7 Primer caso de negocio
Objetivos del capítulo
El lector, al finalizar este capítulo, estará en capacidad de:
- Emplear las herramientas estudiadas en los capítulos anteriores para responder una pregunta de negocio que implique analítica diagnóstica.
- Presentar los resultados de una regresión de manera gráfica empleando R.
- Determinar cuál variable tiene más efecto sobre la variable explicativa empleando R.
7.1 Introducción
En los capítulos anteriores hemos estudiado las bases del modelo clásico de regresión múltiple y cómo encontrar el mejor modelo para hacer analítica diagnóstica o analítica predictiva. En este capítulo pondremos todos los elementos juntos para resolver un caso de negocio que implica analítica diagnóstica. Adicionalmente, discutiremos cómo determinar cuál es la variable que tiene más impacto sobre la variable dependiente y cómo presentar los resultados de un modelo de regresión de manera visual. Por otro lado, es importante aclarar que aún no verificaremos el cumplimiento de los supuestos del modelo de regresión múltiple que se discutirán en la segunda parte de este libro. Nuestro análisis no estará completo hasta que se haga el chequeo de los supuestos. Pero este es un buen momento para hacer un alto en el camino y aplicar todo lo que hemos estudiado hasta el momento.
7.2 La pregunta de negocio
Mashable (https://mashable.com) es un portal de noticias en Internet que está interesado en entender de qué depende el número de veces que es compartido (shares) en redes sociales un artículo publicado por el portal para poder determinar políticas editoriales. La pregunta de negocio que tiene el editor es ¿De qué depende el número de shares de un artículo? Es más, esta pregunta, como de costumbre, implica otra pregunta ¿Existe alguna variable accionable71 que pueda ser modificada para generar una recomendación a los escritores? Nota que entre más veces se comparta un artículo más ingresos generará al portal y de ahí el interés de tener una guía para que los escritores generen artículos que sean muy compartidos. Nuestra tarea en este Capítulo es responder esa pregunta de negocio y hacer recomendaciones prácticas a los escritores. Esto implicará presentar nuestros resultados de una manera amigable a diferentes audiencias.
Para responder esta pregunta contamos con una base de datos con los artículos publicados en un periodo de dos años suministrada por Fernandes et al. (2015). La base de datos se encuentra en el archivo DatosCaso1.csv72. Estos datos son reales y fueron descargados de la siguiente página https://archive.ics.uci.edu/ml/datasets/Online+News+Popularity.
La base de datos contiene 39644 observaciones y las siguientes 61 variables:
- url: URL del artículo
- timedelta: Días entre la publicación del artículo y la fecha de corte de la base de datos
- n_tokens_title: Número de palabras del título
- n_tokens_content: Número de palabras en el contenido
- n_unique_tokens: Tasa de palabras únicas en el contenido
- n_non_stop_words: Tasa de palabras non-stop words73
- n_non_stop_unique_tokens: Tasa de palabras únicas non-stop en el contenido
- num_hrefs: Número de enlaces
- num_self_hrefs: Número de enlaces a otros artículos publicados por Mashable
- num_imgs: Número de imágenes
- num_videos: Número de vídeos
- average_token_length: Longitud promedio de las palabras del contenido
- num_keywords: Número de palabras clave en los metadatos
- data_channel_is_lifestyle: ¿Es el canal de datos estilo de vida?
- data_channel_is_entertainment: ¿Es el canal de datos entretenimiento?
- data_channel_is_bus: ¿Es el canal de datos Business?
- data_channel_is_socmed: ¿Es el canal de datos Redes sociales?
- data_channel_is_tech: ¿Es el canal de datos Tech?
- data_channel_is_world: ¿Es el canal de datos Mundo?
- kw_min_min: Peor palabra clave (min. shares)
- kw_max_min: Peor palabra clave (max. shares)
- kw_avg_min: Peor palabra clave (avg. shares)
- kw_min_max: Mejor palabra clave (min. shares)
- kw_max_max: Mejor palabra clave (max. shares)
- kw_avg_max: Mejor palabra clave (avg. shares)
- kw_min_avg: Promedio palabra clave (min. shares)
- kw_max_avg: Promedio palabra clave (max. shares)
- kw_avg_avg: Promedio palabra clave (avg. shares)
- self_reference_min_shares: Mínimos de shares de artículos referenciados en Mashable
- self_reference_max_shares: Máximos de shares de artículos referenciados en Mashable
- self_reference_avg_sharess: Promedio de shares de artículos referenciados en Mashable
- weekday_is_monday: ¿Se publicó el artículo un lunes?
- weekday_is_tuesday: ¿Se publicó el artículo un martes?
- weekday_is_wednesday: ¿Se publicó el artículo un miércoles?
- weekday_is_thursday: ¿Se publicó el artículo un jueves?
- weekday_is_friday: ¿Se publicó el artículo un viernes
- weekday_is_saturday: ¿Se publicó el artículo un sábado?
- weekday_is_sunday: ¿Se publicó el artículo un domingo?
- is_weekend: ¿Se publicó el artículo un fin de semana?
- LDA_00: Cercanía al tema 0 del LDA74
- LDA_01: Cercanía al tema 1 del LDA
- LDA_02: Cercanía al tema 2 del LDA
- LDA_03: Cercanía al tema 3 del LDA
- LDA_04: Cercanía al tema 4 del LDA
- global_subjectivity: Índice de Subjetividad del texto
- global_sentiment_polarity: Polaridad de sentimientos del texto
- global_rate_positive_words: Tasa de palabras positivas en el contenido
- global_rate_negative_words: Tasa de palabras negativas en el contenido
- rate_positive_words: Tasa de palabras positivas entre los tokens no neutrales
- rate_negative_words: Tasa de palabras negativas entre los tokens no neutrales
- avg_positive_polarity: Polaridad media de las palabras positivas
- min_positive_polarity: Polaridad mínima de las palabras positivas
- max_positive_polarity: Polaridad máxima de las palabras positivas
- avg_negative_polarity: Polaridad media de las palabras negativas
- min_negative_polarity: Polaridad mínima de las palabras negativas
- max_negative_polarity: Polaridad máxima de las palabras negativas
- title_subjectivity: Subjetividad del título
- title_sentiment_polarity: Polaridad del título
- abs_title_subjectivity: Nivel de subjetividad absoluta
- abs_title_sentiment_polarity: Nivel de polaridad absoluta
- shares): Número de veces que se comparte la noticia (Variable dependiente)
7.3 El plan
La primera tarea del científico de datos y de todo el equipo de analítica de una organización es precisar al máximo la pregunta de negocio que se desea responder. En este caso ya la pregunta de negocio está clara. Así mismo, de la mano de la definición de la pregunta de negocio va la identificación de los datos disponibles y la técnica o modelo a emplear. En este caso también esto es muy claro, contamos con una base de datos definida y limpia y la técnica a emplear es la regresión múltiple. Ahora debemos trazar una ruta analítica para responder la pregunta de negocio.
Los pasos que podemos desarrollar en este caso son:
Encontrar diferentes modelos candidatos a ser el mejor modelo y limpiarlos de variables no significativas
Comparar los modelos candidatos para seleccionar un único modelo
Identificar la variable más importante para explicar la variable dependiente
Generar las recomendaciones
Generar visualizaciones de los resultados
Empecemos a ejecutar esa ruta analítica para resolver la pregunta de negocio
7.4 Detección de posibles modelos
En este caso tenemos que explicar la variable shares para lo cuál contamos con 59 potenciales variables explicativas. Nota que la primera variable en la base de datos no es relevante (url), ésta corresponde al enlace del artículo. Esto implica que tendremos 5.7646075^{17} posibles modelos. Un número muy grande de modelos como para emplear la fuerza bruta. Esto implica la necesidad de emplear estrategias inteligentes de detección de un mejor modelo.
Empecemos por leer los datos y eliminar la primera variable que no es relevante.
Nota que los datos quedaron bien cargados y las clases de las variables son las correctas. Tu puedes constatar que no existen datos perdidos y que la base está lista para iniciar a trabajar.
Procedamos a encontrar los mejores modelos empleando las estrategias de regresión paso a paso forward, backward y combinada con el AIC, con el valor p y el \(R^2\) ajustado. Empleando las 9 opciones de algoritmos que se presentan en el Cuadro 7.1 estimaremos los modelos y eliminemos aquellas variables que no sean significativas. Los modelos que obtenemos las guardaremos con los nombres que se presentan el Cuadro 7.1.
| Nombre del objeto | Algoritmo | Criterio |
|---|---|---|
| modelo1 | Forward | \(R^2\) ajustado |
| modelo2 | Forward | valor p |
| modelo3 | Forward | AIC |
| modelo4 | Backward | \(R^2\) ajustado |
| modelo5 | Backward | valor p |
| modelo6 | Backward | AIC |
| modelo7 | Both | \(R^2\) ajustado |
| modelo8 | Both | valor p |
| modelo9 | Both | AIC |
| Fuente: elaboración propia. |
Antes de iniciar este proceso, partamos de estimar los modelos lineales con todas las variables potenciales (max.model) y sin variables (min.model).
# modelo con todas las variables
max.model <- lm(shares ~ . - weekday_is_sunday - is_weekend ,data = datos.caso1)
# modelo sin variables
min.model <- lm(shares ~ 1, data = datos.caso1) Nota que la variable weekday_is_sunday genera el fenómeno conocido como la trampa de las variables dummy (Ver Capítulo 5, pues es redundante al tener las otras 6 variables dummy para los otros días de la semana. R detecta esto y si bien se incluye en la fórmula no se incluye en la regresión. Lo mismo ocurre con la variable is_weekend.
Ahora procedamos a encontrar modelos candidatos para ser los mejores modelos. Empecemos con la estrategia stepwise Forward.
7.4.1 Stepwise forward
Empleando lo aprendido en el Capítulo 6 podemos obtener los modelos reportados en el Cuadro 7.2 tras limpiar las variables no significativas (con un 95% de confianza). Estas estimaciones pueden tomar un tiempo considerable. Tienes que tener paciencia para obtener estos resultados. Los resultados presentados en el Cuadro 7.2 muestran tres modelos que no se encuentran anidados. El código para encontrar estos resultados se omite intencionalmente; ¡intenta reproducir los resultados!
| Modelo 1 (\(R^2\) aj) | Modelo 2 (valor p) | Modelo 3 (AIC) | |
|---|---|---|---|
| (Intercept) | -2273.86*** | -1863.82*** | -1947.29*** |
| (542.11) | (563.07) | (565.87) | |
| timedelta | 1.99*** | 1.96*** | 1.93*** |
| (0.29) | (0.30) | (0.30) | |
| n_tokens_title | 115.29*** | 114.83*** | 112.22*** |
| (28.48) | (28.51) | (28.52) | |
| num_hrefs | 32.45*** | 32.01*** | 28.07*** |
| (6.00) | (6.09) | (6.32) | |
| num_self_hrefs | -50.16** | -56.08** | -50.84** |
| (16.82) | (17.04) | (17.03) | |
| num_imgs | 18.43* | 16.85* | |
| (7.59) | (7.62) | ||
| average_token_length | -465.21*** | -375.24*** | -336.70*** |
| (91.11) | (94.27) | (95.55) | |
| data_channel_is_entertainment | -720.98*** | -844.32*** | -885.44*** |
| (155.16) | (160.58) | (162.48) | |
| kw_min_max | -0.00* | -0.00** | -0.00** |
| (0.00) | (0.00) | (0.00) | |
| kw_min_avg | -0.41*** | -0.39*** | -0.37*** |
| (0.07) | (0.07) | (0.07) | |
| kw_max_avg | -0.21*** | -0.20*** | -0.19*** |
| (0.02) | (0.02) | (0.02) | |
| kw_avg_avg | 1.81*** | 1.74*** | 1.65*** |
| (0.11) | (0.11) | (0.12) | |
| self_reference_min_shares | 0.02*** | 0.02*** | 0.02*** |
| (0.00) | (0.00) | (0.00) | |
| self_reference_max_shares | 0.00* | 0.00* | 0.00* |
| (0.00) | (0.00) | (0.00) | |
| weekday_is_monday | 500.36** | 467.26** | 470.09** |
| (157.05) | (155.70) | (155.69) | |
| global_subjectivity | 2257.17*** | 2751.03*** | 2545.09*** |
| (674.29) | (749.07) | (751.66) | |
| avg_negative_polarity | -1762.79*** | -1675.10** | -1517.85** |
| (514.00) | (518.39) | (520.35) | |
| is_weekend | 399.48* | ||
| (174.69) | |||
| weekday_is_saturday | 584.36* | 583.71* | |
| (242.13) | (242.09) | ||
| LDA_02 | -736.57** | -655.12** | |
| (245.93) | (245.73) | ||
| global_rate_positive_words | -9889.32* | -10560.82** | |
| (4102.06) | (4098.27) | ||
| min_positive_polarity | -2079.23* | -1882.67* | |
| (897.81) | (925.53) | ||
| data_channel_is_lifestyle | -519.06* | ||
| (264.40) | |||
| LDA_03 | 711.47** | ||
| (252.22) | |||
| n_tokens_content | 0.31* | ||
| (0.15) | |||
| R2 | 0.02 | 0.02 | 0.02 |
| Adj. R2 | 0.02 | 0.02 | 0.02 |
| Num. obs. | 39644 | 39644 | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
7.4.2 Stepwise backward
De manera similar en el Cuadro 7.3 se presentan los resultados de emplear el algoritmo stepwise backward y tras limpiar las variables no significativas (con un 95% de confianza). Los resultados presentados en el Cuadro 7.3 muestran también tres modelos que no se encuentran anidados. El código para encontrar estos resultados se omite intencionalmente; ¡intenta reproducir los resultados!
| Modelo 4 (\(R^2\) aj) | Modelo 4 (valor p) | Modelo 5 (AIC) | |
|---|---|---|---|
| (Intercept) | -2346.26*** | -2044.76*** | 2005.17*** |
| (548.11) | (573.90) | (420.11) | |
| timedelta | 2.06*** | 2.02*** | |
| (0.29) | (0.30) | ||
| n_tokens_title | 109.60*** | 118.91*** | |
| (28.51) | (28.49) | ||
| n_tokens_content | 0.34* | 0.40** | |
| (0.14) | (0.14) | ||
| num_hrefs | 29.11*** | 28.92*** | |
| (6.26) | (6.19) | ||
| num_self_hrefs | -46.30** | -48.83** | |
| (16.88) | (16.93) | ||
| average_token_length | -270.98*** | ||
| (77.56) | |||
| data_channel_is_entertainment | -806.42*** | -815.53*** | |
| (158.99) | (160.40) | ||
| kw_min_max | -0.00** | -0.00** | |
| (0.00) | (0.00) | ||
| kw_min_avg | -0.39*** | -0.40*** | |
| (0.07) | (0.07) | ||
| kw_max_avg | -0.20*** | -0.20*** | |
| (0.02) | (0.02) | ||
| kw_avg_avg | 1.76*** | 1.79*** | |
| (0.12) | (0.11) | ||
| self_reference_min_shares | 0.02*** | 0.03*** | |
| (0.00) | (0.00) | ||
| self_reference_max_shares | 0.00* | ||
| (0.00) | |||
| weekday_is_monday | 498.95** | 469.41** | |
| (157.05) | (155.72) | ||
| LDA_03 | 831.99*** | 3819.18*** | |
| (248.73) | (260.53) | ||
| avg_negative_polarity | -2051.81*** | -1817.75*** | |
| (493.99) | (541.04) | ||
| is_weekend | 399.34* | ||
| (174.72) | |||
| data_channel_is_lifestyle | -534.92* | ||
| (264.76) | |||
| weekday_is_saturday | 584.08* | ||
| (242.17) | |||
| LDA_02 | -828.24*** | ||
| (245.00) | |||
| global_subjectivity | 2563.21*** | ||
| (762.16) | |||
| global_rate_positive_words | -9834.63* | ||
| (4561.75) | |||
| rate_positive_words | -1933.28*** | -1089.51** | |
| (538.17) | (394.05) | ||
| rate_negative_words | -2214.07*** | -1448.38** | |
| (566.10) | (509.20) | ||
| LDA_00 | 2289.12*** | ||
| (389.91) | |||
| kw_avg_max | 0.00** | ||
| (0.00) | |||
| max_negative_polarity | -1344.73* | ||
| (631.27) | |||
| min_negative_polarity | -1004.36*** | ||
| (231.07) | |||
| weekday_is_wednesday | -413.44* | ||
| (171.13) | |||
| self_reference_avg_sharess | 0.02*** | ||
| (0.00) | |||
| LDA_04 | 1578.63*** | ||
| (266.87) | |||
| weekday_is_friday | -461.17* | ||
| (186.43) | |||
| weekday_is_tuesday | -525.53** | ||
| (171.45) | |||
| weekday_is_thursday | -549.76** | ||
| (172.33) | |||
| LDA_01 | 948.77** | ||
| (306.58) | |||
| data_channel_is_bus | -689.66** | ||
| (256.30) | |||
| R2 | 0.02 | 0.02 | 0.01 |
| Adj. R2 | 0.02 | 0.02 | 0.01 |
| Num. obs. | 39644 | 39644 | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
7.4.3 Combinando forward y backward
Y finalmente, el Cuadro 7.4 se presentan los resultados de emplear el algoritmo combinado y tras limpiar las variables no significativas (con un 95% de confianza).
## Reordering variables and trying again:| Modelo 7 (\(R^2\) aj) | Modelo 8 (valor p) | Modelo 9 (AIC) | |
|---|---|---|---|
| (Intercept) | -1815.48** | -1947.29*** | -1947.29*** |
| (562.73) | (565.87) | (565.87) | |
| timedelta | 1.81*** | 1.93*** | 1.93*** |
| (0.30) | (0.30) | (0.30) | |
| n_tokens_title | 112.67*** | 112.22*** | 112.22*** |
| (28.52) | (28.52) | (28.52) | |
| num_hrefs | 35.95*** | 28.07*** | 28.07*** |
| (5.85) | (6.32) | (6.32) | |
| num_self_hrefs | -45.91** | -50.84** | -50.84** |
| (16.82) | (17.03) | (17.03) | |
| average_token_length | -262.43*** | -336.70*** | -336.70*** |
| (77.59) | (95.55) | (95.55) | |
| data_channel_is_entertainment | -862.27*** | -885.44*** | -885.44*** |
| (161.73) | (162.48) | (162.48) | |
| kw_min_max | -0.00** | -0.00** | -0.00** |
| (0.00) | (0.00) | (0.00) | |
| kw_min_avg | -0.37*** | -0.37*** | -0.37*** |
| (0.07) | (0.07) | (0.07) | |
| kw_max_avg | -0.19*** | -0.19*** | -0.19*** |
| (0.02) | (0.02) | (0.02) | |
| kw_avg_avg | 1.65*** | 1.65*** | 1.65*** |
| (0.12) | (0.12) | (0.12) | |
| self_reference_min_shares | 0.02*** | 0.02*** | 0.02*** |
| (0.00) | (0.00) | (0.00) | |
| self_reference_max_shares | 0.00* | 0.00* | 0.00* |
| (0.00) | (0.00) | (0.00) | |
| weekday_is_monday | 487.99** | 470.09** | 470.09** |
| (157.08) | (155.69) | (155.69) | |
| LDA_02 | -643.09** | -655.12** | -655.12** |
| (235.86) | (245.73) | (245.73) | |
| LDA_03 | 670.39** | 711.47** | 711.47** |
| (247.45) | (252.22) | (252.22) | |
| avg_negative_polarity | -2160.92*** | -1517.85** | -1517.85** |
| (492.39) | (520.35) | (520.35) | |
| is_weekend | 414.94* | ||
| (174.66) | |||
| global_subjectivity | 2545.09*** | 2545.09*** | |
| (751.66) | (751.66) | ||
| weekday_is_saturday | 583.71* | 583.71* | |
| (242.09) | (242.09) | ||
| n_tokens_content | 0.31* | 0.31* | |
| (0.15) | (0.15) | ||
| global_rate_positive_words | -10560.82** | -10560.82** | |
| (4098.27) | (4098.27) | ||
| min_positive_polarity | -1882.67* | -1882.67* | |
| (925.53) | (925.53) | ||
| R2 | 0.02 | 0.02 | 0.02 |
| Adj. R2 | 0.02 | 0.02 | 0.02 |
| Num. obs. | 39644 | 39644 | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
Los resultados presentados en el Cuadro 7.4 muestran que los modelos seleccionados por los criterios de valor p (Modelo 8) y AIC (Modelo 9) y el algoritmo combinado son el mismo. El modelo obtenido con este algoritmo y el criterio de \(R^2\) aj no está anidado en estos dos modelos anteriores.
7.5 Comparación de modelos
En resumen, contamos con 9 modelos con las variables explicativas que se representan con una X en el Cuadro 7.5. Los modelos 3, 8 y 9 son los mismos. Los otros seis modelos no se encuentran anidados. Por eso tendremos que comparar estos modelos con pruebas de modelos no anidados.
| Variable | modelo 1 | modelo 2 | modelo 3 | modelo 4 | modelo 5 | modelo 6 | modelo 7 | modelo 8 | modelo 9 |
|---|---|---|---|---|---|---|---|---|---|
| timedelta | X | X | X | X | X |
|
X | X | X |
| n_tokens_title | X | X | X | X | X |
|
X | X | X |
| n_tokens_content |
|
|
X | X | X |
|
X | X | X |
| num_hrefs | X | X | X | X | X |
|
X | X | X |
| num_self_hrefs | X | X | X | X | X |
|
X | X | X |
| n_tokens_content |
|
|
X |
|
|
|
|
X | X |
| average_token_length |
|
|
X | X |
|
|
X | X | X |
| num_imgs average_token_length | X | X |
|
|
|
|
|
|
|
| data_channel_is_lifestyle |
|
|
|
|
X |
|
|
|
|
| data_channel_is_entertainment | X | X | X | X | X |
|
X | X | X |
| kw_min_max |
|
|
X | X | X |
|
X | X | X |
| kw_min_avg |
|
X | X | X | X |
|
X | X | X |
| kw_max_avg | X | X | X | X | X |
|
X | X | X |
| kw_avg_avg | X | X | X | X | X |
|
X | X | X |
| kw_avg_max |
|
|
|
|
|
X |
|
|
|
| self_reference_min_shares | X | X | X | X | X |
|
X | X | X |
| self_reference_max_shares | X | X | X | X |
|
|
X | X | X |
| self_reference_avg_sharess |
|
|
|
|
|
X |
|
|
|
| data_channel_is_lifestyle |
|
X |
|
|
|
|
|
|
|
| data_channel_is_bus |
|
|
|
|
|
X |
|
|
|
| weekday_is_monday | X | X | X | X |
|
|
X | X | X |
| weekday_is_tuesday |
|
|
|
|
X |
|
|
|
|
| weekday_is_wednesday |
|
|
|
|
X |
|
|
|
|
| weekday_is_thursday |
|
|
|
|
X |
|
|
|
|
| weekday_is_friday |
|
|
|
|
X |
|
|
|
|
| weekday_is_saturday | X | X | X |
|
|
|
|
X | X |
| is_weekend | X |
|
|
X |
|
X | X |
|
|
| LDA_00 |
|
|
|
|
|
X |
|
|
|
| LDA_01 |
|
|
|
|
|
X |
|
|
|
| LDA_02 |
|
X | X |
|
X |
|
X | X | X |
| LDA_03 | X | X | X | X |
|
X | X | X | X |
| LDA_04 |
|
|
|
|
|
X |
|
|
|
| global_rate_positive_words |
|
X | X |
|
|
|
|
X | X |
| global_subjectivity | X | X | X |
|
X |
|
|
X | X |
| global_rate_positive_words |
|
|
|
|
X |
|
|
|
|
| min_positive_polarity |
|
X | X |
|
|
|
|
X | X |
| avg_negative_polarity | X | X | X | X | X |
|
X | X | X |
| max_negative_polarity |
|
|
|
|
|
X |
|
|
|
| min_negative_polarity |
|
|
|
|
|
X |
|
|
|
| rate_positive_words |
|
|
|
|
X | X |
|
|
|
| rate_negative_words |
|
|
|
|
X | X |
|
|
|
| Fuente: elaboración propia. |
Empecemos comparando todos los modelos con la prueba J. En el Cuadro 7.6 se reportan los valores p de las pruebas J que permiten probar la hipótesis nula de que el modelo de la fila es mejor que el de la columna.
| Modelo 1 | Modelo 2 | Modelo 3 | Modelo 4 | Modelo 5 | Modelo 6 | Modelo 7 | |
|---|---|---|---|---|---|---|---|
| Modelo 1 | NA | 0.000 | 0.000 | 0.002 | 0.000 | 0.002 | 0.001 |
| Modelo 2 | 0.243 | NA | 0.006 | 0.003 | 0.284 | 0.024 | 0.015 |
| Modelo 3 | 0.079 | 0.026 | NA | 0.282 | 0.180 | 0.678 | 0.282 |
| Modelo 4 | 0.001 | 0.000 | 0.000 | NA | 0.000 | 0.036 | 0.005 |
| Modelo 5 | 0.001 | 0.000 | 0.000 | 0.000 | NA | 0.002 | 0.000 |
| Modelo 6 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NA | 0.000 |
| Modelo 7 | 0.001 | 0.000 | 0.000 | 0.013 | 0.000 | 0.738 | NA |
| Fuente: elaboración propia. |
Si miramos la primera fila, con un 99% de confianza, podemos concluir que el modelo 1 no es mejor que los otros modelos75. Si miramos la primera columna, podemos ver cómo la nula de que el modelo 2 es mejor que el 1 no se puede rechazar y lo mismo ocurre para el modelo 3 comparado con el modelo 1. Es decir, con un 99% de confianza, podemos concluir que los modelos 2 y 3 son mejores que el 1. Para los otros modelos no se puede afirmar algo similar, y por tanto la prueba no es concluyente. Al comparar el modelo 2 con el 3, se encuentra que se puede rechazar la nula de que el modelo 2 es mejor que el tres, pero no que el modelo 3 es mejor que el 2. Es decir, el modelo 3 es mejor. La prueba no puede concluir al comparar el modelo 2 con el 4; y permite concluir que el modelo 2 es mejor que el 5, 6 y 7.
Para el modelo 3, no se puede rechazar que este modelo sea mejor que cada uno de los otros 6 modelos, pero las hipótesis nulas opuestas si se pueden rechazar (con un 99% de confianza). Podemos encontrar que el modelo 4 es mejor que el 6. El modelo 5 no es mejor que los otros modelos, lo mismo ocurre con el modelo 6. Y el modelo 7 es mejor que el 4 y el 6. Para las otras comparaciones que no se mencionan en la prueba no es concluyente. Es decir, poniendo todo junto el modelo 3 es el mejor.
Ahora empleemos las métricas AIC y BIC y el \(R^2\) ajustado, para comparar los modelos. Los resultados se reportan en el Cuadro 7.7 y BIC().
| R2.ajustado | AIC | BIC | |
|---|---|---|---|
| Modelo 1 | 0.022 | 853877.4 | 854040.6 |
| Modelo 2 | 0.022 | 853867.2 | 854064.7 |
| Modelo 3 | 0.022 | 853864.7 | 854062.2 |
| Modelo 4 | 0.022 | 853879.6 | 854042.8 |
| Modelo 5 | 0.022 | 853876.0 | 854064.9 |
| Modelo 6 | 0.012 | 854258.9 | 854404.9 |
| Modelo 7 | 0.022 | 853878.0 | 854041.2 |
| Fuente: elaboración propia. |
El \(\bar R^2\) y el AIC sugieren que el mejor modelo es el 3, mientras que el BIC selecciona el 1. Poniendo todo junto, el mejor modelo será el modelo 3 (que es igual al 8 y 9) el cuál se reporta en el Cuadro 7.8.
| Modelo 3 | |
|---|---|
| (Intercept) | -1947.29*** |
| (565.87) | |
| kw_avg_avg | 1.65*** |
| (0.12) | |
| self_reference_min_shares | 0.02*** |
| (0.00) | |
| kw_max_avg | -0.19*** |
| (0.02) | |
| kw_min_avg | -0.37*** |
| (0.07) | |
| timedelta | 1.93*** |
| (0.30) | |
| num_hrefs | 28.07*** |
| (6.32) | |
| n_tokens_title | 112.22*** |
| (28.52) | |
| data_channel_is_entertainment | -885.44*** |
| (162.48) | |
| LDA_03 | 711.47** |
| (252.22) | |
| avg_negative_polarity | -1517.85** |
| (520.35) | |
| average_token_length | -336.70*** |
| (95.55) | |
| global_subjectivity | 2545.09*** |
| (751.66) | |
| weekday_is_monday | 470.09** |
| (155.69) | |
| kw_min_max | -0.00** |
| (0.00) | |
| weekday_is_saturday | 583.71* |
| (242.09) | |
| num_self_hrefs | -50.84** |
| (17.03) | |
| n_tokens_content | 0.31* |
| (0.15) | |
| LDA_02 | -655.12** |
| (245.73) | |
| global_rate_positive_words | -10560.82** |
| (4098.27) | |
| min_positive_polarity | -1882.67* |
| (925.53) | |
| self_reference_max_shares | 0.00* |
| (0.00) | |
| R2 | 0.02 |
| Adj. R2 | 0.02 |
| Num. obs. | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
En todo el proceso que desarrollemos es importante no olvidar cuál es la pregunta de negocio que queremos responder. Nuestra pregunta de negocio inicial era ¿De qué depende el número de shares de un artículo? Esta pregunta ya la podemos responder con el mejor modelo encontrado en este caso las variables que explican los shares son: kw_avg_avg, self_reference_min_shares, kw_max_avg, kw_min_avg, timedelta, num_hrefs, n_tokens_title, data_channel_is_entertainment, LDA_03, avg_negative_polarity, average_token_length, global_subjectivity, weekday_is_monday, kw_min_max, weekday_is_saturday, num_self_hrefs, n_tokens_content, LDA_02, global_rate_positive_words, min_positive_polarity, self_reference_max_shares, data_channel_is_lifestyle, num_keywords, kw_max_min, abs_title_sentiment_polarity, abs_title_subjectivity, kw_avg_min, kw_min_min.
De esas variables podemos denotar que aquellas que al aumentarse aumentan los shares son: kw_avg_avg, self_reference_min_shares, timedelta, num_hrefs, n_tokens_title, LDA_03, global_subjectivity, weekday_is_monday, weekday_is_saturday, n_tokens_content, self_reference_max_shares. Las otras variables tienen una relación inversa con los shares.
Ahora, este listado de variables es útil, pero contar con 28 variables para generar sugerencias a los escritores puede implicar una tarea ardua. Si recuerdan, la segunda pregunta de negocio derivada que teníamos es: ¿Existe alguna variable accionable que pueda ser modificada para generar una recomendación a los escritores? En la siguiente sección discutiremos cómo identificar las variables más importantes al momento de explicar la variable dependiente.
7.6 Identificación de la variable más importante
Una pregunta habitual cuando estamos haciendo analítica diagnóstica es: ¿cuál variable es la más importante para explicar la variable dependiente? Existen varias formas de responder esta pregunta que discutiremos a continuación.
7.6.1 Coeficientes estandarizados
Tal vez la primera respuesta que salta a la mente a la pregunta ¿cuál variable explicativa es la más importante? es emplear los coeficientes estimados (\(\hat \beta\)). Pero, ¡esta respuesta no es correcta! No se puede ver el valor del coeficiente estimado para determinar cuál variable es la más importante, dado que estos coeficientes estimados están en las unidades en las que se expresa tanto la variable dependiente como la independiente. Así el tamaño de los coeficientes dependen de las unidades en que esté medida la variable dependiente y cada una de las variables explicativas.
Si comparamos coeficientes estimados estaríamos comparando peras con manzanas. Para resolver este problema se emplean los coeficientes estandarizados. Estos implican expresar los coeficientes estimados en términos de desviaciones estándar. Es decir, el coeficiente estandarizado para la variable explicativa \(j\) (con76 \(j = 2, 3, ...,k\)) será:
\[\begin{equation} \hat{\beta}_{j,estand} = \hat{\beta}_j \frac{s_{j}}{s_{y}} \tag{7.1} \end{equation}\]
donde \(s_{j}\) y \(s_{y}\) representan la desviación estándar muestral del regresor \(j\) y de la variable dependiente, respectivamente.
Una vez los coeficientes se encuentran estandarizados, podremos comparar el efecto de un aumento de una desviación estándar de cada una de las variables explicativas sobre la variable dependiente; este efecto también medido en desviaciones estándar.
Una forma de calcular rápidamente los coeficientes estandarizados en R es emplear la función calc.relimp() del paquete relaimpo (Grömping, 2006). Esta función necesita dos argumentos para calcular los coeficientes estandarizados al cuadrado: un objeto de clase lm y el tipo de medida que se desea (argumento type). Para el caso de los coeficientes estandarizados, type = “betasq”.
#install.packages("relaimpo")
library(relaimpo)
# cálculo de los coeficientes estandarizados al cuadrado
coef.estandarizados <- calc.relimp(modelo3, type = "betasq")
# coeficientes estandarizados
coef.estandarizados <- sqrt(coef.estandarizados$betasq)
coef.estandarizados## kw_avg_avg self_reference_min_shares
## 0.18759294 0.03841779
## kw_max_avg kw_min_avg
## 0.09764905 0.03576353
## timedelta num_hrefs
## 0.03562264 0.02735715
## n_tokens_title data_channel_is_entertainment
## 0.02040320 0.02913085
## LDA_03 avg_negative_polarity
## 0.01806327 0.01667411
## average_token_length global_subjectivity
## 0.02445276 0.02554175
## weekday_is_monday kw_min_max
## 0.01511678 0.01413186
## weekday_is_saturday num_self_hrefs
## 0.01209565 0.01685682
## n_tokens_content LDA_02
## 0.01266509 0.01589746
## global_rate_positive_words min_positive_polarity
## 0.01583054 0.01154752
## self_reference_max_shares
## 0.01169232## kw_avg_avg
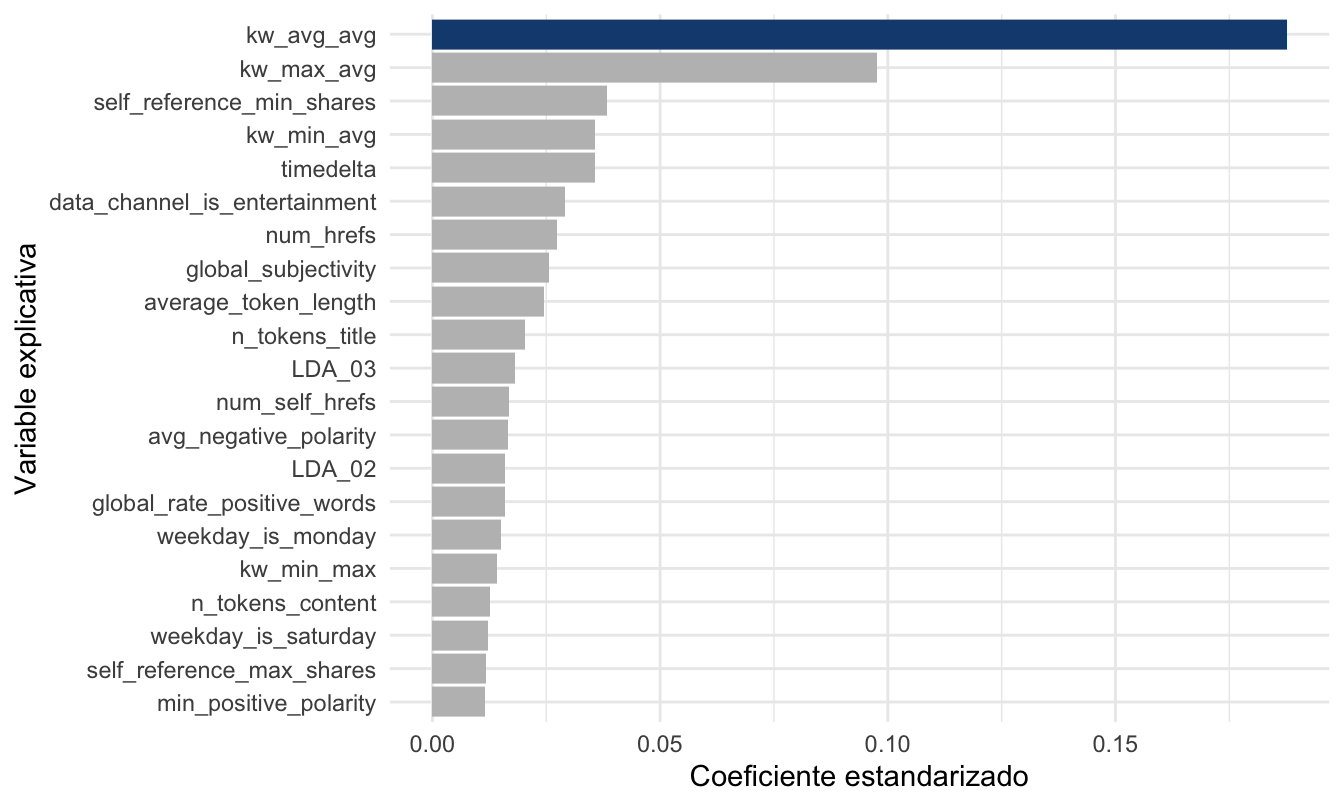
## 0.1875929Ahora podríamos afirmar que la variable que más afecta a los shares es la variable kw_avg_avg. Esto lo podemos mostrar de una manera visual empleando la Figura 7.1.
Figura 7.1: Coeficientes estandarizados del Modelo 3
7.7 Aporte relativo de cada variable empleando el R cuadrado
Otra forma de medir el aporte relativo de cada una de las variables explicativas es determinar la proporción adicional de la variación de la variable dependiente que es explicada por cada una de las variables, dado que los otros regresores ya están incluidos en el modelo. Es decir, el aumento en el \(R^2\) que se obtiene al adicionar el respectivo regresor dado que ya están en el modelo las otras \(k-2\) variables explicativas .
Esta medida de importancia relativa se puede calcular con la función calc.relimp() del paquete relaimpo que ya habíamos empleado. En este caso, debemos cambiar el valor del argumento type a “last”.
## Response variable: shares
## Total response variance: 135185984
## Analysis based on 39644 observations
##
## 21 Regressors:
## kw_avg_avg self_reference_min_shares kw_max_avg kw_min_avg timedelta num_hrefs n_tokens_title data_channel_is_entertainment LDA_03 avg_negative_polarity average_token_length global_subjectivity weekday_is_monday kw_min_max weekday_is_saturday num_self_hrefs n_tokens_content LDA_02 global_rate_positive_words min_positive_polarity self_reference_max_shares
## Proportion of variance explained by model: 2.26%
## Metrics are not normalized (rela=FALSE).
##
## Relative importance metrics:
##
## last
## kw_avg_avg 4.468595e-03
## self_reference_min_shares 1.115899e-03
## kw_max_avg 1.851655e-03
## kw_min_avg 6.450879e-04
## timedelta 1.019827e-03
## num_hrefs 4.869298e-04
## n_tokens_title 3.819461e-04
## data_channel_is_entertainment 7.325371e-04
## LDA_03 1.962854e-04
## avg_negative_polarity 2.098929e-04
## average_token_length 3.062830e-04
## global_subjectivity 2.828098e-04
## weekday_is_monday 2.248855e-04
## kw_min_max 1.737811e-04
## weekday_is_saturday 1.434062e-04
## num_self_hrefs 2.199541e-04
## n_tokens_content 1.104386e-04
## LDA_02 1.753337e-04
## global_rate_positive_words 1.638049e-04
## min_positive_polarity 1.020706e-04
## self_reference_max_shares 9.890499e-05## kw_avg_avg
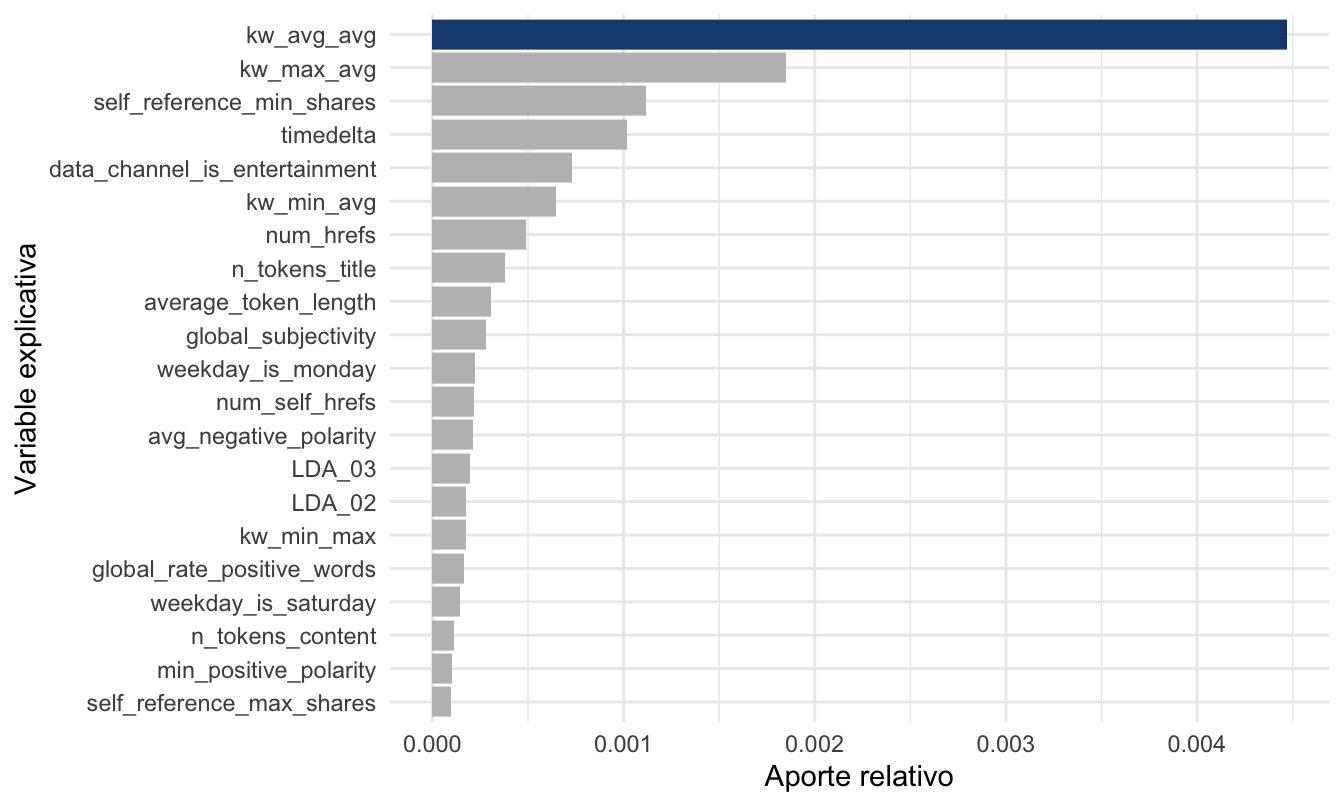
## 0.004468595Según este método, podemos afirmar que la variable que más afecta a los shares es la variable kw_avg_avg. Esto lo podemos mostrar de una manera visual empleando la Figura 7.2.
Figura 7.2: Aporte relativo de cada variable al \(R^2\) del Modelo 3
7.8 Generación de las recomendaciones
Ahora podemos proceder a generar las recomendaciones. Ya conocemos la respuesta a la pregunta ¿De qué depende el número de shares de un artículo? y ¿Existe alguna variable accionable que pueda ser modificada para generar una recomendación a los escritores? Es más ya sabemos cuáles son las variables más importantes. Así podemos proceder a realizar recomendaciones.
Sabemos que las variables de las que dependen los shares son las siguientes 28 variables: kw_avg_avg, self_reference_min_shares, kw_max_avg, kw_min_avg, timedelta, num_hrefs, n_tokens_title, data_channel_is_entertainment, LDA_03, avg_negative_polarity, average_token_length, global_subjectivity, weekday_is_monday, kw_min_max, weekday_is_saturday, num_self_hrefs, n_tokens_content, LDA_02, global_rate_positive_words, min_positive_polarity, self_reference_max_shares, data_channel_is_lifestyle, num_keywords, kw_max_min, abs_title_sentiment_polarity, abs_title_subjectivity, kw_avg_min, kw_min_min.
De esas variables la más importante es kw_avg_avg (independientemente del método que empleemos).
Entonces, el promedio de palabras claves debe ser lo más grande posible, pues esta es la variable más importante al momento de explicar los shares.
Tu puedes continuar generando recomendaciones con los resultados. Por ejemplo, nota que existen variables no accionables como timedelta sobre la cual no se puede actuar, no obstante en este caso la mayoría de variables son accionables.
7.9 Generación de visualizaciones de los resultados
Ahora veamos cómo se pueden presentar los resultados de una manera mas amigable que emplear cuadros. El Cuadro 7.8 puede no ser la mejor opción de presentar los resultados para la mayoría de públicos, en especial para los tomadores de decisiones. En esos casos podríamos emplear gráficos para mostrar los resultados. Por ejemplo, el paquete jtools (J. A. Long, 2020) permite visualizar los resultados de un objeto de clase lm. La función plot_summs() permite visualizar rápidamente un objeto de clase lm. Si solo usamos como argumento un objeto de clase lm obtendremos una visualización rápida como la presentada en la Figura 7.3.
# Instalar el paquete si no se tiene
# install.packages("jtools")
# Cargar el paquete
library(jtools)
# Generar la visualización
plot_summs(modelo3)Figura 7.3: Visualización de los coeficientes estimados del modelo 3
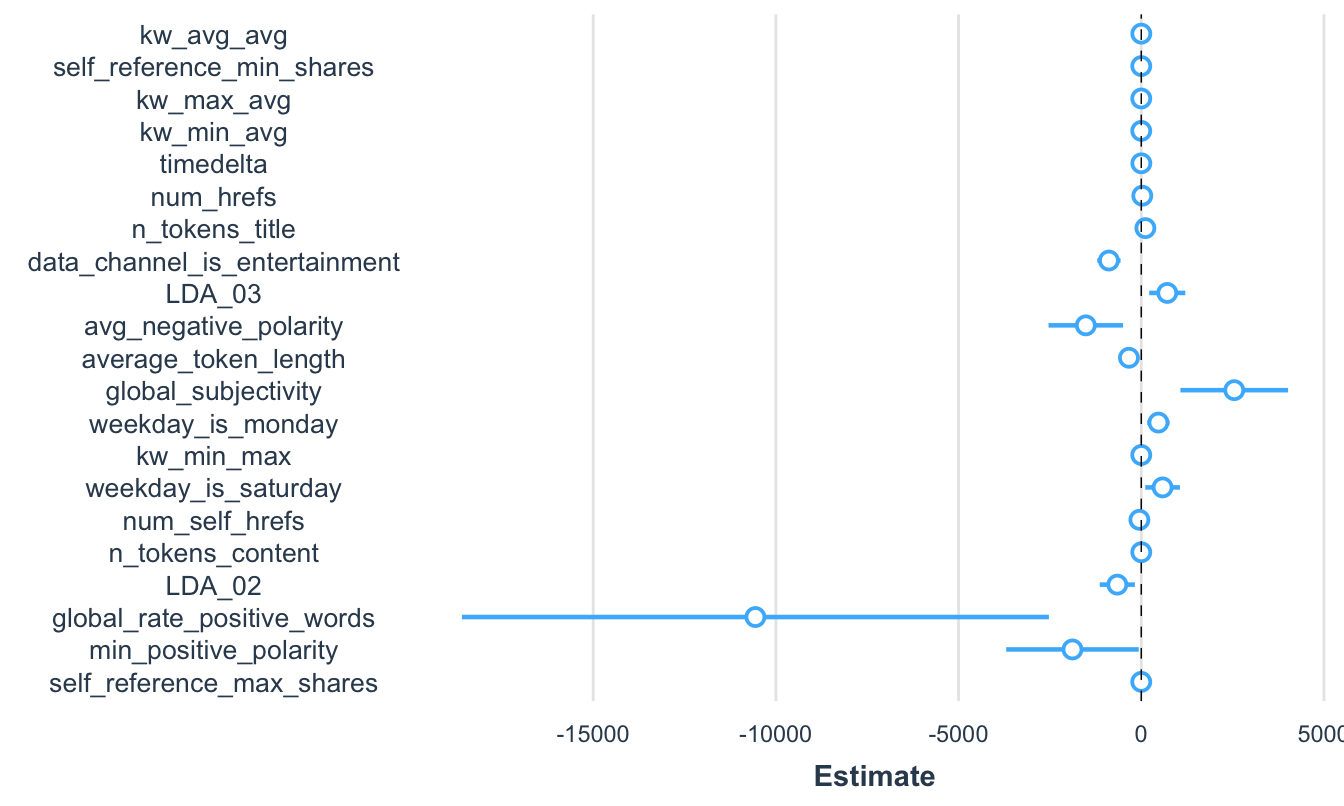
Este gráfico permite ver los coeficientes y sus respectivos intervalos de confianza. El intervalo por defecto es del 95% y emplea los errores estándar estimados por MCO.
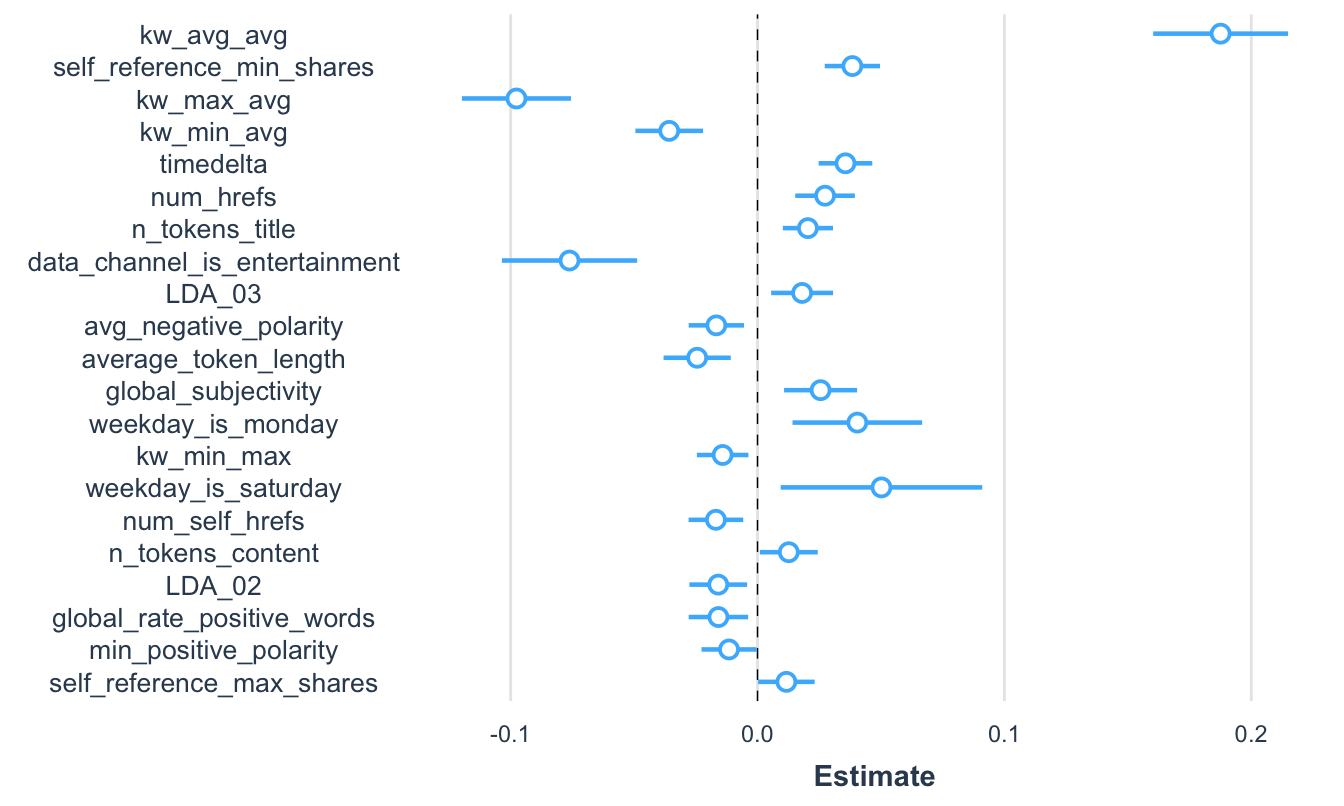
Un problema de este gráfico es que los coeficientes están en diferentes escalas y el estimador del coeficiente asociado a global_rate_positive_words es grande (en valor absoluto) respecto a los otros coeficientes. Algo similar ocurre con el coeficiente asociado a “global_subjectivity”. Cómo lo discutimos en la sección 7.6.1, los coeficientes estimados (\(\hat \beta\)) dependen de las unidades en que se midan las variables explicativas (y la dependiente). Como lo vimos, una forma de evitar esto es graficar los coeficientes estandarizados empleando los argumentos scale y transform.response. Por defecto estos dos argumentos son fijados en FALSE, si los pasamos a TRUE las variables explicativas (scale = TRUE) y la dependiente (transform.response = TRUE) son estandarizadas. En nuestro caso podemos obtener los coeficientes estandarizados y los correspondientes intervalos de confianza de la siguiente manera (Ver Figura 7.4).
Figura 7.4: Visualización de los coeficientes estandarizados del modelo 3
Podemos cambiar otras opciones del gráfico. Por ejemplo, podemos incluir un intervalo de confianza del 99% y del 95% (Ver Figura 7.5).
Figura 7.5: Visualización de los coeficientes estandarizados del modelo 3 y sus intervalos de confianza
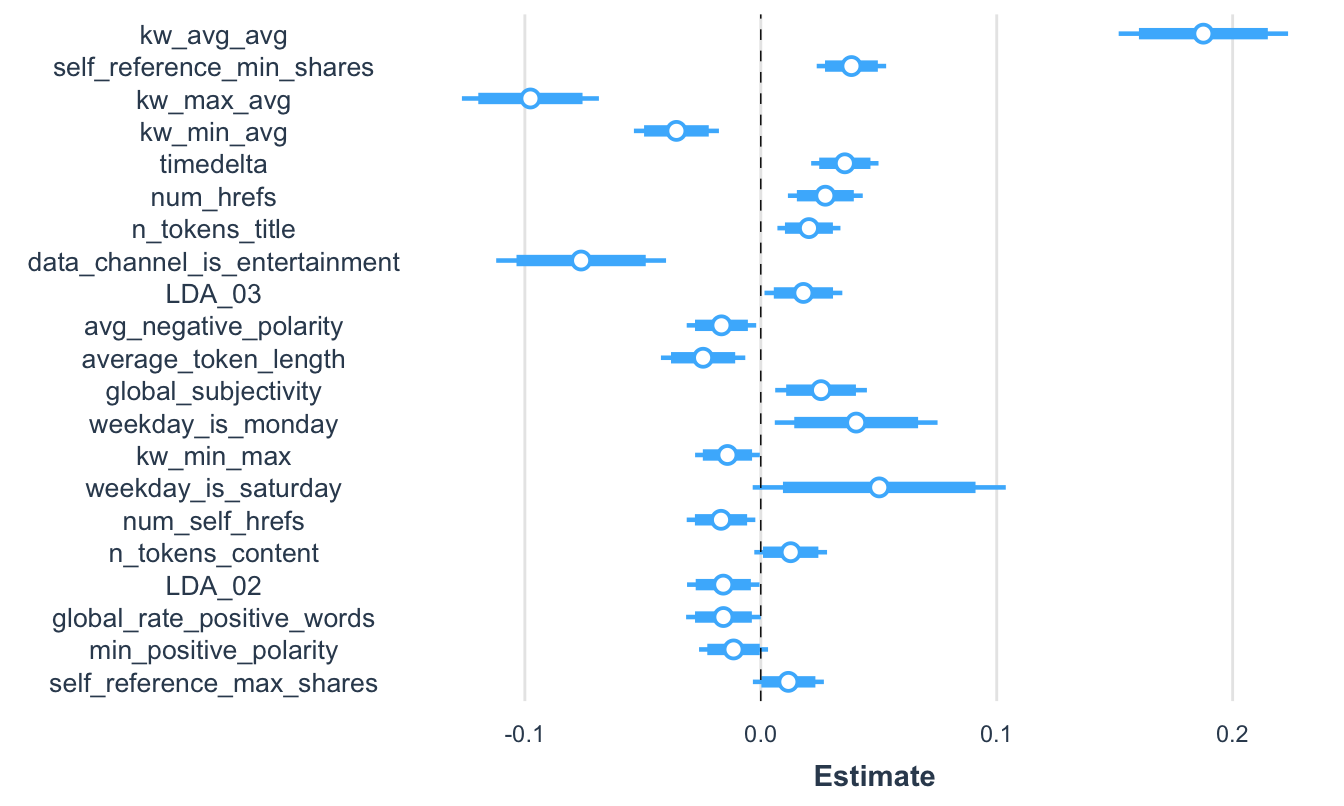
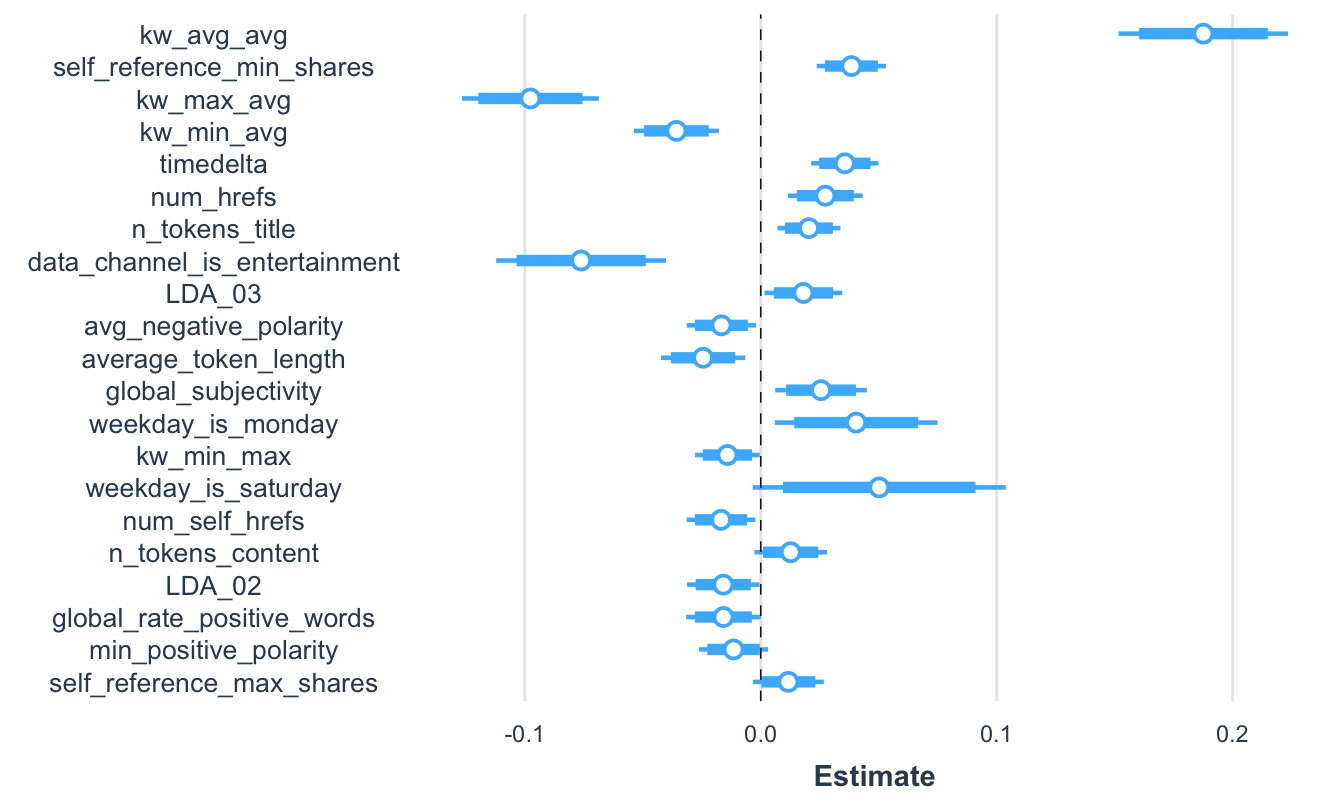
También podemos incluir la distribución asintótica de los estimadores (Ver Figura 7.6).
plot_summs(modelo3, scale = TRUE, transform.response = TRUE,
ci_level = 0.99,plot.distributions = TRUE)
# Intenta esta otra visualización
plot_summs(modelo3, modelo1, plot.distributions = TRUE,
rescale.distributions = TRUE)Figura 7.6: Visualización de los coeficientes del modelo 3 estandarizados con sus intervalos de confianza y su distribución
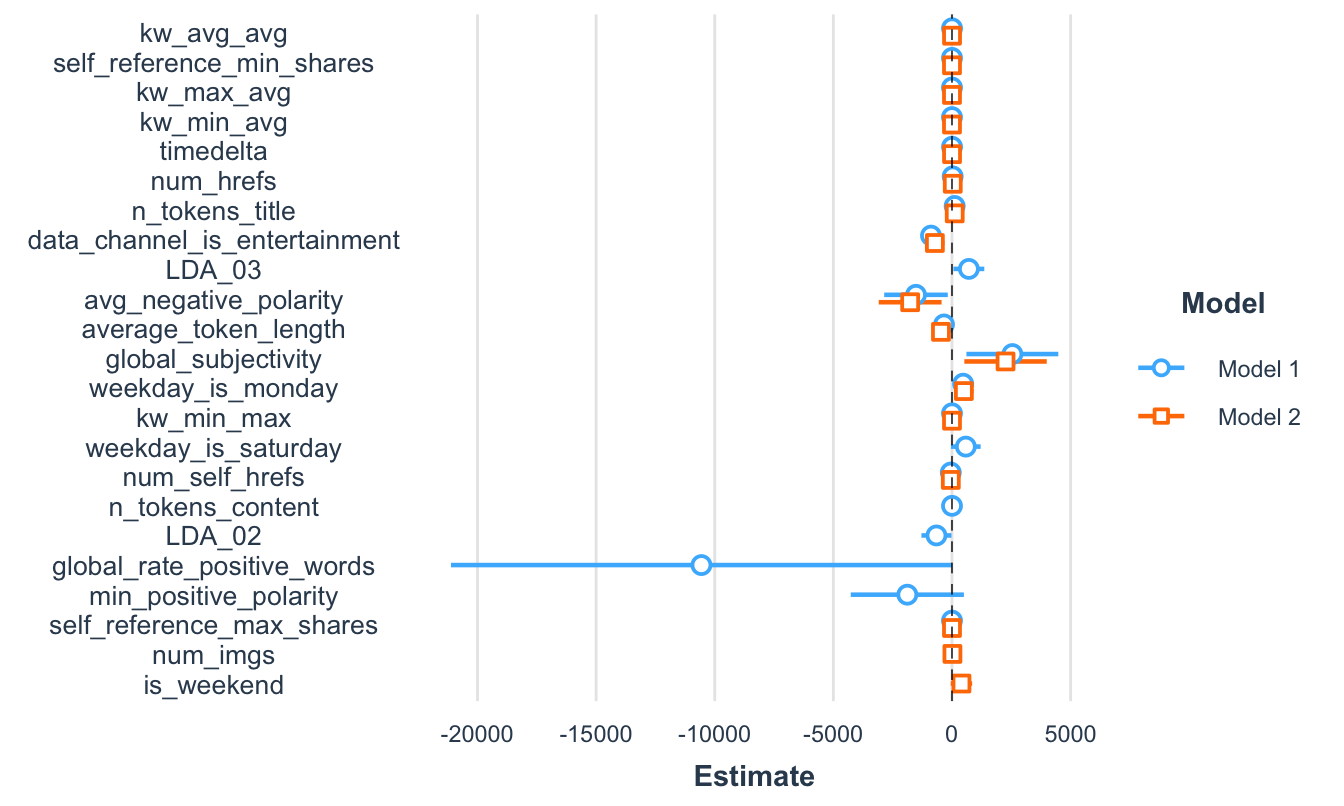
Además podemos mostrar dos modelos al mismo tiempo (Ver Figura 7.7). Por ejemplo:
Figura 7.7: Visualización de los coeficientes del modelo 1 y modelo 3
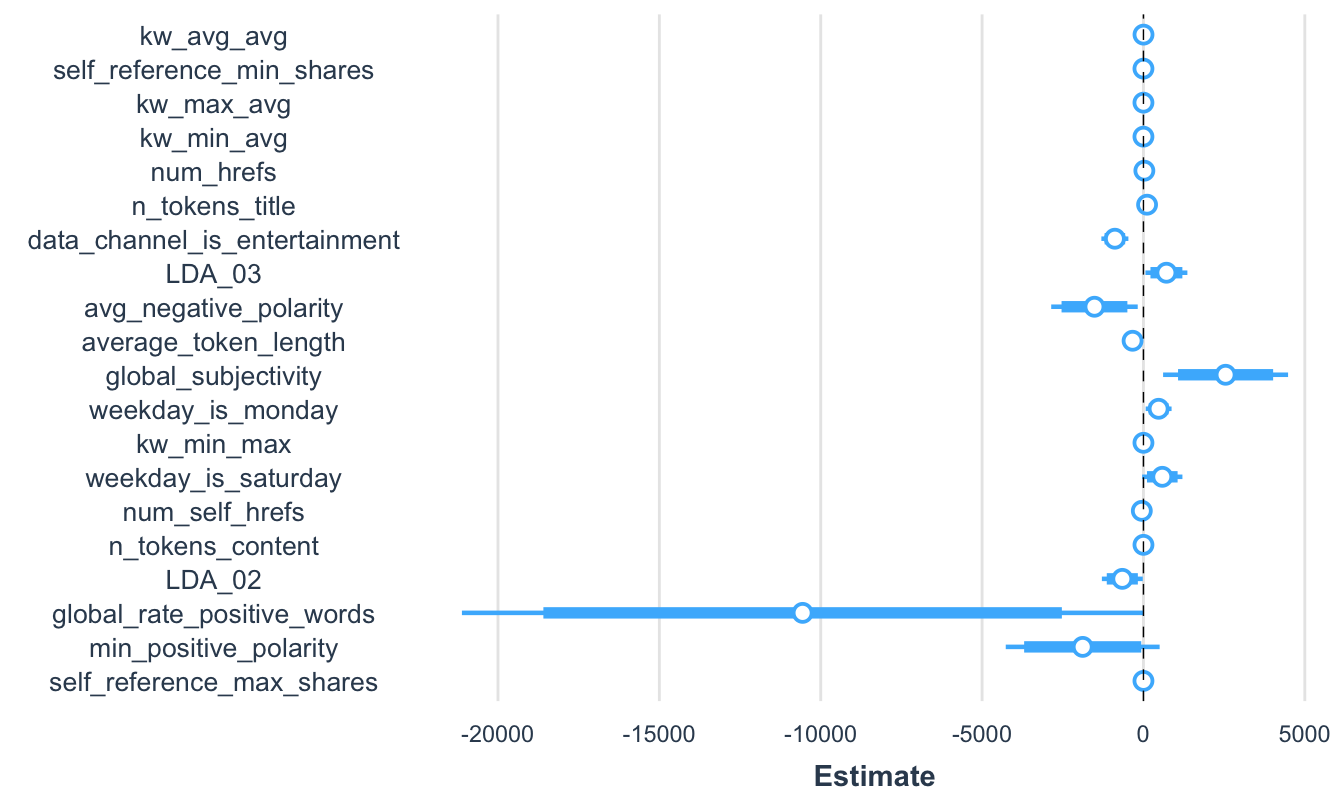
También podemos omitir una variable si no queremos que cree “ruido” al momento de la presentación77 (Ver Figura 7.8.
plot_summs(modelo3, ci_level = 0.99, inner_ci_level = .95,
mit.coefs = c("timedelta", "(Intercept)"))Figura 7.8: Visualización de los coeficientes del modelo 3 para algunas variables selecionadas y sus respectivos intervalos de confianza
7.10 Comentarios Finales
En este capítulo hemos seguido el proceso paso a paso para responder una pregunta de negocio empleando un modelo de regresión para hacer analítica diagnóstica. Adicionalmente, discutimos cómo encontrar la variable más importante y cómo visualizar los resultados. Antes de continuar, es importante resaltar que no se han chequeado los supuestos del modelo de regresión, y por tanto no podemos estar seguros que el método de MCO empleado nos provee estimadores MELI.
En los siguientes capítulos estudiaremos cómo constatar si los supuestos se cumplen y en caso que estos no se cumplan, cómo solucionar el problema. En el Capítulo 10 retomaremos este caso de negocio y constataremos si se cumplen los supuestos del modelo.
Es importante recalcar que aún no podemos sacar conclusiones finales para tomar decisiones, pues no estamos seguros si el modelo que estimamos es bueno (cumple los supuestos del Teorema de Gauss-Markov). En el Capítulo 10 retomaremos esta pregunta de negocio.
Referencias
Por una variable accionable en la jerga de los negocios, es aquella que le permite a la organización desarrollar estrategias y campañas que permitan el logro de un objetivo.↩︎
Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/. ↩︎
Es importante aclarar dos términos que se emplean en esta base de datos. Por un lado, las stop words o palabras vacías son palabras comunes de un idioma que no aportan al análisis como por ejemplo: los, las, tendremos, etc. Para discusión introductoria al análisis de textos se puede consultar Alonso (2020b).↩︎
la LDA (Latent Dirichlet Allocation) en este contexto es una variable generada por modelo estadístico que asocia palabras recogidas en documentos y las asocia con un pequeño número de temas. Los modelos que generan los LDA pertenecen al campo del aprendizaje de máquina. ↩︎
Nota que la hipótesis nula asociada a los valores p reportados en la primera fila del Cuadro 7.6 corresponde a que el modelo 1 es mejor al modelo de la respectiva columna. Y esa hipótesis nula se puede rechazar en todos los casos.↩︎
Al intercepto no se le calcula este tipo de coeficientes.↩︎
Por ejemplo si no se quieren mostrar variables no accionables o quitar el intercepto.↩︎