 0 & 0 & 1 & \ldots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \ldots & 1 \\ \end{array}} \right] \end{equation*}\]
Ahora, supongamos que quiere saber si dada una estimación se cumple una restricción que tiene sentido teórico. Por ejemplo, se desea emplear una función de producción Cobb-Douglas para determinar si se presenta rendimientos constantes de escala o no. Es decir, dada la siguiente ecuación estimada \(\widehat{\ln \left( Y_i \right)} = \hat \beta + {\hat \alpha _1}\ln \left( {K_i} \right) + {\hat \alpha _2}\ln \left( {L_i} \right)\) se quiere comprobar si \(\alpha _1 + \alpha _2\) es igual a uno o no. Esta hipótesis también se puede escribir de la forma \({\bf R_{\left( {r} \right) \times k}}{\beta_{k \times 1}} = {\bf C_{\left( {r} \right) \times 1}}\), donde \({\beta ^T} = \left[ {\begin{array}{*{20}{c}} \beta & {{\alpha _1}} & {{\alpha _2}} \\ \end{array}} \right], \: R = \left[ {\begin{array}{*{20}{c}} 0 & 1 & 1 \\ \end{array}} \right]\) y \(C = \left[ 1 \right]\).
En general, cualquier hipótesis nula que pueda escribirse de la forma \({R_{\left( {r} \right) \times k}}{\beta_{k \times 1}} = {C_{\left( {r} \right) \times 1}}\) (versus la \(H{_a}\): no \(H_0\)) se puede comprobar empleando el siguiente estadístico: \[\begin{equation} F_{calculado} = \frac{\left( \bf C -\bf R \hat \beta \right)^T \left( \bf R \left( \bf X^T \bf X \right)^{-1} \bf R ^T \right)\left( \bf C -\bf R \hat \beta \right)/r}{\hat \varepsilon ^T \hat \varepsilon / (n-k)} \tag{3.12} \end{equation}\] Este estadístico sigue una distribución F con \(r\) grados de libertad en el numerador y \(n-k\) grados de libertad en el denominador. Por tanto, se podrá rechazar la hipótesis nula, con un nivel de significancia \(\alpha\) si \({F_{\alpha ,(r,(n - k))}} < {F_{Calculado}}\).
Un caso especial de la hipótesis nula general \({R_{\left( {r} \right) \times k}}{\beta_{k \times 1}} = {C_{\left( {r} \right) \times 1}}\) (versus la \(H{_a}\): no \(H_0\)) es \({H_0}:{\beta_2} = {\beta_3} = ... = {\beta_k} = 0\) (todos los coeficientes asociados con pendientes son simultáneamente iguales a cero), es decir una prueba global de significancia. En este caso especial el estadístico \({F_{calculado}}\) se reduce a: \[\begin{equation} F_{calculado} = \frac{\hat \beta ^T{{\bf{X}}^{\bf{T}}}{\bf{y}} - n{{\bf{\bar y}}^2}/(k-1)}{\hat \varepsilon ^T \hat \varepsilon / (n-k)}=\frac{MSR}{MSE} \tag{3.13} \end{equation}\] O de manera equivalente: \[\begin{equation} {F_{Global}} = \frac{R^2 / (k - 1) } {\left( 1 - R^2 \right) /(n - k)} \tag{3.14} \end{equation}\] Este \({F_{Global}}\) sigue una distribución F con \(k-1\) grados de libertad en el numerador y \(n-k\) grados de libertad en el denominador. Por tanto, se podrá rechazar la hipótesis nula a un nivel de significancia \(\alpha\) si \({F_{\alpha ,(\left( {k - 1} \right),(n - k))}} < {F_{Global}}\). Noten que este test se puede derivar rápidamente de la tabla ANOVA como se muestra en el Cuadro 3.3).
| Fuente de la Variación | \(SS\) | Grados de libertad | \(MS\) | F-Global |
|---|---|---|---|---|
| Regresión | \(SSR\) | \(k-1\) | \(MSR = SSR / (n-k)\) | \({F_{Global}} = MSR/MSE\) |
| Error | \(SSE\) | \(n-k\) | \(MSE = {s^2} = SSE/(n - k)\) | |
| Total | \(SST\) | \(n-1\) | ||
| Fuente: elaboración propia. |
Noten que la hipótesis nula de esta prueba de significancia global implica el modelo : \[\begin{equation} {y_i} = {\beta_1} + {\varepsilon _i} \tag{3.15} \end{equation}\] mientras que la hipótesis alterna implica el modelo: \[\begin{equation} {y_i} = {\beta_1} + {\beta_2}{X_{2i}} + {\beta_3}{X_{3i}} + \ldots + {\beta_k}{X_{ki}} + {\varepsilon _i} \tag{3.16} \end{equation}\] Es decir, si la hipótesis nula no es rechazada, esto implica que una mejor forma de explicar la variable dependiente es por medio de su media (una constante)38. Por tanto, esta prueba es otra forma de estudiar la bondad de ajuste del modelo, por eso no debe ser sorprendente la estrecha relación entre el \(F_{Global}\) y el \(R_2\) como se muestra en (3.14).
3.5 Prueba de Wald y su relación con la prueba F
En la sección anterior se discutió cómo para comprobar una hipótesis nula que involucre restricciones lineales de la forma \({\bf{R}}\hat \beta = {\bf{C}}\) podemos emplear el estadístico \(F_{calculado}\) que se presenta en (3.12). Una alternativa para probar hipótesis que involucren restricciones de la forma \({\bf{R}}\hat \beta = {\bf{C}}\) es emplear el estadístico de Wald (\(W_{calculado}\)), el cual está relacionado con el \(F_{calculado}\) descrito con anterioridad. Este estadístico se puede calcular con la siguiente expresión: \[\begin{equation} W_{calculado} = \left( {{\bf{C}} - {\bf{R}}\hat \beta } \right)^T \left( {{\bf{R}}\left( {S^2 \bf X^T X} \right)^{ - 1} {\bf{R}}^{\bf T} } \right)^{ - 1} \left( {{\bf{C}} - {\bf{R}}\hat \beta } \right) \tag{3.17} \end{equation}\]
El estadístico de Wald calculado sigue una distribución \(\chi _r^2\) donde \(r\) representa el número de restricciones lineales en la hipótesis nula. Por tanto, se podrá rechazar \(H_0 :{\bf{R}}\beta = {\bf{C}}\) en favor de la hipótesis alterna (no \(H_0\)) si \(W_{calculado} > \chi _r^2\).
Es muy fácil encontrar la relación entre el estadístico de Wald y el estadístico F. Por ejemplo, manipulando algebraicamente (3.17) tendremos que:
\[\begin{equation} W_{calculado} = \left( {{\bf{C}} - {\bf{R}}\hat \beta } \right)^T \left( {{\bf{R}}\left( {\bf X^T X} \right)^{ - 1} \bf R^T } \right)^{ - 1} \left( {{\bf{C}} - {\bf{R}}\hat \beta } \right)\left( {S^2 } \right)^{ - 1} \tag{3.18} \end{equation}\]
\[\begin{equation} W_{calculado} = \frac{{\left( {{\bf{C}} - {\bf{R}}\hat \beta } \right)^T \left( {{\bf{R}}\left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} {\bf{R}}^{\bf T} } \right)^{ - 1} \left( {{\bf{C}} - {\bf{R}}\hat \beta } \right)}}{{S^2 }} \tag{3.19} \end{equation}\]
y reemplazando \(S^2\) tenemos que:
\[\begin{equation} W_{calculado} = \frac{{\left( {{\bf{C}} - {\bf{R}}\hat \beta } \right)^T \left( {{\bf{R}}\left( {{\bf{X}}^{\bf T} {\bf{X}}} \right)^{ - 1} {\bf{R}}^{\bf T} } \right)^{ - 1} \left( {{\bf{C}} - {\bf{R}}\hat \beta } \right)}}{\hat \varepsilon^T \hat \varepsilon / (n - k) } \tag{3.20} \end{equation}\]
Al comparar la anterior expresión con ((3.12) se puede concluir que \(W_{calculado} = r \cdot F_{calculado}\). De hecho, para comprobar cualquier hipótesis que involucre restricciones lineales de la forma \({\bf{R}}\hat \beta = {\bf{C}}\) se podrá emplear una prueba F o una prueba Wald. Sin importar el estadístico que se emplee, la conclusión será la misma. Finalmente, esta prueba de Wald se puede calificar como una versión abreviada de una prueba de la razón de verosimilitud (Likelihood Ratio Test).
3.6 Práctica en R: Explicando los rendimientos de una acción
En esta sección aplicaremos los conceptos cubiertos hasta ahora. En esta ocasión en el área financiera de una organización se esta evaluando la inversión de algunos excedentes de tesorería en acciones del grupo SURA. Así, en el equipo de trabajo surgió la siguiente pregunta de negocio: ¿Cómo está relacionado el rendimiento de esta acción con el rendimiento de aquellas acciones en la que ya tenemos inversiones? Esta pregunta nace, pues se quiere diversificar el riesgo del portafolio. Para responder esta pregunta se cuenta con datos del rendimiento diario39 de la acción de Suramericana y de otras acciones que también se tranzan en la Bolsa de Valores de Colombia y ya están en el portafolio de la organización. La base de datos contiene rendimientos diarios de las siguientes acciones: GRUPOSURA, ECOPETROL, NUTRESA, EXITO, ISA, GRUPOAVAL, CONCONCRETO, VALOREM y OCCIDENTE. La base de datos va desde 2012-01-02 hasta el 2019-01-14 y y todas las variables están medidas en puntos porcentuales. La base se encuentra en el archivo RetornosDiarios.RData40.
La primera tarea como siempre será cargar los datos, para lo cual se puede emplear la función load() que se encuentra en el paquete base de R. El argumento mas importante para esta función es el nombre del archivo y su respectiva ruta.
El working space cargado contiene el objeto retornos.diarios. Miremos la clase de dicho objeto.
## [1] "xts" "zoo"Este objeto es de clase xts y zoo. Este tipo de clase es muy empleada cuando se trabaja con series de tiempo; en especial la clase xts es útil cuando las series tienen una frecuencia inferior al mes, como en este caso que tenemos datos diarios. Esta clase corresponde al paquete xts (Ryan & Ulrich, 2020). Carguemos la librería (de ser necesario instale el paquete) y asegurémonos que los datos quedaron bien cargados y que cada variable se encuentre bien definida.
# Instalar paquete si es necesario install.packages('xts)
# Cargar paquete
library(xts)
# Chequeo de los primeros datos y de la clase
head(retornos.diarios, 2)## GRUPOSURA ECOPETROL NUTRESA EXITO ISA GRUPOAVAL
## 2012-01-02 1.277973 -0.3565066 -0.9216655 2.02184181 -1.983834 0.000000
## 2012-01-03 2.507968 2.0036027 -0.2781643 0.07695268 1.626052 -2.429269
## CONCONCRET VALOREM OCCIDENTE
## 2012-01-02 0 0.0000 0
## 2012-01-03 0 12.5839 0## An xts object on 2012-01-02 / 2019-01-14 containing:
## Data: double [1696, 9]
## Columns: GRUPOSURA, ECOPETROL, NUTRESA, EXITO, ISA ... with 4 more columns
## Index: Date [1696] (TZ: "UTC")## GRUPOSURA ECOPETROL NUTRESA EXITO ISA GRUPOAVAL CONCONCRET VALOREM
## [1,] "xts" "xts" "xts" "xts" "xts" "xts" "xts" "xts"
## [2,] "zoo" "zoo" "zoo" "zoo" "zoo" "zoo" "zoo" "zoo"
## OCCIDENTE
## [1,] "xts"
## [2,] "zoo"Noten que este objeto de clase xts reacciona un poco diferente a los objetos de clase data.frame a funciones como str() . Pero la mayoría de las funciones que operan sobre objetos de clase data frame también funcionarán sobre objetos xts y zoo. En especial la función lm() no tendrá ningún problema con este tipo de objetos. Para tener una idea de la base de datos antes de entrar a estimar el modelo, veamos su periodicidad (función periodicity() ), las estadísticas descriptivas, un gráfico y la correlación entre las series.
## Daily periodicity from 2012-01-02 to 2019-01-14## Index GRUPOSURA ECOPETROL
## Min. :2012-01-02 Min. :-5.491576 Min. :-10.44520
## 1st Qu.:2013-09-25 1st Qu.:-0.605399 1st Qu.: -0.96271
## Median :2015-06-30 Median : 0.000000 Median : 0.00000
## Mean :2015-07-04 Mean : 0.002958 Mean : -0.02184
## 3rd Qu.:2017-04-07 3rd Qu.: 0.679216 3rd Qu.: 1.00884
## Max. :2019-01-14 Max. : 5.671623 Max. : 10.27128
## NUTRESA EXITO ISA
## Min. :-7.145896 Min. :-13.35314 Min. :-15.20399
## 1st Qu.:-0.525538 1st Qu.: -0.76845 1st Qu.: -0.75520
## Median : 0.000000 Median : 0.00000 Median : 0.00000
## Mean : 0.004678 Mean : -0.03991 Mean : 0.01399
## 3rd Qu.: 0.528802 3rd Qu.: 0.73004 3rd Qu.: 0.85536
## Max. : 4.807793 Max. : 8.02808 Max. : 10.48256
## GRUPOAVAL CONCONCRET VALOREM
## Min. :-9.143421 Min. :-27.44368 Min. :-11.65338
## 1st Qu.:-0.722025 1st Qu.: -0.44445 1st Qu.: 0.00000
## Median : 0.000000 Median : 0.00000 Median : 0.00000
## Mean :-0.007806 Mean : -0.07761 Mean : 0.07358
## 3rd Qu.: 0.719428 3rd Qu.: 0.36597 3rd Qu.: 0.00000
## Max. : 7.696104 Max. : 11.46629 Max. : 29.02523
## OCCIDENTE
## Min. :-12.84562
## 1st Qu.: 0.00000
## Median : 0.00000
## Mean : 0.01409
## 3rd Qu.: 0.00000
## Max. : 9.72907Todas las series de los rendimientos tienen mediana cero y son relativamente volátiles. Esto se puede corroborar gráficamente. Grafiquemos las series empleando la función plot.xts() del paquete xts (Ryan & Ulrich, 2020). Al emplear la plot() sobre un objeto de clase xts automáticamente emplea la función plot.xts().
Figura 3.12: Retorno diario de las acciones seleccionadas
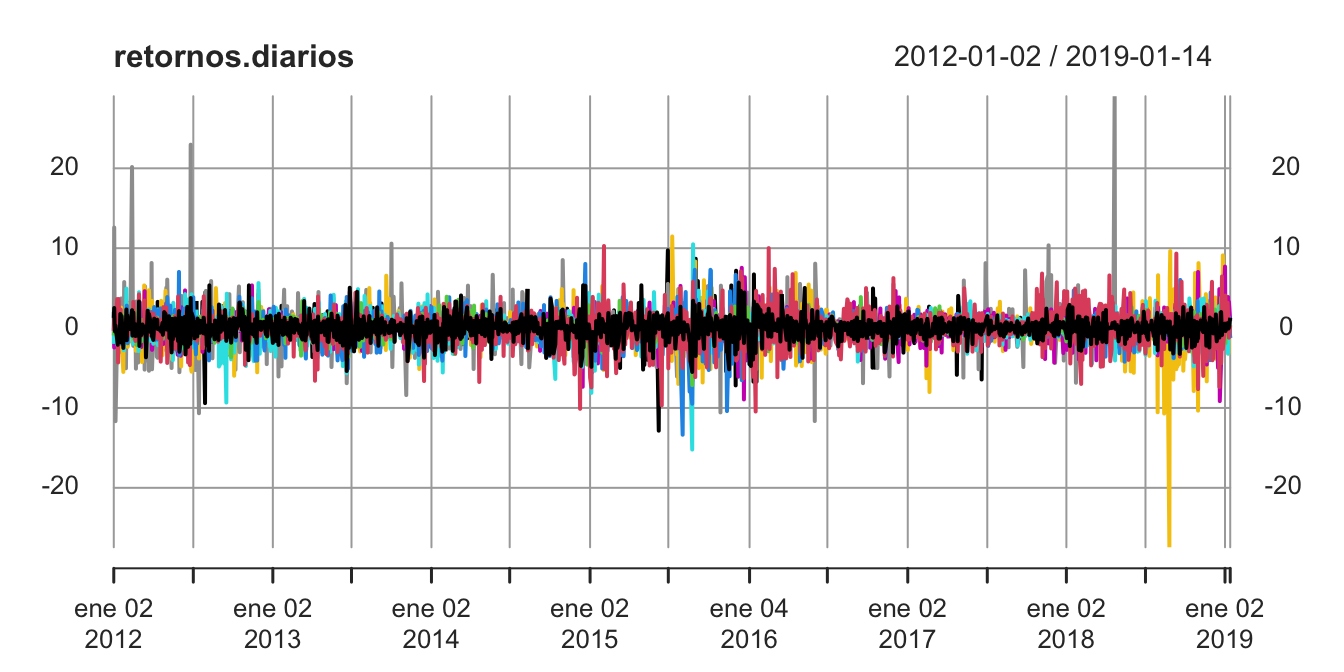
En la Figura 3.12 se presenta la visualización obtenida.
Claramente las series (variables) de los rendimientos son bastante volátiles41. Ahora procedamos a estimar el siguiente modelo de regresión: \[\begin{gathered} {\text{GRUPOSUR}}{{\text{A}}_t} = {\beta_1} + {\beta_2}{\text{ECOPETRO}}{{\text{L}}_t} + {\beta_3}{\text{NUTRES}}{{\text{A}}_t} \hfill \\ {\text{ }} + {\beta_4}{\text{EXIT}}{{\text{O}}_t} + {\beta_5}{\text{IS}}{{\text{A}}_t} + {\beta_7}{\text{GRUPOAVA}}{{\text{L}}_t} \hfill \\ {\text{ }} + {\beta_8}{\text{CONCONCRET}}{{\text{O}}_t} + {\beta_9}{\text{VALORE}}{{\text{M}}_t} \hfill \\ {\text{ }} + {\beta_{10}}{\text{OCCIDENT}}{{\text{E}}_t} + {\varepsilon _t}, \hfill \\ \end{gathered} \]
donde \(\text{GRUPOSUR}{\text{A}}_t\) representa el rendimiento diario de la acción del Grupo Sura. De manera análoga las otras variables representan los rendimientos de las otras acciones. En el capítulo anterior discutimos como estimar un modelo lineal. En este caso el modelo se puede estimar y visualizar de la siguiente manera:
##
## Call:
## lm(formula = GRUPOSURA ~ ., data = retornos.diarios)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.6534 -0.5737 -0.0133 0.6199 6.3444
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.006431 0.027001 0.238 0.812
## ECOPETROL 0.121058 0.014487 8.357 < 2e-16 ***
## NUTRESA 0.141435 0.027796 5.088 4.02e-07 ***
## EXITO 0.122278 0.018116 6.750 2.03e-11 ***
## ISA 0.188165 0.018689 10.068 < 2e-16 ***
## GRUPOAVAL 0.084403 0.020077 4.204 2.76e-05 ***
## CONCONCRET 0.021189 0.014785 1.433 0.152
## VALOREM 0.035659 0.014007 2.546 0.011 *
## OCCIDENTE 0.030972 0.026930 1.150 0.250
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.109 on 1687 degrees of freedom
## Multiple R-squared: 0.2617, Adjusted R-squared: 0.2582
## F-statistic: 74.75 on 8 and 1687 DF, p-value: < 2.2e-16R emplea una manera particular en poner asteriscos que no concuerda con la literatura científica (por lo menos en las ciencias sociales). En el Cuadro 3.4 se presenta la equivalencia entre lo reportado en R y la literatura.
| p valor < | en R | en literatura |
|---|---|---|
| 0.1 | . |
|
| 0.05 |
|
** |
| 0.01 | ** | *** |
| 0,001 | *** | No se emplea |
| Fuente: elaboración propia. |
Los resultados de la estimación del modelo se resumen en el Cuadro 3.5 empleando la aproximación tradicional de la literatura.
| (Intercept) | 0.01 |
| (0.03) | |
| ECOPETROL | 0.12*** |
| (0.01) | |
| NUTRESA | 0.14*** |
| (0.03) | |
| EXITO | 0.12*** |
| (0.02) | |
| ISA | 0.19*** |
| (0.02) | |
| GRUPOAVAL | 0.08*** |
| (0.02) | |
| CONCONCRET | 0.02 |
| (0.01) | |
| VALOREM | 0.04* |
| (0.01) | |
| OCCIDENTE | 0.03 |
| (0.03) | |
| R2 | 0.26 |
| Adj. R2 | 0.26 |
| Num. obs. | 1696 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Los resultados muestran que los rendimientos de las acciones de ECOPETROL, NUTRESA, EXITO, ISA, GRUPOAVAL y VALOREM son variables significativas para explicar el rendimiento de la acción de GRUPOSURA. Las pruebas individuales de significancia permiten concluir que los rendimientos de las acciones de CONCONCRETO y OCCIDENTE no tienen efecto sobre el rendimiento de la acción de GRUPOSURA.
También podemos observar que el \(R^2\) de la regresión es 0.262. Esto quiere decir que el modelo explica el 26.2% de la variación del rendimiento de la acción de GRUPOSURA. Noten que si bien parece pequeño este \(R^2\), no lo es. Dado que los rendimientos de la acción de GRUPOSURA es tan volátil (cambia tanto), explicar el 26.2% de esta variación no es despreciable. En el contexto de las finanzas, este \(R^2\) no es bajo.
Es importante tener en cuenta que en otras aplicaciones este \(R^2\) puede ser considerado como muy bajo. Por eso es importante, conocer el contexto bajo estudio para poder determinar si un \(R^2\) obtenido es relativamente alto o bajo para el caso bajo estudio.
Por otro lado, el \(F_{Global}\) es 74.748. El respectivo p-valor (aproximadamente 0) implica que se puede rechazar la hipótesis nula de que ninguna variable es importante para explicar los rendimientos de la acción de GRUPOSURA. Es decir, al menos una de las pendientes es diferente de cero.
Para el cálculo de la tabla ANOVA podemos emplear la función anova() del paquete principal de R. El único argumento necesario, por ahora, es el objeto clase lm que tenga los resultados de la regresión.
## Analysis of Variance Table
##
## Response: GRUPOSURA
## Df Sum Sq Mean Sq F value Pr(>F)
## ECOPETROL 1 278.82 278.820 226.5073 < 2.2e-16 ***
## NUTRESA 1 159.09 159.086 129.2379 < 2.2e-16 ***
## EXITO 1 126.82 126.815 103.0217 < 2.2e-16 ***
## ISA 1 136.45 136.453 110.8514 < 2.2e-16 ***
## GRUPOAVAL 1 22.65 22.648 18.3989 1.893e-05 ***
## CONCONCRET 1 2.63 2.626 2.1335 0.14430
## VALOREM 1 8.02 8.019 6.5147 0.01079 *
## OCCIDENTE 1 1.63 1.628 1.3227 0.25027
## Residuals 1687 2076.62 1.231
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Noten que en este caso el SSR se presenta discriminado para cada variable.
3.7 Pruebas conjuntas sobre los parámetros
Ahora, consideremos la prueba conjunta de que las acciones de CONCONCRETO y OCCIDENTE no tienen efecto sobre el rendimiento de la acción de GRUPOSURA. Es decir, \[\begin{equation*} {H_0}:{\beta_8} = {\beta_{10}} = 0 \end{equation*}\]
La hipótesis alterna es no \(H_0\). Esta hipótesis nace de los resultados de las pruebas individuales. Este tipo de restricciones se puede probar tanto con la prueba de Wald como con una prueba \(F\). Esto se puede hacer de la siguiente manera empleando la función linearHypothesis() que se encuentra en el paquete AER (Kleiber & Zeileis, 2008). Esta función requiere al menos dos argumentos: El modelo (objeto clase lm) y las restricciones. La función calcula por defecto la prueba F. Si se desea obtener el estadístico de Wald, entonces se requiere un tercer argumento test=‘’Chisq’’. Las siguientes líneas de código efectúan la respectiva prueba F y de Wald:
# Instalar paquete si no se tiene install.packages('AER')
# Cargar paquete
library(AER)
# Realizar prueba F
linearHypothesis(res1, c("CONCONCRET = 0", "OCCIDENTE = 0"))## Linear hypothesis test
##
## Hypothesis:
## CONCONCRET = 0
## OCCIDENTE = 0
##
## Model 1: restricted model
## Model 2: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + CONCONCRET +
## VALOREM + OCCIDENTE
##
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 1689 2080.8
## 2 1687 2076.6 2 4.1357 1.6799 0.1867# Realizarprueba Wald test='Chisq'
linearHypothesis(res1, test = "Chisq", c("CONCONCRET = 0", "OCCIDENTE = 0"))## Linear hypothesis test
##
## Hypothesis:
## CONCONCRET = 0
## OCCIDENTE = 0
##
## Model 1: restricted model
## Model 2: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + CONCONCRET +
## VALOREM + OCCIDENTE
##
## Res.Df RSS Df Sum of Sq Chisq Pr(>Chisq)
## 1 1689 2080.8
## 2 1687 2076.6 2 4.1357 3.3597 0.1864Como se esperaba, el p-valor de ambas pruebas es el mismo. En este caso, no se puede rechazar la hipótesis nula; es decir, se puede concluir que los rendimientos de las acciones de CONCONCRETO y OCCIDENTE no tienen efecto sobre el rendimiento de la acción de GRUPOSURA. Así el nuevo modelo será: \[\begin{gathered} {\text{GRUPOSUR}}{{\text{A}}_t} = {\beta_1} + {\beta_2}{\text{ECOPETRO}}{{\text{L}}_t} + {\beta_3}{\text{NUTRES}}{{\text{A}}_t} \hfill \\ {\text{ }} + {\beta_4}{\text{EXIT}}{{\text{O}}_t} + {\beta_5}{\text{IS}}{{\text{A}}_t} + {\beta_7}{\text{GRUPOAVA}}{{\text{L}}_t} \hfill \\ {\text{ }} + {\beta_9}{\text{VALORE}}{{\text{M}}_t} + {\varepsilon _t}. \hfill \\ \end{gathered} \]
El nuevo modelo42 y el anterior se presentan en el Cuadro 3.6.
| Model 1 | Model 2 | |
|---|---|---|
| (Intercept) | 0.01 | 0.01 |
| (0.03) | (0.03) | |
| ECOPETROL | 0.12*** | 0.12*** |
| (0.01) | (0.01) | |
| NUTRESA | 0.14*** | 0.14*** |
| (0.03) | (0.03) | |
| EXITO | 0.12*** | 0.12*** |
| (0.02) | (0.02) | |
| ISA | 0.19*** | 0.19*** |
| (0.02) | (0.02) | |
| GRUPOAVAL | 0.08*** | 0.09*** |
| (0.02) | (0.02) | |
| CONCONCRET | 0.02 | |
| (0.01) | ||
| VALOREM | 0.04* | 0.04* |
| (0.01) | (0.01) | |
| OCCIDENTE | 0.03 | |
| (0.03) | ||
| R2 | 0.26 | 0.26 |
| Adj. R2 | 0.26 | 0.26 |
| Num. obs. | 1696 | 1696 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
Ahora, noten que en este segundo modelo los coeficientes que acompañan los rendimientos de las acciones de ECOPETROL y EXITO parecen “a ojo” ser similares. Entonces probemos si realmente son iguales o no. Es decir, la hipótesis nula será: \[\begin{equation*} {H_0}:{\beta_2} = {\beta_4} = 0.12 \end{equation*}\] versus la hipótesis alterna de no \(H_0\). En este caso el código será:
## Linear hypothesis test
##
## Hypothesis:
## ECOPETROL = 0.12
## EXITO = 0.12
##
## Model 1: restricted model
## Model 2: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + VALOREM
##
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 1691 2080.8
## 2 1689 2080.8 2 0.046964 0.0191 0.9811# prueba Wald test='Chisq'
linearHypothesis(res2, test = "Chisq", c("ECOPETROL = 0.12", "EXITO = 0.12"))## Linear hypothesis test
##
## Hypothesis:
## ECOPETROL = 0.12
## EXITO = 0.12
##
## Model 1: restricted model
## Model 2: GRUPOSURA ~ ECOPETROL + NUTRESA + EXITO + ISA + GRUPOAVAL + VALOREM
##
## Res.Df RSS Df Sum of Sq Chisq Pr(>Chisq)
## 1 1691 2080.8
## 2 1689 2080.8 2 0.046964 0.0381 0.9811Esto implica que la hipótesis nula no se puede rechazar. Es decir, se puede concluir que el efecto de un aumento de un punto porcentual en el rendimiento de las acciones de ECOPETROL o EXITO tiene el mismo efecto sobre la acción de GRUPOSURA. Es más, dicho efecto no es estadísticamente diferente de 0.12 puntos porcentuales.
Finalmente, noten que el intercepto del modelo no es significativo. No obstante, no removeremos nunca el intercepto de un modelo para mantener las propiedades estadísticas del modelo y poder interpretar el \(R^2\).
Recordemos que la pregunta de negocio que queríamos responder es: ¿cómo está relacionado el rendimiento de la acción de SURA con el rendimiento de aquellas acciones en la que ya tenemos inversiones? Nuestros resultados permiten concluir que el rendimiento de la acción de SURA tienen relación con los rendimientos de las acciones de ECOPETROL, NUTRESA, EXITO, ISA, GRUPOAVAL y VALOREM.
Para terminar, interpretemos los coeficientes.
- Intercepto: Si el rendimiento de las otras acciones fuesen cero, entonces el rendimiento de la acción de SURA será cero.
- Por cada punto porcentual43 (p.p.) que aumente el rendimiento de la acción de ECOPETROL, el rendimiento de la acción de SURA aumentará en 0.12 pp.
- Por cada punto porcentual (p.p.) que aumente el rendimiento de la acción de NUTRESA, el rendimiento de la acción de SURA aumentará en 0.14 pp.
- Por cada punto porcentual (p.p.) que aumente el rendimiento de la acción de EXITO, el rendimiento de la acción de SURA aumentará en 0.12 pp.
- Por cada punto porcentual (p.p.) que aumente el rendimiento de la acción de ISA, el rendimiento de la acción de SURA aumentará en 0.19 pp.
- Por cada punto porcentual (p.p.) que aumente el rendimiento de la acción de GRUPOAVAL, el rendimiento de la acción de SURA aumentará en 0.09 pp.
- Por cada punto porcentual (p.p.) que aumente el rendimiento de la acción de VALOREM, el rendimiento de la acción de SURA aumentará en 0.04 pp.
3.8 Anexo: Demostración de la ecuación (3.8)
La expresión (3.7) implica que en presencia de un modelo lineal con intercepto, podremos descomponer la variación total de la variable dependiente (\(SST\)) en la parte explicada por el modelo de regresión (\(SSR\)) y la parte no explicada por el modelo (\(SSE\)). Formalmente, la proposición a probar es que si una de las variables explicativas es una constante (corresponde al intercepto), entonces: \[\begin{equation*} SST = SSR + SSE. \end{equation*}\] Para demostrar esta proposición, podemos partir del hecho que: \[\begin{equation*} \hat \varepsilon ^T \hat \varepsilon = \left( {y - {\mathbf{X}}\hat \beta } \right)^T \left( {y - {\mathbf{X}}\hat \beta } \right) \end{equation*}\] \[\begin{equation*} \hat \varepsilon ^T \hat \varepsilon = y^T y - 2\hat \beta ^T {\mathbf{X}}^T y + \hat \beta ^T {\mathbf{X}}^T {\mathbf{X}}\hat \beta \end{equation*}\]
\[\begin{equation*} \hat \varepsilon ^T \hat \varepsilon = y^T y - \hat \beta ^T {\mathbf{X}}^T {\mathbf{X}}\hat \beta . \end{equation*}\] Reemplazando, obtenemos \[\begin{equation*} y^T y = \hat \varepsilon ^T \hat \varepsilon + \hat y^T \hat y. \end{equation*}\] Restando a ambos lados \(n\bar y^2\), se obtiene: \[\begin{equation*} y^T y - n\bar y^2 = \hat \varepsilon ^T \hat \varepsilon - n\bar y^2 + \hat y^T \hat y. \end{equation*}\] En otras palabras, tenemos que: \[\begin{equation*} SST = SSE + \hat y^T \hat y - n\bar y^2 . \end{equation*}\]
Ahora, será necesario demostrar que \(SSR = \hat y^T \hat y - n\bar y^2\) siempre que el modelo lineal incluya un intercepto. Noten que: \[\begin{equation*} SSR = \sum\limits_{i = 1}^n {\left( {\hat y_i - \bar y} \right)^2 } = \sum\limits_{i = 1}^n {\hat y_i^2 } - 2\sum\limits_{i = 1}^n {\hat y_i \bar y} + \sum\limits_{i = 1}^n {\bar y^2 } \end{equation*}\] \[\begin{equation*} SSR = \hat y^T \hat y - 2\bar y\sum\limits_{i = 1}^n {\hat y_i } + n\bar y^2 . \end{equation*}\] Reemplazando el valor estimado de la variable dependiente, se tiene que: \[\begin{equation*} SSR = \hat y^T \hat y - 2\bar y\sum\limits_{i = 1}^n {\left( {y_i - \hat \varepsilon _i } \right)} + n\bar y^2 \end{equation*}\] \[\begin{equation*} SSR = \hat y^T \hat y - 2\bar y\left[ {\sum\limits_{i = 1}^n {y_i } - \sum\limits_{i = 1}^n {\hat \varepsilon _i } } \right] + n\bar y^2 \end{equation*}\]
\[\begin{equation*} SSR = \hat y^T \hat y - 2\bar yn\bar y + 2\bar y\sum\limits_{i = 1}^n {\hat \varepsilon _i } + n\bar y^2 . \end{equation*}\] Recordemos que si uno de los regresores es una constante, entonces ya se demostró que siempre se cumplirá que \(\sum\limits_{i = 1}^n {\hat \varepsilon _i } = 0\). Por eso,
\[\begin{equation*} SSR = \hat y^T \hat y - 2n\bar y^2 + n\bar y^2 \end{equation*}\]
\[\begin{equation*} SSR = \hat y^T \hat y - n\bar y^2 . \end{equation*}\]
Es decir, se tiene que:
\[\begin{equation*} SST = SSE + SSR. \end{equation*}\]
Es importante anotar que si no se garantiza que \(\sum\limits_{i = 1}^n {\hat \varepsilon _i } = 0\), entonces no necesariamente se puede garantizar que la suma del \(SSR\) y el \(SSE\) sean iguales al \(SST\). Y esto solo se puede asegurar cuando el modelo estimado tiene un intercepto.
Referencias
En este caso emplearemos un bucle (loop) para replicar este cálculo. Una breve introducción a los Loops en R se puede encontrar en Alonso (2021).↩︎
Dado que una distribución \(\chi^2\) con \(g\) grados de libertad tiene como media sus grados de libertad, le restamos a cada valor generado aleatoriamente su media para centrar los errores y cumplir el supuesto del error.↩︎
Por una cola pesada se entiende una probabilidad más alta de estar en las colas.↩︎
Noten que partimos de la desviación de dada observación con respecto a su media y la denominamos variación total, pues esta sería la desviación que tendría cada observación con respecto a lo esperado si usásemos el modelo más sencillo para explicar el comportamiento de una variable. Es decir, si usamos el modelo \(y_i = \mu + \varepsilon _i\). este será nuestro modelo de partida.↩︎
\({\hat y_i} = {\hat \beta_1} + {\hat \beta_2}{X_{2i}} + {\hat \beta_3}{X_{3i}} + \ldots + {\hat \beta_k}{X_{ki}}\) para \(i=1,2,...,n\), o en forma matricial \(\hat y = X\hat \beta\).↩︎
En el Anexo 3.8 al final de este capítulo se presenta una demostración de esta afirmación.↩︎
Es decir \({Y_i} = \mu + {\varepsilon _i}\), donde \(\mu = {\beta_1}\) es la media.↩︎
El rendimiento diario se calcula como el crecimiento porcentual en el precio de la acción.↩︎
Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/↩︎
Esta es una característica común en los rendimientos de las acciones. Para una mayor discusión ver Alonso (2006a) y Alonso & Torres (2014).↩︎
El nuevo modelo lo nombraremos
res2.↩︎Nota que no es lo mismo un aumento de un uno por ciento que un aumento de un punto porcentual. Ten cuidado con esta diferencia al momento de interpretar coeficientes asociados con variables que están medidas en puntos porcentuales.↩︎