12 Predicciones en corte transversal
Objetivos del capítulo
Al terminar la lectura de este capítulo el lector estará en capacidad de:
- Explicar en sus propias palabras la diferencia entre un pronóstico y una predicción.
- Explicar en sus propias palabras qué es la validación cruzada, para que sirve y cuándo se debe emplear.
- Efectuar en R una validación cruzada por los métodos de retención, LOOCV y k-folds para seleccionar un modelo de regresión para hacer analítica predictiva (en muestras de corte transversal).
- Construir intervalos de confianza para predicciones.
12.1 Introducción
Los modelos de regresión múltiple pueden emplearse para hacer analítica predictiva. La analítica predictiva busca responder la pregunta: ¿qué es posible que ocurra? Con datos ya existentes se estima un modelo que permita predecir datos que aún no se tienen o no han ocurrido. Es importante resaltar que la creación de predicciones no necesariamente implica predecir lo qué ocurrirá en el futuro. De hecho, la creación de pronósticos (forecasting en inglés) es un área de la predicción en la que se realizan predicciones sobre el futuro, basándonos en datos de series de tiempo. La única diferencia entre la predicción y los pronósticos es que en esta última se considera la dimensión temporal. La analítica predictiva tiene como intención generar predicciones de variables cuantitativas.
El modelo de regresión múltiple puede emplearse tanto para hacer predicciones como pronósticos. Para la creación de pronósticos es necesario la estimación de un modelo empleando datos de serie de tiempo. Cuando empleamos muestras de corte transversal, podemos realizar predicciones pero no pronósticos.
Por ejemplo, si se emplea una muestra de muchos individuos en el mismo periodo (muestra de corte transversal) para encontrar las variables asociadas a la cantidad de unidades que compra un cliente, el modelo podría ser empleado para responder la pregunta ¿cuánto compraría un nuevo cliente con determinadas características?.
Si el modelo de regresión múltiple se estima con una serie de tiempo (se observa un objeto de estudio periodo tras periodo), éste podrá ser empleado para hacer pronósticos. Por ejemplo, si se cuenta con las ventas mensuales para muchos periodos y el modelo encuentra que variables están asociadas a estas ventas mes tras mes, el modelo podría responder la pregunta ¿qué ocurrirá en el futuro con las ventas? Con este tipo de modelos podemos responder preguntas como: ¿cuánto es lo más probable que venda un producto el próximo año?
En este capítulo nos concentraremos en la construcción de predicciones y no de pronósticos. Es decir, nos concentraremos en la analítica predictiva que emplea modelos de corte transversal.
Hasta ahora hemos discutido la estimación de modelos de regresión múltiple y el diagnóstico y solución de los problemas que aparecen tras la violación de los supuestos del Teorema de Gauss-Markov. Hemos discutido la interpretación de los coeficientes que permiten determinar el efecto de una variable independiente sobre el comportamiento de la variable dependiente, aislando el efecto de las otras variables. Esto corresponde a un análisis de analítica diagnóstica. Por eso, hasta ahora no se había discutido el poder predictivo de los modelos estimados. Los modelos se han estimado con el total de la muestra y esto es lo común si se desea hacer analítica diagnóstica. Es decir, hemos empleado las herramientas de la estadística para responder la pregunta ¿qué tan bueno es el modelo para explicar la muestra que tenemos?.
Para responder dicha pregunta, hemos empleado herramientas como pruebas de hipótesis de modelos anidados y no anidados, el \(R^2\), el \(R^2\) ajustado, SBC y AIC. Cómo lo vimos, no existe una única forma de determinar la bondad de ajuste de un modelo a una determinada muestra. No obstante, las herramientas estudiadas si tienen en común que su objetivo es medir qué tan bien se ajusta el modelo estimado a la muestra que empleamos para su estimación (entrenamiento).
Emplear estas herramientas nos llevan a encontrar modelos que explican lo mejor posible la muestra bajo estudio, pero no necesariamente nuevas muestras que aparezcan. Es decir, es posible que tengamos un modelo muy bueno para explicar la muestra (analítica diagnóstica) pero no necesariamente para hacer analítica predictiva. Esto se conoce como el problema de overfitting (sobreajuste).
Cuando los científicos de datos están interesados en responder una pregunta de negocio que involucra emplear analítica predictiva, será necesario evaluar el poder predictivo del modelo. En esta tarea, queremos evitar el overfitting porque podemos estar dando demasiado poder predictivo a peculiaridades específicas de la muestra que se empleó para estimar el modelo. Pero al mismo tiempo, queremos evitar tener un modelo con bajo ajuste a la muestra (infraajuste o underfitting en inglés) porque estaríamos ignorando patrones en la muestra útiles para determinar el comportamiento de un nuevo individuo.
De esta manera, necesitaremos otras herramientas para responder la pregunta ¿qué tan bueno es el modelo para predecir? Al proceso de encontrar un modelo que responda esta pregunta empleando parte de la muestra original, se le conoce como validación cruzada del modelo (cross-validation en inglés). En general, para realizar la valoración del poder predictivo de varios modelos candidatos empleando la muestra disponible será necesario contar con:
- una muestra de evaluación que sea diferente a la muestra de estimación o también conocida como la muestra de entrenamiento y
- una métrica qué permita determinar que tan cerca se encuentran las predicciones del valor realmente observado en la muestra de evaluación.
Este capítulo discutiremos estos elementos y cómo realizar la validación de modelos empleando diferentes aproximaciones.
12.2 Estrategias para la validación cruzada de modelos
Para evitar overfitting (sobreajuste) una buena práctica es emplear muestras diferentes para estimar y evaluar la capacidad predictiva de este. En general, cualquier técnica de validación cruzada de modelos implicará dividir la muestra en una muestra de evaluación que sea diferente a la muestra de estimación o también conocida como la muestra de entrenamiento. A esta práctica se le conoce como validación cruzada o en inglés cross-validation123. En las siguientes tres subsecciones se discuten las técnicas de validación cruzada más empleadas.
12.2.1 Método de retención
La técnica de validación cruzada más sencilla implica seleccionar aleatoriamente unas observaciones de la muestra para hacer la estimación (muestra de estimación o muestra de entrenamiento) y otra para evaluar el comportamiento del modelo para predecir (muestra de evaluación). Esta técnica es conocida como el método de retención o holdout method.
En este caso, una parte relativamente pequeña de la muestra es seleccionada al azar124 como muestra de evaluación y la muestra restante es la de estimación. Es común que se emplee el 80% de la muestra para la estimación y el 20% restante para realizar la evaluación. En la Figura 12.1 se presenta un diagrama de esta aproximación. Con la muestra de evaluación se comparan los diferentes modelos de regresión candidatos a ser el mejor modelo para predecir las observaciones. La comparación implica calcular diferentes métricas que discutiremos en la siguiente sección de este capítulo.
Una desventaja de esta aproximación es que la selección del mejor modelo para predecir podría estar determinada por el azar, pues la muestra seleccionada para la evaluación es totalmente aleatoria. Así, si se replicara el ejercicio con otra muestra, el mejor modelo seleccionado podría ser diferente.
Figura 12.1: Diagrama del Método de retención para la evaluación cruzada de modelos
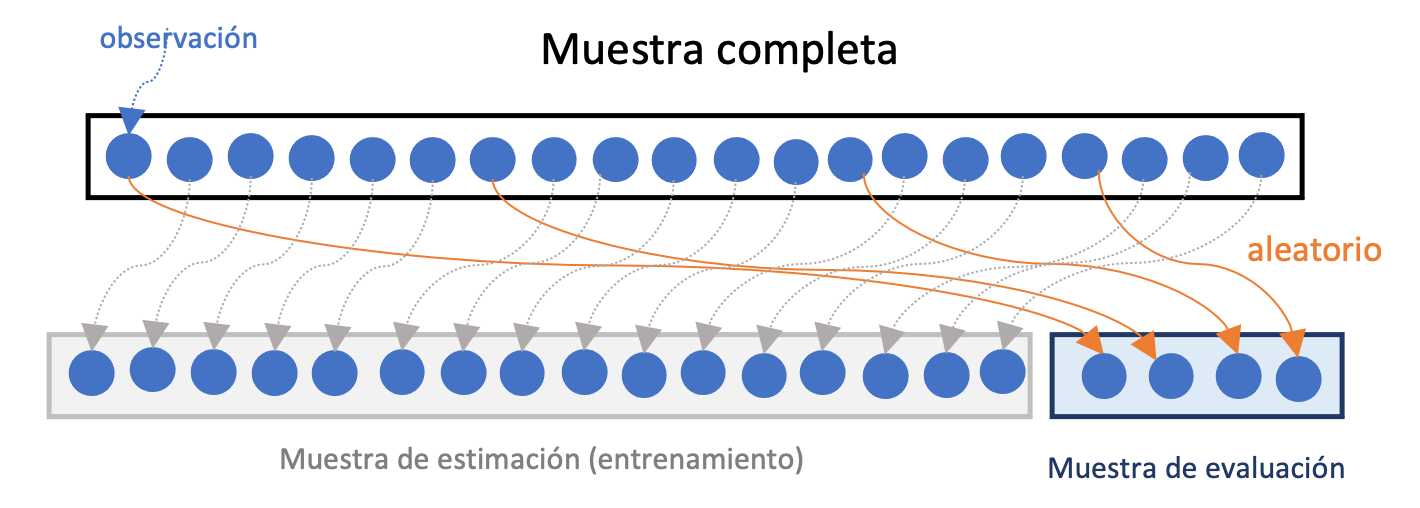
Antes de continuar con otras aproximaciones de validación cruzada de modelos, definamos unos términos importantes en esta literatura. El error del modelo en la muestra de estimación se conoce como el error de entrenamiento. El error del modelo en la muestra de evaluación se conoce como el Error de prueba.
12.2.2 Método LOOCV
Otro método de valoración cruzada comúnmente empleado es el denominado LOOCV (por la sigla en inglés del término Leave one out Cross-validation). En este método, a diferencia del método de retención, no se emplea una única muestra de evaluación elegida al azar. Este método implica realizar la estimación y la valoración del modelo en diferentes muestras.
En este caso, se fija una observación en la muestra de evaluación y se estima el modelo con el resto de observaciones (\(n-1\)). Este proceso se repite hasta que todas las observaciones de la muestra han sido empleadas en una muestra de evaluación. En la Figura 12.2 se presenta un diagrama de esta aproximación. Los modelos candidatos se comparan empleando el promedio de las métricas deseadas para evaluar las predicciones para cada una de las \(n\) muestras de evaluación.Figura 12.2: Diagrama del Método de validación cruzada de LOOCV para la evaluación de modelos
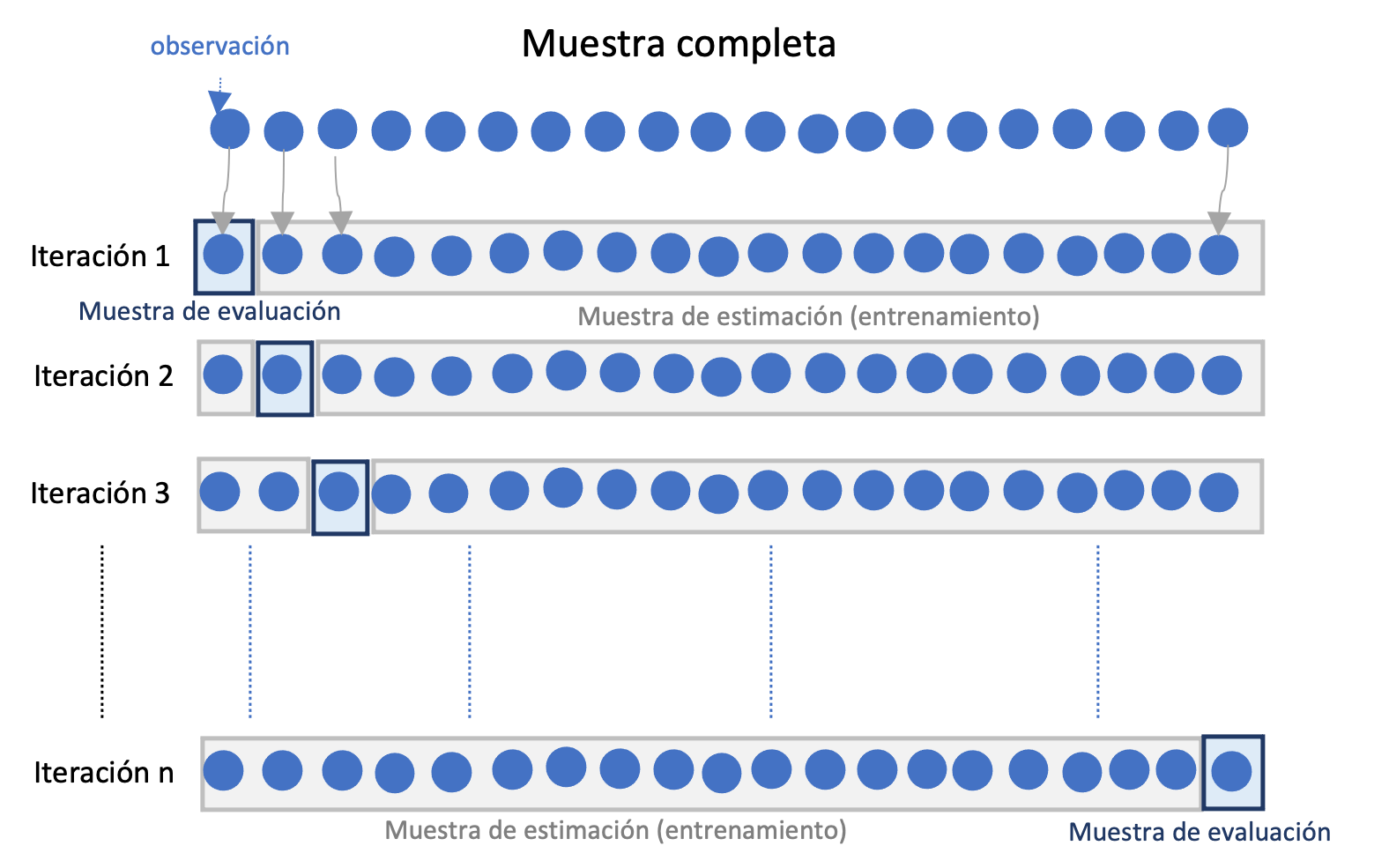
A priori el método LOOCV parecería ser el ideal al emplear todas las observaciones como muestra de evaluación. Esto claramente quitaría el problema de la aleatoriedad que genera el método de retención al momento de seleccionar el mejor modelo para predecir. No obstante, este método puede ser costoso computacionalmente pues requiere estimar el modelo \(n\) veces.
12.2.3 Método de k iteraciones
A parte del costo computacional del método LOOCV, puede existir potencialmente otro problema con esa aproximación. El LOOCV puede generar una mayor variación en el error de predicción si algunas observaciones son atípicas. Para evitar este problema, lo ideal sería utilizar una buena proporción de observaciones como muestra de prueba para evitar el peso de las observaciones atípicas.
El método de validación cruzada de \(k\) iteraciones o k-fold Cross-validation intenta ser un intermedio entre el método de retención y el LOOCV. Este método implica dividir de manera aleatoria la muestra completa en \(k grupos\) de aproximadamente el mismo tamaño. Para cada uno de los \(k\) grupos (o iteraciones) se emplean los restantes \(k-1\) grupos como muestra de estimación y el grupo \(k\) de observaciones se emplea como muestra de evaluación para la cuál se calculan las respectivas métricas deseadas para los modelos a comparar. Y finalmente, para obtener la métrica para todo el ejercicio se calcula el promedio de las \(k\) métricas calculadas para cada modelo. En la Figura 12.3 se presenta un diagrama de esta aproximación. Lo más común en la práctica es emplear un valor de \(k\) de 5 o 10.
Figura 12.3: Diagrama del Método de validación cruzada de \(k\) iteraciones para la evaluación de modelos
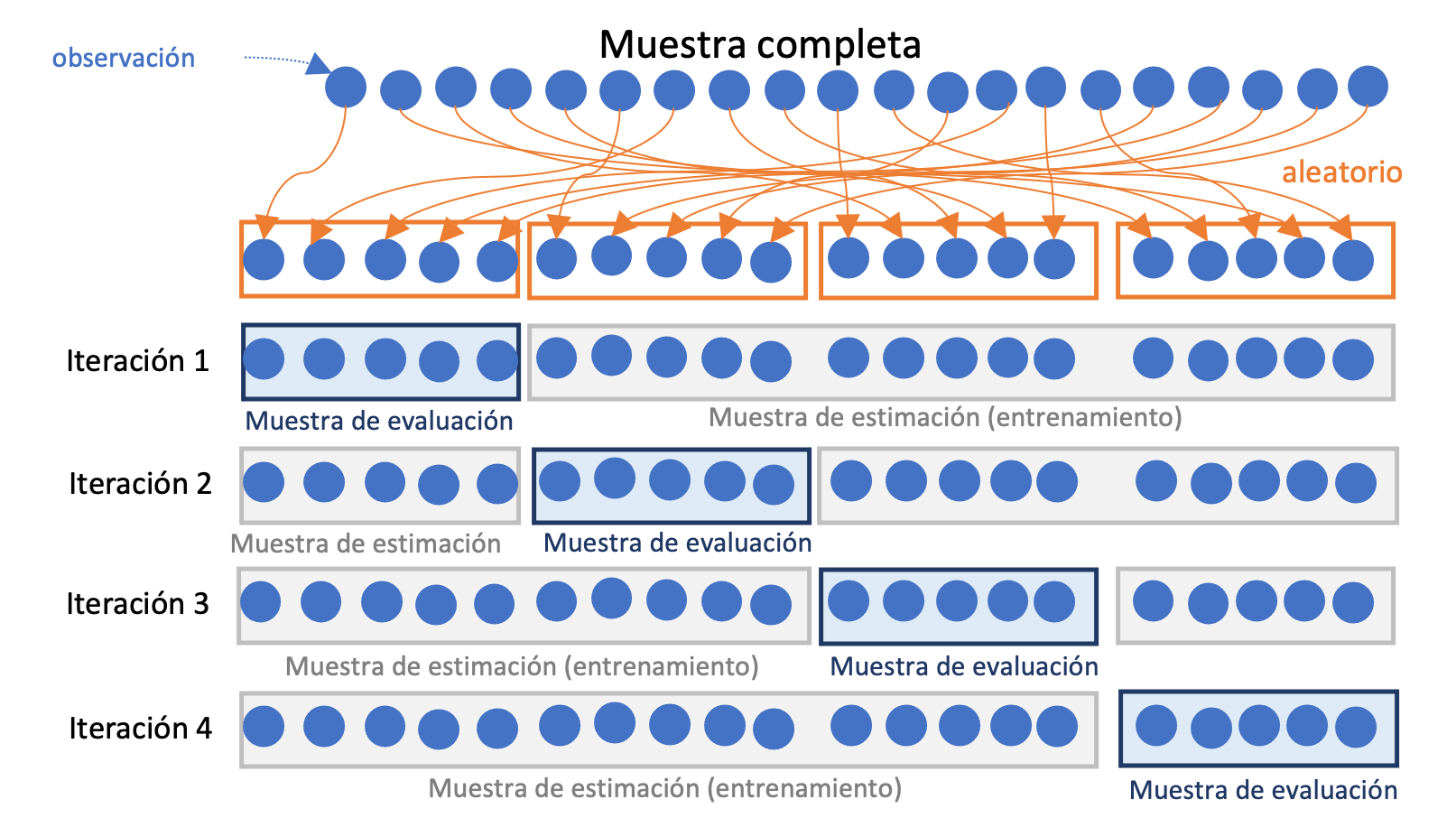
En la práctica, la validación cruzada de \(k\) iteraciones se recomienda generalmente sobre los otros dos métodos debido a su equilibrio entre la variabilidad que puede aparecer por los datos atípicos (método LOOCV), el sesgo fruto de emplear sólo una muestra de evaluación (método de retención) y el tiempo de ejecución computacional.
En la siguiente sección discutiremos las métricas para valorar la precisión de las predicciones.
12.3 Métricas para medir la precisión de las predicciones
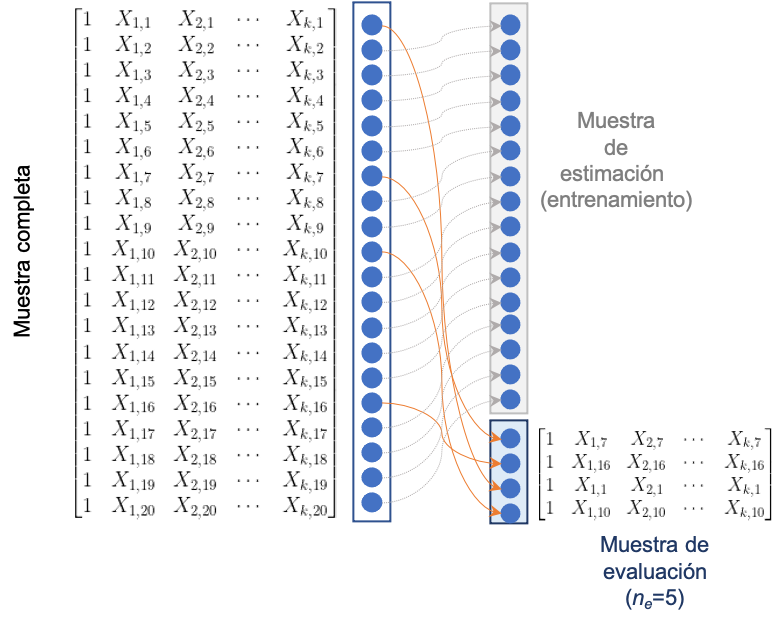
Independientemente del método empleado para generar la muestra o muestras de evaluación, necesitaremos métricas qué permitan evaluar que tan cerca está cada predicción (\({\hat y}_i\)) del valor real observado (\(y_i\)) para las \(n_e\) observaciones que conforman la muestra de evaluación. Las predicciones del modelo se puede construir fácilmente para los valores determinados de las variables explicativas para la \(i\)-esima observación de la muestra de evaluación de la siguiente manera: \[\begin{equation} \hat y_i = \textbf{x}_i^T \hat \beta \tag{12.1} \end{equation}\] donde \(\textbf{x}_i^T\) corresponde al vector de valores que toman las variables explicativas para el individuo \(i\) en la muestra de evaluación. Es decir: \[\begin{equation} \textbf{x}_i^T = \begin{bmatrix} 1 & X_{1,i} & X_{2,i} & \cdots & X_{k,i} \\ \end{bmatrix} \tag{12.2} \end{equation}\] En otras palabras, \(\textbf{x}_i^T\) es la fila de la matriz \(X\) de la muestra completa que corresponde al individuo \(i\) que fue asignado a la muestra de evaluación. En el ejemplo de la Figura 12.4, la muestra de evaluación es de tamaño 5 (\(n_e = 5\)) y la primera observación de la muestra de evaluación es la séptima de la muestra completa.
Figura 12.4: De la muestra completa a la muestra de evaluación (Ejemplo del Método de retención)
Las dos métricas más empleadas para evaluar el comportamiento de las predicciones son:
- RMSE (Raíz media cuadrada del error): \[RMSE = \sqrt {\frac{1}{n_e}\sum\limits_{i = 1}^{n_e} \left( \hat y_i - y_i \right)^2} \]
- MAE (Error absoluto promedio): \[MAE = {\frac{1}{n_e}\sum\limits_{i = 1}^{n_e} \left| \hat y_i - y_i \right|} \]
La \(RMSE\) y el \(MAE\) intenta que los errores negativos y positivos no se cancelen al ser sumados. El \(MAE\) emplea el valor absoluto de los errores de prueba para eliminar los signos, mientras que la \(RMSE\) eleva los errores de prueba al cuadrado125. Esto implica que la \(RMSE\) al elevar al cuadrado penalice más errores de prueba grandes que errores de prueba pequeños, mientras que el \(MAE\) pondera igual a todos los errores de prueba. Estas dos métricas tienen en común que una menor métrica es deseable.
Cada métrica pone énfasis en un aspecto diferente y por eso es una buena práctica emplear la mayor cantidad de métricas posibles para la selección del modelo que se comporta mejor fuera de la muestra de estimación. La selección de la o las métricas adecuadas para la evaluación de los modelos dependerá de la pregunta de negocio y de lo que es deseable para cada organización. En las siguiente sección se presenta un ejemplo práctico.
12.4 Validación cruzada en R
Para mostrar cómo responder a la pregunta ¿cuál modelo tiene un mejor poder predictivo?, emplearemos los mismos datos del Capítulo 6. En dicho capítulo empleamos una muestra de 150 observaciones que contenía una variable dependiente (\(y_i\)) y 25 posibles variables explicativas \(X_j,i\) donde \(j=1,2,...,25\). Los datos se encuentran disponibles en el archivo DATOSautoSel.txt126.
En Capítulo 6 (sección 6.4.2) evaluamos 3 posibles modelos teniendo en cuenta que nuestra tarea era encontrar el mejor modelo para explicar la variable \(y_i\). Ahora en este caso supongamos que queremos encontrar un modelo para hacer analítica predictiva y no diagnóstica. Es decir, ahora queremos comparar los tres modelos candidatos con la óptica de encontrar el mejor modelo predictivo.
Empecemos cargando los datos y estimando los siguientes tres modelos:
\[\begin{equation} {y_i} = {\beta _1} + {\beta _2}x{1_i} + {\beta _3}x{2_i} + {\beta _4}x{3_i} + {\beta _5}x{4_i} + {\beta _6}x{5_i} + {\beta _7}x{20_i} + {\varepsilon _i} \tag{12.3} \end{equation}\]
\[\begin{equation} {y_i} = {\beta _1} + {\beta _3}x{2_i} + {\beta _4}x{3_i} + {\beta _5}x{4_i} + {\beta _6}x{5_i} + {\beta _7}x{20_i} + {\varepsilon _i} \tag{12.4} \end{equation}\]
\[\begin{equation} {y_i} = {\beta _1} + {\beta _3}x{2_i} + {\beta _4}x{3_i} + {\beta _5}x{4_i} + {\beta _6}x{5_i} + {\varepsilon _i} \tag{12.5} \end{equation}\]
datos <- read.table("./Data/DATOSautoSel.txt", header = TRUE)
modeloA <- lm(y ~ x1 + x2 + x3 + x4 + x5 + x20, datos)
modeloB <- lm(y ~ x2 + x3 + x4 + x5 + x20, datos)
modeloC <- lm(y ~ x2 + x3 + x4 + x5, datos)Recordemos que estos tres modelos tenían todas sus variables significativas individual y conjuntamente (Ver Cuadro 12.1). Además podrás constatar que los supuestos del teorema de Gauss-Markov se cumplen en los tres casos.
| Modelo A | Modelo B | ModeloC | |
|---|---|---|---|
| (Intercept) | 11.46*** | 12.44*** | 11.92*** |
| (1.34) | (1.31) | (1.31) | |
| x1 | 0.66* | ||
| (0.26) | |||
| x2 | 1.66*** | 1.78*** | 1.70*** |
| (0.26) | (0.27) | (0.27) | |
| x3 | 0.93*** | 0.95*** | 0.86** |
| (0.26) | (0.26) | (0.26) | |
| x4 | 1.09*** | 1.21*** | 1.03*** |
| (0.25) | (0.25) | (0.24) | |
| x5 | 1.06*** | 1.16*** | 1.00*** |
| (0.25) | (0.25) | (0.25) | |
| x20 | -0.71** | -0.61* | |
| (0.27) | (0.27) | ||
| R2 | 0.72 | 0.71 | 0.70 |
| Adj. R2 | 0.71 | 0.70 | 0.69 |
| Num. obs. | 150 | 150 | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
Para realizar la validación cruzada podemos emplear diferentes paquetes, pero tal vez de los más empleados es el paquete caret (Kuhn, 2020). Ahora procedamos a realizar la validación cruzada de estos tres modelos con cada uno de los tres métodos estudiados.
12.4.1 Método de retención
Para seleccionar aleatoriamente las observaciones que harán parte de la muestra de estimación (entrenamiento) y la de evaluación se puede emplear la función createDataPartition(). Esta función típicamente incluye los siguientes argumentos que serán útiles para este caso:
donde:
- y: es un vector columna que corresponde a la variable dependiente.
- times: el número de muestras (particiones) que se desean crear. Por defecto times = 1.
- p: el porcentaje de observaciones de la muestra original que estarán en la muestra de entrenamiento. Por defecto p = 0.5.
- list: un valor lógico que le indica a la función en qué formato presentar los resultados. Si list = TRUE entonces el objeto será de clase list y en caso contrario será un objeto de clase matrix. Por defecto list = TRUE.
En nuestro caso,
# se carga el paquete
library(caret)
# se fija una semilla para los números aleatorios
set.seed(123)
# muestra de estimación
est.index <- createDataPartition(y = datos$y, p = .8, list=FALSE)
head(est.index, 3)## Resample1
## [1,] 2
## [2,] 6
## [3,] 7Esto genera el objeto est.index de clase list que contiene las filas seleccionadas al azar para conformar la muestra de estimación. Entonces, podemos proceder a crear las muestras de estimación y evaluación.
# muestra de estimación
datos.est <- datos[est.index, ]
# muestra de evaluación
datos.eval <- datos[-est.index, ]Ahora tendremos que reestimar los modelos con la muestra de entrenamiento (muestra de estimación).
# estimación de modelos con muestra de estimación
modeloA.ret <- lm(y ~ x1 + x2 + x3 + x4 + x5 + x20, datos.est)
modeloB.ret <- lm(y ~ x2 + x3 + x4 + x5 + x20, datos.est)
modeloC.ret <- lm(y ~ x2 + x3 + x4 + x5, datos.est)Ahora, procedamos a generar las predicciones con la función predict() de R127. Esta función realiza la operación que se presenta en la ecuación ((12.1)). Es decir, encuentra los valores estimados para la variable dependiente (\(\hat y_i\)) (predicciones) dado unos coeficientes estimados para un modelo. Los argumentos necesarios, para este caso, en esta función son el modelo y los nuevos datos para los cuales se hará la predicción.
# predicciones para el modelo A para la muestra de evaluación
pred.A <- predict(modeloA.ret, datos.eval)
head(pred.A,2)## 1 3
## 39.38654 36.63466# predicciones para el modelo A para la muestra de evaluación
pred.B <- predict(modeloB.ret, datos.eval)
# predicciones para el modelo A para la muestra de evaluación
pred.C <- predict(modeloC.ret, datos.eval)Ahora calculemos la \(RMSE\) y el \(MAE\) para cada uno de los tres modelos. Esto lo podemos hacer con las funciones RMSE() y MAE() del paquete caret. Las dos funciones emplean como primer argumento las predicciones y como segundo argumento los valores observados. En nuestro caso podemos encontrar estas métricas con el siguiente código:
# Cálculo del RMSE
RMSE.modeloA <- RMSE(pred.A, datos.eval$y)
RMSE.modeloB <- RMSE(pred.B, datos.eval$y)
RMSE.modeloC <- RMSE(pred.C, datos.eval$y)
# Cálculo del MAE
MAE.modeloA <- MAE(pred.A, datos.eval$y)
MAE.modeloB <- MAE(pred.B, datos.eval$y)
MAE.modeloC <- MAE(pred.C, datos.eval$y)| RMSE | MAE | |
|---|---|---|
| Modelo A | 2.093 | 1.615 |
| Modelo B | 2.183 | 1.717 |
| Modelo C | 2.049 | 1.644 |
| Fuente: elaboración propia. |
Ahora podemos comparar los resultados. En el Cuadro 12.2 se presenta un resumen de estos resultados. El modelo que minimiza la \(RMSE\) es Modelo C y el que minimiza el MAE es Modelo A. Veamos si estos resultados se mantienen con los otros métodos de validación cruzada.
12.4.2 Método LOOCV
El método LOOCV puede ser implementado fácilmente empleando el paquete caret. En este caso debemos emplear dos funciones. La primera es función trainControl(). Esta función establece el método (method) que se empleará para la validación cruzada. Definamos el método a LOOCV de la siguiente manera.
Ahora podemos emplear la función principal para hacer la valoración: train() . Para emplear cualquier método recursivo de valoración cruzada, esta función necesita los siguientes argumentos:donde:
- formula: es la fórmula correspondiente al modelo que será evaluado .
- data: objeto de clase data.frame con los datos (la muestra completa).
- method: en nuestro caso deberá fijarse en method = “lm” porque estamos evaluando modelos lineales. Es importante anotar que este no es el valor por defecto de este argumento, así que es importante especificar este argumento de esta manera. Las otras opciones de este argumento no son relevantes para nuestro caso.
- trControl: este argumento define que tipo de valoración que se desea realizar.
Para implementar el método LOOCV para el primer método se puede emplear el siguiente código:
LOOCV.modeloA <- train(y ~ x1 + x2 + x3 + x4 + x5 + x20,
data = datos,
method = "lm",
trControl = train.control)
# resultados
LOOCV.modeloA## Linear Regression
##
## 150 samples
## 6 predictor
##
## No pre-processing
## Resampling: Leave-One-Out Cross-Validation
## Summary of sample sizes: 149, 149, 149, 149, 149, 149, ...
## Resampling results:
##
## RMSE Rsquared MAE
## 2.505238 0.6922227 1.99463
##
## Tuning parameter 'intercept' was held constant at a value of TRUE| RMSE | MAE | |
|---|---|---|
| Modelo A | 2.505238 | 1.99463 |
| Modelo B | 2.547376 | 2.039905 |
| Modelo C | 2.569015 | 2.021161 |
| Fuente: elaboración propia. |
Ahora realice la misma valoración para los otros dos modelos. Los resultados se presentan en el Cuadro 12.3. Nuevamente, el modelo que minimiza la \(RMSE\) y \(MAE\) es Modelo A. Como se discutió anteriormente este resultado no necesariamente debe coincidir entre el método de retención y el LOOCV.
12.4.3 Método de k iteraciones
El método de \(k\) iteraciones puede ser implementado de manera similar al método a LOOCV. Lo único que debemos modificar es la definición de la función trainControl(). Empleemos 5 iteraciones (\(k = 5\)).
Y finalmente, podemos implementar el método de \(k\) iteraciones empleando el mismo código anteriormente discutido. Es decir:
fold.5.modeloA <- train(y ~ x1 + x2 + x3 + x4 + x5 + x20,
data = datos,
method = "lm",
trControl = train.control)
# resultados
fold.5.modeloA## Linear Regression
##
## 150 samples
## 6 predictor
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 119, 121, 120, 120, 120
## Resampling results:
##
## RMSE Rsquared MAE
## 2.494089 0.7040192 1.974375
##
## Tuning parameter 'intercept' was held constant at a value of TRUE| RMSE | MAE | |
|---|---|---|
| Modelo A | 2.494089 | 1.974375 |
| Modelo B | 2.590889 | 2.097228 |
| Modelo C | 2.559285 | 2.02295 |
| Fuente: elaboración propia. |
Ahora realice la misma valoración para los otros dos modelos. Los resultados se presentan en el Cuadro 12.4. Nuevamente, el modelo que minimiza la \(RMSE\) y \(MAE\) es Modelo A. Esto implica que con los tres métodos de validación cruzada podemos concluir que el mejor modelo para hacer predicciones es el Modelo A.
En este caso esta conclusión coincide con el mejor modelo detectado cuando estábamos interesados en encontrar el mejor modelo para entender qué ocurría con la muestra (analítica diagnóstica). Este resultado no es común y por esto debemos realizar el análisis presentado si se desea realizar analítica predictiva.
12.5 Intervalo de confianza para la predicción
En este capítulo hemos discutido cómo seleccionar entre modelos candidatos cuando el objetivo es realizar analítica predictiva. Una vez seleccionado el mejor modelo para realizar las predicciones podemos proceder a realizar predicciones con dicho modelo, empleando la muestra completa para estimar el modelo y aplicar los coeficientes estimados al nuevo individuo para el cuál se quiere predecir el valor de la variable explicativa.
Antes de finalizar es importante anotar que emplear la expresión (12.1) producirá un estimador puntual para el valor esperado de la variable dependiente. En algunas situaciones podría ser interesante producir un intervalo de confianza para la predicción porque de esta manera estaremos generando una región con una certidumbre del \((1-\alpha) \times 100\)%.
Para construir un intervalo de confianza para la predicción para un nuevo individuo128 será necesario suponer una distribución para los errores del modelo. Si se supone una distribución normal, entonces el intervalo de confianza para la predicción de la variable dependiente para un individuo \(i\) cuyas valores de las variables explicativas toman el valor de \(\textbf{x}_{p,i}^T\) será: \[\begin{equation} \hat y_{p,i} \pm t_{\alpha/2,n-k} \cdot \sqrt{s^2 \cdot \textbf{x}_{p,i}^T \left ( X^T X \right )^{-1}\textbf{x}_{p,i} } \tag{12.6} \end{equation}\] donde \(s^2\) es la varianza estimada del error y \(t_{\alpha/2,n-k}\) es el valor de la distribución \(t\) con \(n-k\) grados de libertad129 y
\[\begin{equation} \hat y_{p,i} = \textbf{x}_{p,i}^T \hat \beta \tag{12.7} \end{equation}\]
Para construir el intervalo de confianza para la predicción individual se puede realizar en R con la función predict() de la base de R. Esta función realiza la operación que se presenta en la ecuación (12.6). El único argumento adicional que se debe tener en cuenta al discutido en las secciones anteriores es interval que permite establecer el cálculo del intervalo de confianza. Y para que se calcule el intervalo de confianza para la predicción bajo el supuesto de errores con una distribución normal, este argumento debe ser interval = “prediction”. Por defecto la función calcula un intervalo de confianza del 95%, si se desea modificar el nivel de confianza, se puede emplear el argumento level.
Por ejemplo, supongamos que empleamos el Modelo A con todos los datos disponibles y queremos hacer una predicción para un individuo que tenga los siguientes valores para las variables explicativas: \(x1_{p} = 4\), \(x2_{p} = 3\), \(x3_{p} = 5\), \(x4_{p} = 2\), \(x5_{p} = 4\) y \(x20_{p} = 1\). Esto se puede realizar de la siguiente manera:
# nuevos datos
nuevos.datos <- data.frame(x1 = 4, x2 = 3, x3 = 5, x4 = 2, x5 = 4, x20 = 1)
prediccion <- predict(modeloA, nuevos.datos, interval = "prediction", level = 0.95)
prediccion## fit lwr upr
## 1 29.44943 24.22057 34.6783En este caso lo pronóstico para el individuo cuyas las variables explicativas son \(x1_{p} = 4\), \(x2_{p} = 3\), \(x3_{p} = 5\), \(x4_{p} = 2\), \(x5_{p} = 4\) y \(x20_{p} = 1\) es de 29.45. El límite inferior del intervalo del 95% de confianza es 24.22 y el límite superior es 34.68. Si el modelo tiene problemas heteroscedasticidad130 y dicho problema se resolvió con una matriz de varianzas y covarianzas H.C., entonces la predicción debería tener en cuenta dicha corrección. Esto se puede realizar con la función Predict() del paquete car (Fox & Weisberg, 2019). Esta función tiene argumentos similares a la función predict.lm() del paquete central de R. Una gran diferencia de la función Predict() es el argumento vcov. que permite especificar la corrección H.C. que se desea emplear. Por ejemplo, mantengamos el mismo ejemplo anterior y supongamos que existe un problema de heteroscedasticidad que se soluciona con HC3.
# se cargan los paquetes
library(car)
library(sandwich)
Predict(modeloA, nuevos.datos, interval = "prediction",
level = 0.95, vcov.=vcovHC(modeloA, "HC3"))## fit lwr upr
## 1 29.44943 24.20053 34.69834Si el supuesto de normalidad de los errores no se cumple, una opción es simular la distribución de los errores empleando el método de bootstrapping. En el anexo de este capítulo (Ver sección 12.7) se describe el método de bootstrapping y el código que se puede emplear. Recuerden que ya habíamos discutido como comprobar el supuesto de normalidad de los residuales en la sección 9.7 cuatro pruebas de normalidad: Shapiro-Wilk (Shapiro & Francia, 1972), Kolmogorov-Smirnov (Kolmogorov, 1933), Cramer-von Mises (Cramér, 1928) y Anderson-Darling (Anderson & Darling, 1952).
12.6 Comentarios finales
Las técnicas de validación cruzada que hemos estudiado en este capítulo permiten evaluar el desempeño predictivo de diferentes modelos candidatos a ser el mejor modelo predictivo. Los modelos candidatos fueron construidos con los algoritmos de selección automática estudiados en el Capítulo 6.
Una práctica diferente para seleccionar modelos para hacer analítica predictiva es seleccionar el mejor modelo empleando directamente la validación cruzada. Es decir, empleando los métodos de LOOCV o \(k\) iteraciones para comparar los posibles modelos empleando el comportamiento predictivo y no el ajuste del modelo a la muestra como lo hicimos en el Capítulo 6. Esto se puede realizar empleando la librería caret, si les interesa pueden encontrar en la documentación del paquete información de cómo desarrollar esta tarea.
Para terminar es importante recordar que en la práctica, la validación cruzada de \(k\) iteraciones se recomienda generalmente sobre los otros dos métodos estudiados en este capítulo. La razón de preferir este método es que presenta un equilibrio entre la variabilidad que puede aparecer por los datos atípicos (método LOOCV), el sesgo fruto de emplear sólo una muestra de evaluación (método de retención) y el tiempo de ejecución computacional.
12.7 Anexo: Método de Bootstraping para construcción de intervalos de confianza para las predicciones
Existen diferentes métodos para la construcción de intervalos de confianza para las predicciones empleando bootstrapping, tal vez el mas sencillo es el propuesto por Davison & Hinkley (1997) (sección 6.3.3).
Partamos de reconocer que el error de predicción está dado por:
\[\begin{equation} e_{p,i} = y_{p,i} - {\hat y}_{p,i} \tag{12.8} \end{equation}\] Por lo tanto, \[\begin{equation} y_{p,i} ={\hat y}_{p,i} + e_{p,i} \tag{12.9} \end{equation}\] Un intervalo de confianza del 90% implica encontrar un estimador del percentil quinto (\(e_{p}^{5}\)) y 95 (\(e_{p}^{95}\)) del error de predicción (\(e_{p,i}\)). En este caso el intervalo estará definido como: \[\begin{equation} \left [ {\hat y}_{p,i} + e_{p}^{5} \; , \; {\hat y}_{p,i} + e_{p}^{95}\right ] \tag{12.10} \end{equation}\]
Ahora el problema es encontrar los percentiles 5 y 95 del error de predicción. Reescribamos el error de predicción de la siguiente manera: \[\begin{align*} e_{p,i} &= y_{p,i} - {\hat y}_{p,i}\\ &= \textbf{x}_{p,i}^T \beta + \varepsilon_{p,i} -\textbf{x}_{p,i}^T \hat\beta\\ &= \textbf{x}_{p,i}^T \left ( \beta - \hat \beta \right )+ \varepsilon_{p,i} \end{align*}\]
La estrategia consistirá en muestrear (a esto se le denomina bootstrap) muchas veces de \(e_{p,i}\) y luego calcular los percentiles de la manera habitual. Así, por ejemplo podemos sacar 10 mil muestras de \(e_{p,i}\), y luego estimemos los percentiles 5 y 95. Esto en otras palabras será encontrar el error de predicción simulado tal que 500 de ellos sean menores que él para encontrar el percentil 5. Y para el percentil 95 la observación simulada tal que 9500 sean menores que ella.
Para muestrear \(\textbf{x}_{p,i}^T \left ( \beta - \hat \beta \right )\), podemos hacer un bootstrap de los errores. Así, en cada réplica bootstrap (cada muestra), se extrae \(n\) veces con reemplazo de los residuales estandarizados (residuales divididos por la varianza) para obtener \(\varepsilon^*\) (vector de errores simulados para todas las observaciones originales), y luego se reconstruye un nuevo vector de observaciones para la variable dependiente: \(y^* = \textbf{x}\hat \beta + \varepsilon^*\). Esto permite calcular con el nuevo conjunto de datos (\(y^*\) y la matriz \(\textbf{x}\) original) un nuevo vector de coeficientes (\(\hat \beta^*\)) para cada muestra (iteración). Por último, \(\textbf{x}_{p,i}^T \left ( \beta - \hat \beta \right )\) puede ser aproximado por \(\textbf{x}_{p,i}^T \left ( \beta - \hat \beta^* \right )\).
Ahora queda faltando como encontrar \(\varepsilon _{p,i}\). Dado los supuestos sobre el error del Teorema de Gauss-Markov, la manera natural de muestrear \(\varepsilon_{p,i}\) es utilizar los residuos que tenemos de la regresión \(\left ( \hat\varepsilon _{1}^*, \hat\varepsilon _{2}^*, \dots \hat\varepsilon _{n}^* \right )\) en cada iteración. Los residuos tienen varianzas diferentes y, por lo general, demasiado pequeñas, por lo que querremos muestrear de los residuos corregidos por la varianza.
Resumiendo, el algoritmo para hacer un intervalo de confianza con un nivel de significancia de \(\alpha\) será:
- Realizar la predicción \(\hat y_{p,i} = \textbf{x}_{p,i}^T \hat \beta\)
- Construir el vector de residuales ajustados por la varianza \(\left [ s_1 - \bar s , s_2 - \bar s, \dots, s_n - \bar s\right ]\) donde \(s_i = \hat\varepsilon_i/ \sqrt(1-h_{i})\) y \(h_i\) es el leverage de la observación \(i\)131.
- Seleccionar una muestra de tamaño \(n\) de los residuales ajustados. Es decir, los errores de bootstrap \(\left ( \hat\varepsilon _{1}^*, \hat\varepsilon _{2}^*, \dots \hat\varepsilon _{n}^* \right )\)
- Construir un nuevo vector de variables explicativas simuladas. El \(y\) de bootstrap \(y^* = \textbf{x}\hat\beta + \varepsilon^*\)
- Estimar por MCO los coeficientes de bootstrap. Es decir, \(\hat \beta^* = \left ( \textbf{x}^T \textbf{x} \right )^{-1}\textbf{x}^Ty^*\)
- Obtener los residuales de bootstrap. En otras palabras, \(\hat \varepsilon^* = y^*-\textbf{x}\hat \beta^*\)
- Calcular los residuales de bootstrap ajustados por varianza (\(s^* - \bar s\)).
- Seleccionar al azar uno de los residuales de bootstrap ajustados por varianza (\(\varepsilon _{p,i}^*\)).
- Calcular \(e_{p,i}\) como \(e_{p,i}^*=\textbf{x}_{p,i}^T \left ( {\hat \beta} - {\hat\beta^*} \right )+ \varepsilon_{p,i}^*\)
- Repetir 3 a 9 \(R\) veces132.
- Encontrar los percentiles \(\alpha/2 \times 100\) (\(e_{p}^{\alpha/2 \times 100}\)) y \((1-\alpha/2) \times 100\) (\(e_{p}^{(1-\alpha/2) \times 100}\)) de los \(e_{p,i}^*\) simulados (son \(R\) simulaciones disponibles).
- Construir el intervalo de bootstrapping como \(\left [ {\hat y}_{p,i} + e_{p}^{5} \; , \; {\hat y}_{p,i} + e_{p}^{95}\right ]\)
Para construir una función que realice este algoritmo construiremos dos funciones auxiliares. La primera realiza el paso 2 que corresponde a la estimación de los residuales ajustados por la varianza sobre un objeto de clase lm. Para esto construiremos la función errores.ajustados.varianza().
# función para crear los errores ajustados por varianza (paso 2)
# argumento objeto lm
errores.ajustados.varianza <- function(modelo){
require(MASS)
require(Hmisc)
leverage <- influence(modelo)$hat
s.resid <- residuals(modelo)/sqrt(1-leverage)
s.resid <- s.resid - mean(s.resid)
return(s.resid)
}La segunda función auxiliar realizará los pasos 3 a 9 del algoritmo empleando un objeto de clase lm (modelo), un vector de residuales ajustados por la varianza (s) y unos nuevos datos para la predicción (nuevos.datos). A esta nueva función la llamaremos ic.boot.predic.iteration().
# función para correr pasos 3 a 9
# argumentos
# modelo = objeto lm
# s = vector de residuales ajustados por la varianza
# nuevos datos = data.frame con datos para la predicción
ic.boot.predic.iteration <- function(modelo,s,nuevos.datos){
# pasos 3 a 9
require(MASS)
require(Hmisc)
# residuales de bootstrap
ep.star <- sample(s,size=length(modelo$residuals),replace=TRUE)
# crea y de bootstrap
y.star <- fitted(modelo) + ep.star
# coeficientes de bootstrap
x <- model.frame(modelo)[,-1]
bs.data <- cbind(y.star, x)
bs.modelo <- lm(y.star ~ ., bs.data)
# residuales de bootstrap ajustados
bs.lev <- influence(bs.modelo)$hat
bs.s <- residuals(bs.modelo)/sqrt(1-bs.lev)
bs.s <- bs.s - mean(bs.s)
# Selección del error de predicción
xb.xb <- coef(modelo)["(Intercept)"] - coef(bs.modelo)["(Intercept)"]
xb.xb <- xb.xb + (coef(modelo)[-1] - coef(bs.modelo)[-1])*nuevos.datos
return(unname(xb.xb + sample(bs.s,size=1)))
}Ahora construyamos la función ic.boot.predic() que ponga todo junto, replicando los pasos 3 a 9 \(R\) veces.
# función para crear IC para predicción con bootstrapping
# argumentos
# modelo = objeto lm
# s = vector de residuales ajustados por la varianza
# nuevos datos = data.frame con datos para la predicción
# R = número de iteraciones para el bootstrapping, por defecto R = 1000
# alpha = nivel de significancia, por defecto alpha = 0.05
ic.boot.predic <- function(modelo, nuevos.datos, R= 1000, alpha = 0.05){
# paso 1
y.p <- predict.lm(modelo, nuevos.datos)
# paso 2
s <- errores.ajustados.varianza(modelo)
# paso 10 (repite pasos 3 a 9 R veces)
ep.draws <- replicate(R ,
ic.boot.predic.iteration(modelo, s, nuevos.datos))
# paso 11 y 12 encontrar los percentiles y construcción intervalo
res <- y.p + quantile(as.numeric(ep.draws),
probs=c(alpha/2, 1 - alpha/2 ))
return(c(fit = y.p, lwr = res[1], upr = res[2]) )
}Apliquemos esta función al ejemplo que trabajamos en este capítulo y comparemos el resultado con la aproximación tradicional con el supuesto de normalidad.
## fit.1 lwr.2.5% upr.97.5%
## 29.44943 23.73147 34.98249## fit lwr upr
## 1 29.44943 24.22057 34.6783Referencias
Noten que esta técnica solo tiene sentido en datos de corte transversal, donde el orden de los datos no es importante. Para muestras de series de tiempo el orden es importante y seleccionar una muestra de manera aleatoria estaría negando una de las características más importantes en las series de tiempo. Es por esto que cuando realizamos pronósticos emplearemos otras técnicas para validar los modelos. Para mayor detalle ver Alonso & Hoyos (2024)↩︎
por muestreo aleatorio sin reposición.↩︎
Después de sumarlos les saca la raíz cuadrada para retornarlos a su escala inicial.↩︎
Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/.↩︎
Para ser más preciso se empleará la función predict.lm(). La función predict() es una función genérica para predicciones que de acuerdo con la clase de objeto que se emplee como argumento redirecciona a la función respectiva. Como empleamos objetos de clase lm la función predict() redirecciona a la función predict.lm().↩︎
Técnicamente hay que hacer una distinción entre un intervalo de confianza para la predicción individual y un intervalo para el valor esperado (valor promedio). Si bien en ambos casos el centro del intervalo de confianza es el mismo los intervalos tienen amplitudes diferentes. En general, es mucho más fácil estimar en promedio cuál sería el valor de la variable dependiente si aparecen muchos individuos con unos valores determinados para las variables explicativas que predecir el valor de la variable dependiente para un solo individuo con unos valores determinados para las variables explicativas. En el caso del intervalo de confianza para el valor esperado, se puede invocar el Teorema del Límite Central y, por tanto, no se requiere ningún supuesto. En la introducción del Capítulo 3 se presentó una discusión del Teorema del Límite Central. Caso muy diferente para el intervalo de confianza de una predicción individual en la cuál es necesaria suponer la distribución del término de error.↩︎
En la sección 3.2 se discutió cómo si un estimador sigue una distribución normal y se tiene que estimar la varianza (\(\sigma ^2\)) del error, entonces se tendrá que emplear una distribución \(t\) con \(n-k\) grados de libertad.↩︎
El problema de autocorrelación no se considera, pues los datos para esta tarea de predicción (y no de proyección) deberán ser de corte transversal y no una serie de tiempo.↩︎
El leverage de una observación \(i\) corresponde al elemento i-ésimo de la diagonal de la matriz \(\textbf{H}\) que está definida como \(\textbf{H}=\textbf{x}\left ( \textbf{x}^T \textbf{x} \right )^{-1}\textbf{x}^T\). Es decir, \(h_i = \left [ \textbf{H} \right ]_{i,i}\).↩︎
\(R\) debe ser un número relativamente grande como 10 mil.↩︎