6 Modelo kNN (k vecinos cercanos)
Objetivos del capítulo
Al finalizar la lectura de este capítulo el estudiante estará en capacidad de:
- Explicar en sus propias palabras la utilidad de un modelo \(kNN\).
- Emplear un modelo \(kNN\) en R.
- Calcular métricas de la bondad de un modelo de clasificación estimado por medio de un modelo \(kNN\).
- Encontrar los pronósticos de clasificación de un modelo \(kNN\).
6.1 Introducción
Como lo hemos discutido a lo largo de este libro, una de las tareas del Business Analytics más comunes es clasificar individuos en varias categorías o clases. Los modelos de clasificación que comúnmente se emplean tienen dos orígenes: modelos estadísticos y modelos de aprendizaje de máquinas42. En los capítulos anteriores discutimos modelos estadísticos. Ahora nos concentraremos en una técnica de inteligencia artificial conocida como \(kNN\).
El aprendizaje automático (o inteligencia artificial) es la ciencia que emplea algoritmos que permiten a los computadores aprender, sin ser explícitamente programados (Ng, 2014). En la inteligencia artificial, los algoritmos son expuestos a una muestra (conocida como training set o muestra de entrenamiento) para aprender patrones en los datos que permitan replicar ese patrón de comportamiento en una nueva muestra (muestra de evaluación).
Hay dos tipos de aprendizaje automático: el supervisado y el no supervisado. En el aprendizaje supervisado, los datos de entrenamiento contienen la variable objetivo y otras variables. El algoritmo emplea diferentes iteraciones y formas funcionales para encontrar el patrón en el que las variables en la muestra se asocian a la variable objetivo (pueden ser más de una). En este caso, tenemos datos de entrenamiento etiquetados previamente por un “experto” tanto para la variable objetivo \(y_i\), así como de las demás variables (\(X_{1,i}, X_{2,i},\cdots, X_{n,i}\)). En este sentido, la meta de los modelos de aprendizaje supervisado es predecir con las variables \(X_{1,i}, X_{2,i},\cdots, X_{n,i}\) la variable objetivo (\(y_i\)). La variable objetivo puede ser una variable cuantitativa (continua o discreta) o puede ser cualitativa (clases). En el segundo caso, cuando \(y_i\) corresponde a clases, el problema que resuelve el modelo de aprendizaje supervisado será uno de clasificación.
Por otro lado, en los modelos de aprendizaje no supervisado no se cuenta con una variable objetivo etiquetada. Se cuenta con observaciones de muchas variables (\(X_{1,i}, X_{2,i},\cdots, X_{p,i}\)) y el objetivo es descubrir factores no observados, estructuras, o una representación más simple de los datos. Noten que estos modelos son útiles para:
- Resumir información como lo hace una aproximación matemática tradicional como el PCA,
- Clasificar observaciones, como la aproximación estadística del clustering jerárquico.
- Encontrar asociaciones o leyes de co-ocurrencia en el análisis de canasta (Ver Alonso & Arboleda (2024) para una discusión de la tarea de encontrar reglas de asociación).
En este Capítulo nos dedicaremos a un algoritmo de aprendizaje supervisado conocido como k vecinos más próximos (\(kNN\) por su sigla del inglés k-nearest neighbors).
La idea de este algoritmo, a diferencia del modelo Logit, no implica calcular parámetros (como los \(\beta\)s) y, por eso, se conoce como un modelo no paramétrico43. La idea detrás de este método es encontrar la probabilidad de que un elemento (\(i\)) pertenezca a la clase \(j\) (\(C_j\)) empleando la información contenida en las variables \(X_{1,i}, X_{2,i},\cdots, X_{p,i}\). Para encontrar dicha probabilidad no es necesario suponer una distribución (como si lo hace el modelo Logit).
El algoritmo \(kNN\) implica buscar \(k\) “vecinos” cercanos para cada elemento (\(i\)) que puedan “votar” cuál debería ser la clase del elemento \(i\). Por ejemplo, supongamos que contamos con dos clases: compra el producto (positivo) y no lo compra (negativo) y tenemos dos variables: nivel de ingresos (\(X_{1,i}\)) y los años de educación (\(X_{2,i}\)). (Ver Figura 6.1 panel a).
Figura 6.1: Funcionamiento del algoritmo \(kNN\)
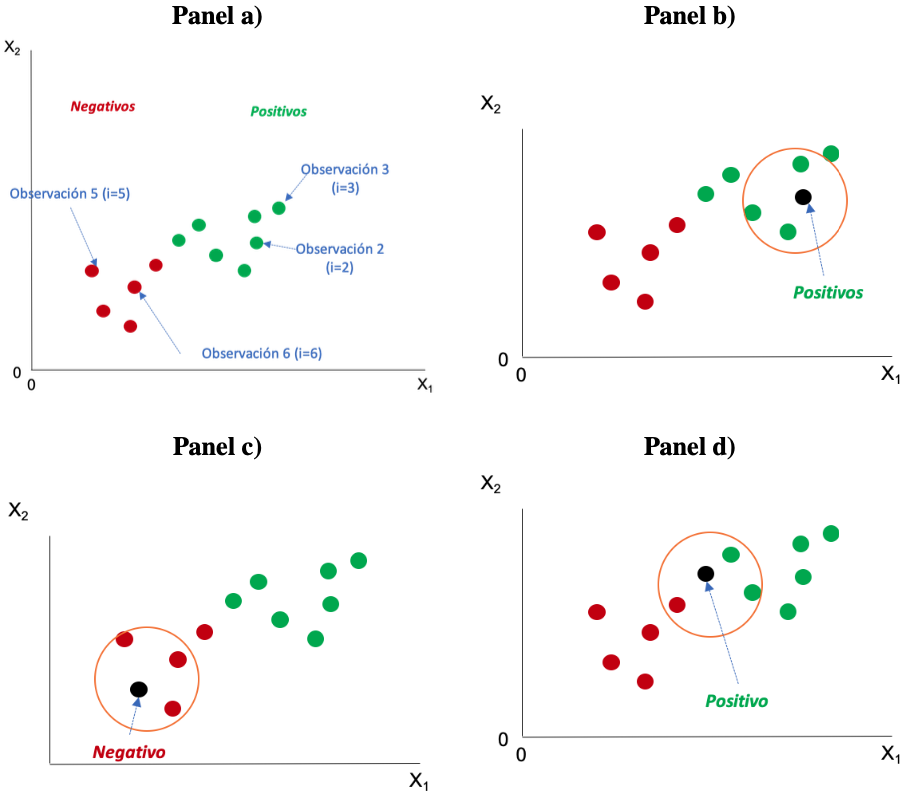
Ahora supongamos que definimos \(k=3\). Es decir, estaremos empleando 3 “vecinos” para votar. El algoritmo irá punto por punto (observación por observación) buscando sus vecinos y por “votación” aprenderá cuál debería ser la clase de la observación. Consideremos una observación \(i\) como la que se presenta con un punto negro en la Figura 6.1 panel b). El algoritmo “olvidará” por un momento que conoce la clase real de la observación \(i\), después buscará 3 vecinos (\(k=3\)) mas cercanos. En este caso, resaltados en el circulo naranja en la Figura 6.1 panel b). Ahora los tres vecinos “votarán”. Los tres “votos” de los vecinos concuerdan y esto hará que el algoritmo asigne a esta observación la clase de compra el producto (positivo). En el panel c) de la Figura 6.1 se presenta un caso similar, pero todos los votos implicarán que el algoritmo “aprende” que ese individuo es un “no comprador” (negativo). Finalmente, en el panel c) de la Figura 6.1 se presenta un caso en el que el algoritmo encuentra 2 “votos” por positivo y uno por negativo, por mayoría el algoritmo escoge rotular esta observación como un positivo. El algoritmo hace esto para todas las observaciones de la muestra de entrenamiento.
De esta aproximación intuitiva quedan claras las siguientes características del algoritmo \(kNN\):
Para ejecutar este algoritmo se tendrá que determinar una forma de medir la distancia entre los puntos para determinar cuáles observaciones están más cerca.
Para calcular las distancias, será necesario tener variables expresada numéricamente (y no como factores).
Es necesario tener un número de vecinos impar para evitar empates en la “votación”.
\(k\) no puede ser un múltiplo del número de clases.
Las unidades en que se midan las variables (\(X_{1,i}, X_{2,i},\cdots, X_{p,i}\)) pueden afectar la medida de distancia y, por eso, será necesario estandarizar los datos44.
Si la muestra es grande, este algoritmo puede tomar mucho tiempo encontrando los \(k\) vecinos próximos.
En las siguientes secciones de este capítulo veremos cómo escoger \(k\) y cómo realizar este algoritmo en R, pero antes se presenta una sección con el detalle técnico del algoritmo (esta sección puede ser omitida si el lector no se siente cómodo con la matemática detrás del algoritmo).
6.2 Detalle técnico
El modelo Logit (Ver Capítulo 3) es un modelo paramétrico que intenta encontrar la probabilidad que una observación \(i\) tome el valor de uno dada las características de las variables explicativas. \(kNN\) es un modelo no paramétrico para encontrar dichas probabilidades. \(kNN\) emplea \(k\) vecinos para calcular la probabilidad de la siguiente manera:
\[\begin{equation} \hat{p}_{k,j}(\mathbf{x}_i) = \hat{P}_k(Y = j \mid \mathbf{x}_i) = \frac{1}{k} \sum_{i \in \mathcal{N}_k(\mathbf{x}_i, \mathcal{D})} I(y_i = j) \tag{6.1} \end{equation}\]
En otras palabras, la probabilidad estimada por el algoritmo para cada clase \(j\) para la \(i\)-ésima observación es la proporción de \(k\) vecinos de \(i\) con dicha clase (\(j\)).
Entonces, para crear un clasificador, el algoritmo asigna a \(i\) la clase con la más alta probabilidad estimada. Es decir, \[\begin{equation} \hat{C}_k(\mathbf{x}_i) = \underset{j}{\mathrm{argmax}} \ \ \hat{p}_{kj}(\mathbf{x}_i) \tag{6.2} \end{equation}\]
Esto es lo mismo que decir que asignamos la clase a \(i\) con la mayor cantidad de observaciones (“votos”) en los \(k\) vecinos más cercanos. Si por casualidad se llegase a la situación en la que al menos dos clases tienen la mayor probabilidad, el algoritmo \(kNN\) asignará una clase al azar entre aquellas con la probabilidad más alta.
En el caso binario, que venimos estudiando, esto se convierte en: \[\begin{equation} \hat{C}_k(\mathbf{x}_i) =\begin{cases} 1& \hat{p}_{k,0}(\mathbf{x}_i) > 0.5 \\ 0& \hat{p}_{k,0}(\mathbf{x}_i) \leqslant 0.5 \end{cases} \tag{6.3} \end{equation}\] Como se mencionó anteriormente, si la probabilidad para la clase 0 y 1 es igual, se asignará al azar la clase. Una forma de evitar este empate, y, por tanto, la asignación de la clase de manera aleatoria, es emplear \(k\) impares y que no sean múltiplos del número de clases.
Figura 6.2: Ejemplo de asignación de clase con el algoritmo \(kNN\)
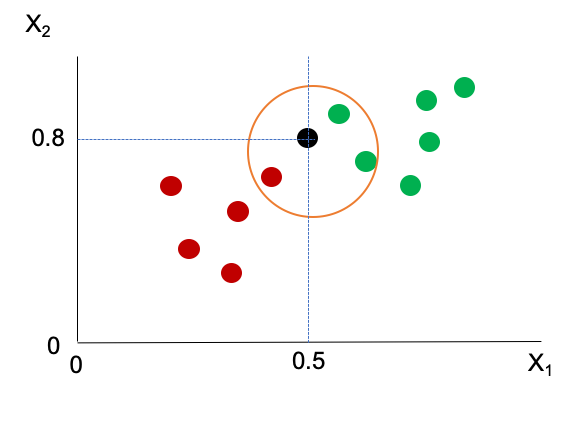
En la Figura 6.2 se presenta un ejemplo de este algoritmo con \(k=3\). En ese caso, para la observación \(i\) (con \(X_{1,i} = 0.5\) y \(X_{2,i} = 0.8\), es decir, \(\mathbf{x}_i = (0.5, 0.8)\)) las probabilidades serán:
\[\begin{equation*} \hat{p}_{3,\mathbf{x}_i}(x_{1,i} = 0.8, x_{2,i} = 0.5) = \hat{P}_3(y_i = 1 \mid x_{1,i} = 0.8, x_{2,i} = 0.5) = \frac{2}{3} \end{equation*}\] \[\begin{equation*} \hat{p}_{3,\mathbf{x}_i}(x_{1,i} = 0.8, x_{2,i} = 0.5) = \hat{P}_3(y_i = 0 \mid x_{1,i} = 0.8, x_{2,i} = 0.5) = \frac{1}{3} \end{equation*}\] y, por tanto, \[\begin{equation*} \hat{C}_3(x_{1,i} = 0.8, x_{2,i} = 0.5) = 1 \end{equation*}\]
Adicionalmente, es importante mencionar que es común seleccionar los vecinos más cercanos por medio de la distancia euclidiana. Es decir, \[\begin{equation} d(\mathbf{x}_i,\mathbf{x}_j)=\sqrt{\sum_{=r1}^p(X_{r,i}-X_{r,j})^2} \tag{6.4} \end{equation}\]
Finalmente, en la práctica está el problema de seleccionar \(k\). Un \(k\) pequeño, le permite al algoritmo identificar patrones muy sutiles, pero esos patrones pueden capturar mucho ruido en los datos (el componente aleatorio), mientras que un \(k\) grande reduce el ruido pero puede perder esa especificidad que da el vecindario pequeño.
Lo que es claro, es que el \(k\) óptimo depende de la muestra. Algunos autores como Lall & Sharma (1996) sugieren emplear \(k=\sqrt{n}\). Pero hoy en día lo más común es calcular el algoritmo para diferentes tamaños de \(k\) y comparar el comportamiento del algoritmo en la muestra de evaluación con diferentes métricas como las discutidas en el Capítulo 4. Por ejemplo, se puede seleccionar el \(K\) que maximice la accuracy (exactitud), la sensibilidad o la especificidad.
6.3 Implementación del algoritmo \(kNN\) en R
Para realizar un ejemplo práctico en R (R Core Team, 2023) emplearemos la misma base de datos que empleamos para el modelo Logit (Ver Capítulo 3) y para el modelo Naive Bayes (Ver Capítulo 5). Recuerden que se trataba de una base de datos provista por Moro et al. (2014)45. Recuerda que los datos están relacionados con varias campañas de marketing directo de una institución bancaria portuguesa. Las campañas de marketing se basaron en llamadas telefónicas. A menudo, se requería más de un contacto con el mismo cliente para determinar si el producto (bank term deposit) sería adquirido (“yes”) o no. La base de datos contiene información de 41.188 clientes para 20 variables explicativas y una variable dependiente.
La pregunta de negocio que queremos responder en este caso es: ¿se puede construir un modelo que pueda predecir si un cliente adquirirá o no el producto bancario?
Carga el working space que guardaste en el Capítulo 5. Para el detalle del pre-procesamiento de la muestra ver el Capítulo 3.
Recordemos que \(kNN\) implica el cálculo de distancias entre puntos de datos. Por eso debemos usar solo variables numéricas46. La variable de resultado (variable dependiente) debe seguir siendo una variable de clase factor.
Primero, estandaricemos47 las variables explicativas que deben ser de clase numérico (numeric) o entero (integer) para evitar que las escalas diferentes tengan un efecto en encontrar los vecinos.
En nuestro caso tendremos las siguientes variables para estandarizar:
age,campaign,previous,emp.var.rate,cons.price.idx,cons.conf.idx,euribor3m.
La estandarización se puede realizar rápidamente con la función scale() de la base de R. Para realizar una estandarización, el único argumento que requiere la función es el objeto a estandarizar. Para esto trabajaremos con el objeto datos en los que tenemos la base de datos antes de construir las variables dummies y dividir la muestra entre la muestra de entrenamiento y de evaluación. Empleemos el paquete dplyr48 (Wickham et al., 2021) para hacer esta transformación sobre las variables cuantitativas que se emplean como variables independientes.
library(dbplyr)
# Estandarizar las variables explicativas
datos_expl <- datos %>%
dplyr::select(age, campaign, previous, emp_var_rate, cons_price_idx,
cons_conf_idx, euribor3m) %>%
scale()
head(datos_expl, 3)## age campaign previous emp_var_rate cons_price_idx cons_conf_idx
## 1 1.5330157 -0.5659151 -0.34949 0.6480844 0.7227137 0.8864358
## 2 1.6289735 -0.5659151 -0.34949 0.6480844 0.7227137 0.8864358
## 3 -0.2901821 -0.5659151 -0.34949 0.6480844 0.7227137 0.8864358
## euribor3m
## 1 0.7124512
## 2 0.7124512
## 3 0.71245126.3.1 Construcción de muestra de entrenamiento y de evaluación
Al igual que lo hicimos en el caso de la estimación de los modelos en los capítulos anteriores, emplearemos el 80% de la muestra para el entrenamiento del algoritmo (la estimación) y el 20% restante para realizar la evaluación. Empleemos los mismos índices para las observaciones que se habían empleado en los capítulos anteriores. Es decir, empleemos los objetos est_index y eval_index que construimos en el Capítulo 3.
Procedamos a crear estas dos muestras.
6.3.2 Corriendo el algoritmo \(kNN\)
El algoritmo \(kNN\) puede implementarse en R con diferente paquetes como class (Venables & Ripley, 2002) o caret (Kuhn & Max, 2008). Una de las ventajas del segundo paquete es la selección automática del \(k\) óptimo. Así, procederemos a emplear el paquete caret.
La función train() del paquete caret permite implementar el algoritmo \(kNN\). Esta función típicamente incluye los siguientes argumentos:donde:
- x: La matriz de datos que se emplearán para predecir. Es decir, para encontrar los vecinos de \(i\).
- y: Un vector que contiene la variable de salida con clase factor.
- ncp: \(k\). Número de factores propios.
- method: El método para entrenar el algoritmo de inteligencia artificial. Esta función permite implementar varios algoritmos. Para nuestro caso method = “knn”.
- preProcess: Un vector de texto que especifique el pre-procesamiento que se desee en los datos. Por defecto no se pre-procesan los datos. Si deseamos que los datos sean estandarizados49, entonces preProcess = c(“center”,“scale”). Es importante recordar que la estandarización es para evitar que las escalas de las diferentes variables tengan un efecto en encontrar los vecinos.
- tuneGrid: Un objeto de clase data.frame que tiene todos los posibles valores de los parámetros que se desean evaluar en una búsqueda de grilla. En nuestro caso, el parámetro será \(k\), el número de vecinos. Este data.frame se puede crear con la función expand.grid() que establece sobre que valores se va a desarrollar la búsqueda de grilla. En el Capítulo 9 discutiremos en mayor detalle cómo se emplea este argumento para ajustar el modelo.
Noten que nosotros ya estandarizamos las variables cuantitativas por eso no es necesario estandarizar los datos de nuevo. Por otro lado, establezcamos una búsqueda de grilla entre 3 y 10 vecinos.
library(caret)
set.seed(1234)
kNN_res <- train(datos_expl_est, y_est, method = "knn", preProcess = NULL,
tuneGrid =expand.grid(k = seq(3,10, by = 1)))
kNN_res## k-Nearest Neighbors
##
## 32950 samples
## 7 predictor
## 2 classes: 'no', 'yes'
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 32950, 32950, 32950, 32950, 32950, 32950, ...
## Resampling results across tuning parameters:
##
## k Accuracy Kappa
## 3 0.8646359 0.2474794
## 4 0.8686730 0.2513281
## 5 0.8733926 0.2581226
## 6 0.8760372 0.2612837
## 7 0.8786569 0.2641821
## 8 0.8804401 0.2678078
## 9 0.8817470 0.2675983
## 10 0.8826351 0.2683974
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was k = 10.Podemos observar el proceso de selección del \(k\) óptimo realizado con la accuracy invocando el objeto kNN_res y graficando ese mismo objeto con la función plot(), los resultados se presentan en la Figura 6.3.
Figura 6.3: Accuracy del modelo kNN entrenado para diferentes número de vecinos
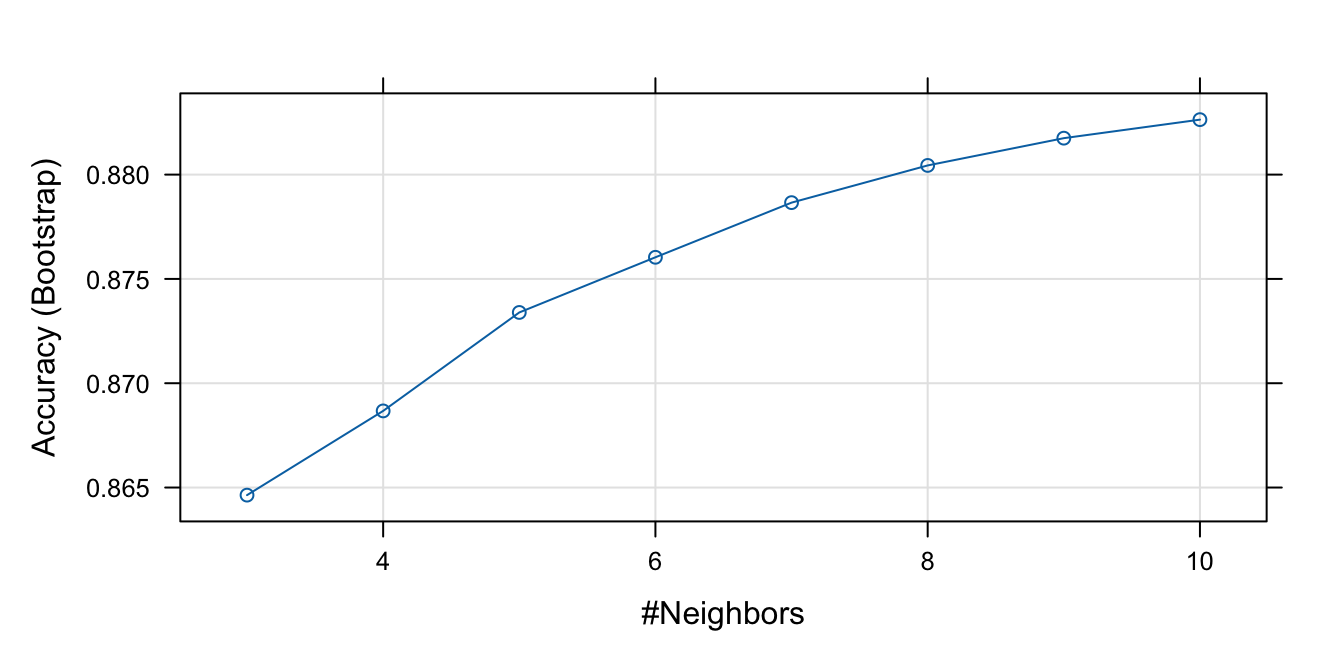
Empleando la precisión, se seleccionó \(k=10\). Ustedes pueden explorar los diferentes compartimientos que posee el objeto kNN_res con la función attributes(). Recuerde que los resultados en guardados en cada uno de los comportamientos se puede recuperar con el signo $ antecedido por el nombre del objeto y a continuación el nombre del compartimiento. Por ejemplo,
## $names
## [1] "method" "modelInfo" "modelType" "results" "pred"
## [6] "bestTune" "call" "dots" "metric" "control"
## [11] "finalModel" "preProcess" "trainingData" "ptype" "resample"
## [16] "resampledCM" "perfNames" "maximize" "yLimits" "times"
## [21] "levels"
##
## $class
## [1] "train"## 10-nearest neighbor model
## Training set outcome distribution:
##
## no yes
## 29185 3765Los resultados guardados en esos compartimientos pueden ser útiles en diferentes aplicaciones.
Noten que el número óptimo de vecinos (\(k\)) corresponde al límite superior de nuestra búsqueda de grilla. Esto nos lleva a preguntarnos ¿qué pasaría si aumentamos el límite superior de la búsqueda?, ¿seguirá siendo \(k=10\) el valor óptimo? En general siempre deberíamos eligir una grilla lo suficientemente amplia como para estar seguros que el valor óptimo no se encuentra por fuera de los valores evaluados. En este punto surge una pregunta: ¿cuál es el límite superior de \(k\)? En otras palabras, ¿hasta qué valor de \(k\) evaluar? Una regla empírica es emplear el máximo \(k\) en la búsqueda de grilla como: \[\begin{equation*} k = 2 \cdot min\left\{ N,P\right\} + 1 \end{equation*}\]
Siguiendo a Dasarathy (1991), una explicación intuitiva de esta regla empírica es la siguiente: considere el caso extremo en el que tenemos un conjunto de datos que contiene \(P\) valores positivos (\(y=1\)) y solo un valor negativo. En ese caso, si \(k\) es mayor a tres, siempre clasificaremos cada individuo como positivo, por lo que la precisión de la validación cruzada será la misma para todos los \(k \leq 3\). En ese caso, emplear como número máximo en la búsqueda \(k = 3\) sería muy pequeño. Ahora consideremos el otro caso extremo. Supongamos ahora que tenemos 100 observaciones y el mismo número de individuos positivos y negativos \(P = N = 50\). En este caso, si fijamos \(k= 2 N -1\), entonces clasificar un patrón como positivo o negativo dependerá de la distribución de los datos. Podríamos tener \(P = 50\) y \(N = 49\) más cercanos a la observación bajo evaluación o \(P = 49\) y \(N = 50\). Si \(k\) es mayor que 50, siempre habrá un empate, ya que sólo tenemos 50 positivos y 50 patrones negativos en la muestra de entrenamiento.
Así, para estar seguros de que hemos analizado todos los valores no redundantes de \(k\) es posible que tengamos que buscar hasta el número total de muestras de entrenamiento. Por ejemplo, si tenemos \(N < P\), entonces tendríamos que buscar hasta \(k = 2N + 1\) (ya que un kNN con \(k\) mayor a \(2N + 1\) implicará más observaciones votadas como positivas que negativas). Y algo similar ocurrirá cuando \(N > P\).
En nuestro caso \(P =\) 3765 y \(N =\) 29185, así el \(k\) máximo para nuestra búsqueda de grilla sería \(2 \cdot min\left\{ N,P\right\} + 1\) = 7531. Esto tomará mucho tiempo de computo y memoria. Tu puedes comprobar que no es necesaria una búsqueda tan grande. Para agilizar el proceso de cómputo solo evaluaremos hasta un valor de \(k\) de 150. Así tendremos:
# Establecer la grilla de búsqueda para el costo
kNN_res <- train(datos_expl_est, y_est, method = "knn", preProcess = NULL,
tuneGrid =expand.grid(k = seq(9,150, by = 1)))
kNN_res$finalModel## 111-nearest neighbor model
## Training set outcome distribution:
##
## no yes
## 29185 3765Empleando la precisión, se seleccionó \(k =\) 111. Noten que en ese caso el óptimo no fue cerca al límite superior de la grilla de búsqueda.
6.3.3 Bondad de ajuste del modelo
Ahora generemos la matriz de confusión y las correspondientes métricas. Primero debemos generar las predicciones fuera de muestra para la clase. Esto se puede hacer de manera similar a lo que hicimos en el caso del modeloLogit y para el modelo Naive Bayes.
Y ahora veamos la correspondiente matriz de confusión:
## Reference
## Prediction no yes
## no 7244 729
## yes 119 146| Accuracy | Sensitivity | Specificity | Precision | F1 | |
|---|---|---|---|---|---|
| Modelo Logit | 0.846 | 0.618 | 0.873 | 0.366 | 0.460 |
| Naive Bayes | 0.854 | 0.472 | 0.899 | 0.357 | 0.407 |
| kNN | 0.897 | 0.167 | 0.984 | 0.551 | 0.256 |
| Fuente: elaboración propia. |
Las otras métricas estudiadas del mejor modelo Logit, el Naive Bayes y \(kNN\) se reportan en el Cuadro 6.1.
Noten que el modelo \(kNN\) tiene el mejor accuracy (89.7%), sin embargo, clasificando el valor positivo “yes”, no es muy bueno. Además este modelo si bien tiene una proporción alta de falsos positivos, esta no es tan alta como los otros dos modelos. El modelo \(kNN\) clasifica a 11950 observaciones en la clase “yes”, que realmente no fueron “yes”. Para el caso del modelo Naive Bayes el porcentaje de falsos positivos era de 64.3% y para el modelo Logit esta tasa de falsos positivos era de 63.4 %.
Finalmente, guarda el espacio de trabajo para ser empleado en los siguientes capítulos.
6.4 Comentarios Finales
En este capítulo hemos discutido el método de aprendizaje supervisado comúnmente empleado en las tareas de clasificación. En los próximos capítulos estudiaremos otros métodos de aprendizaje de máquinas que también sirven para clasificar. Como se mencionó anteriormente, a priori, es imposible saber si este método será mejor que el estadístico u otros de aprendizaje de máquina y por eso es común que se empleen diferentes aproximaciones y se comparen.
Las aplicaciones de estos métodos de clasificación son muchas en el mundo de los negocios y definitivamente estos modelos son necesarios en la caja de herramientas de un científico de datos.
Referencias
También conocido como aprendizaje automático o aprendizaje automatizado. Este término viene del inglés machine learning.↩︎
El modelo Naive Bayes también es un modelo no paramétrico.↩︎
Los dos métodos de escalar datos más empleados son la normalización y la estandarización. La normalización generalmente significa re-escalar los valores en un rango entre \([0,1]\). La estandarización generalmente significa que los datos re-escalados tienen una media de 0 y una desviación estándar de 1.↩︎
La base de datos está disponible en la página web del libro: http://www.icesi.edu.co/editorial/intro-clasificacion/.↩︎
Naturalmente, esto solo aplica para las variables predictoras no para la variable objetivo↩︎
Es decir, se le quita la respectiva media para centrar los datos y se divide por la desviación estándar para garantizar que la varianza sea uno.↩︎
Es decir, se le quita la respectiva media para centrar los datos y se divide por la desviación estándar para garantizar que la varianza sea uno.↩︎
Esto representa el 44.9% de todos los positivos predichos por el modelo Naive Bayes.↩︎