7 Árboles de decisión (Decision Tree Algorithm)
Objetivos del capítulo
Al finalizar la lectura de este documento el estudiante estará en capacidad de:
- Explicar en sus propias palabras la utilidad de un algoritmo de árbol de decisión (Decision Tree Algorithm).
- Emplear un algoritmo de clasificación de árbol en R.
- Calcular métricas de la bondad de un modelo de clasificación estimado por medio de un algoritmo de clasificación de árbol.
- Encontrar los pronósticos de clasificación de un algoritmo de clasificación de árbol.
7.1 Introducción
Anteriormente, discutimos que los modelos de clasificación que se emplean en el business analytics tienen dos orígenes: modelos estadísticos y modelos de aprendizaje de máquinas51. En los anteriores capítulos discutimos el modelo estadístico Logit (el más empleado para clasificación) y el modelo Naive Bayes. Posteriormente, estudiamos una técnica de aprendizaje de máquina conocida como \(kNN\). En esta oportunidad nos concentraremos en otra técnica de inteligencia artificial conocida como árboles de decisión (Decision Trees).
Los árboles de decisión son un método de aprendizaje supervisado no paramétrico que puede ser empleado para hacer tareas de clasificación y de regresión. Esta característica hace único a este algoritmo, pues es de los pocos que permiten hacer cualquiera de estas dos tareas. En general, los árboles de decisión aprenden de los datos para crear un conjunto de reglas de decisión del tipo si-entonces-otro (if-then-else); reglas que están anidadas. Este algoritmo no calcula parámetros (como el modelo Logit) y por eso se clasifica como un método no paramétrico.
Si la variable de salida es una variable categórica (Árboles de decisión con variable categórica Categorical Variable Decision Tree), entonces la tarea que resuelven los árboles de decisión son de clasificación. Si la variable de salida es una variable continua, entonces los árboles de decisión resuelven tareas de regresión.
En cualquiera de los dos casos, la idea detrás del algoritmo es relativamente sencilla. La filosofía de los árboles de decisión se basa en la máxima “divide y vencerás”. Es decir, la idea es dividir la muestra cada vez en dos grupos, tal que las observaciones al interior de los grupos se parezcan lo más posible. En esta literatura a esto se le conoce como ser lo más “puro posible”. Es decir, cuando los subgrupos tienen clasificados individuos que solo pertenecen a una clase, los llamaremos puros; en caso contrario los llamaremos impuros. Veamos un ejemplo para entender este concepto.
Por ejemplo, supongamos que contamos con dos clases: compra el producto (positivo) y no lo compra (negativo) y tenemos dos variables: nivel de ingresos (\(X_{1,i}\)) y los años de educación (\(X_{2,i}\)). (Ver Figura 7.1 panel a)).
Figura 7.1: Funcionamiento del algoritmo de clasificación de árbol para variables categóricas
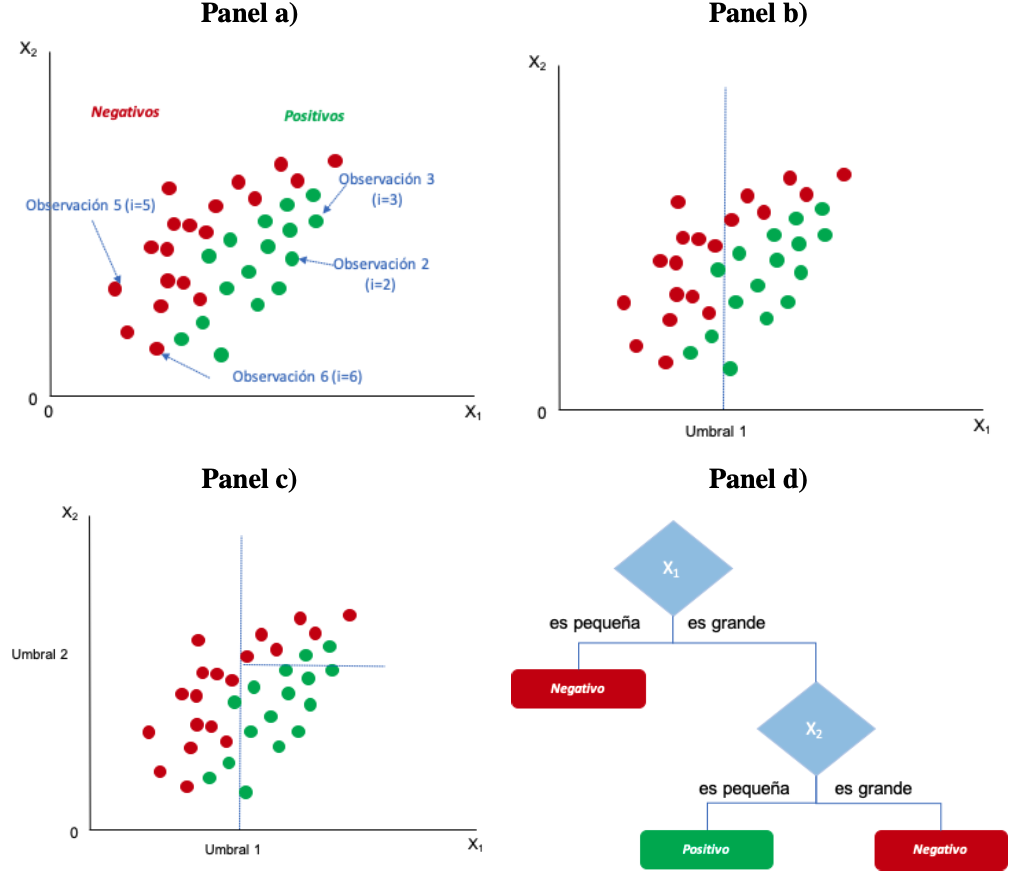
Ahora, el algoritmo ``escoge” una variable para dividir la muestra. Supongamos que empezamos empleando el ingreso (\(X_{1}\)) como la variable que mejor divide en el primer paso la muestra en los que compran el producto (positivo) y los que no lo compran (negativo). El algoritmo establece un umbral (Umbral 1) que permite dividir el espacio de la variable ingresos (\(X_{1}\)) en dos regiones los ingresos bajos y los altos (Ver Figura 7.1 panel b)).
El segundo paso es dividir las dos áreas empleando las siguientes variables en este caso los años de educación (\(X_{2}\)). En este caso en especial es claro para el algoritmo, que para valores pequeños de \(X_{1}\) no es necesario dividir de nuevo la muestra, pues prácticamente casi todos los valores son negativos. Pero para valores grandes de \(X_{1}\) el algoritmo puede encontrar un segundo umbral (Umbral 2), pero esta vez para la variable años de educación (\(X_{2}\)). Nuevamente, la muestra queda dividida en dos grupos: valores bajos de \(X_{2}\) (por encima del Umbral 2) y valores altos (por debajo del Umbral 2) (ver Figura 7.1 panel b)). Noten que el algoritmo encontró dos reglas del tipo si-entonces-otro (if-then-else). La primera regla es si el ingreso (\(X_{1,i}\)) es menor que el umbral 1, entonces \(i\) será un negativo (no compra el producto). En caso contrario tenemos una segunda regla para determinar la clasificación de \(i\). La segunda regla implica determinar si los años de educación del individuo \(i\) (\(X_{2,i}\)) es menor que el umbral 2, entonces \(i\) se clasificará como un positivo (se comprará el producto). En caso de que \(X_{2,i}\) sea mayor que el umbral 2, \(i\) se etiquetará como un negativo (no compra el producto).
Estas reglas que acaba de encontrar el algoritmo se pueden representar en forma de un árbol de decisión como el que se presenta en el panel d) de la Figura 7.1. Los puntos de decisión (representados por rombos en este caso) se conocen como nodos de decisión. Los nodos de decisión implican tener un umbral (una regla de decisión) que divide a la muestra (el proceso de dividir la muestra se denomina en inglés split). El primer nodo (el que se encuentra más arriba) se denomina nodo raíz (ver Figura 7.2). Los nodos terminales u hojas corresponden a los nodos que no dividen más a la muestra. Estos nodos tienen flechas que entran en ellos, pero ninguna flecha sale de ellos.
Antes de continuar, es importante reconocer que los tres nodos terminales u hojas que se formaron con la muestra, dos son impuros; mientras que uno es puro. Es decir, al aplicar la primera regla obtenemos un nodo terminal en el que “caen” 16 de los individuos que serán etiquetados como negativos; los que tienen ingresos por debajo del umbral 1. En este nodo terminal, 3 son positivos, los otros 13 fueron reales negativos. Por eso se considera como una hoja impura o, dicho de otra forma, no todos los individuos pertenecen a una clase. Por otro lado, al aplicar la segunda regla a los individuos (\(i\)) con ingresos mayores al umbral 1, encontramos un nodo terminal de 11 individuos con educación menor al umbral 2. Este nodo terminal implica que los individuos son clasificados como positivos. Los 11 individuos de esta hoja son clasificados correctamente como positivos. Es decir, el nodo terminal es totalmente puro. La tercera hoja tiene 2 individuos de los 8 que son clasificados erróneamente como negativos. Por eso es un nodo terminal impuro.
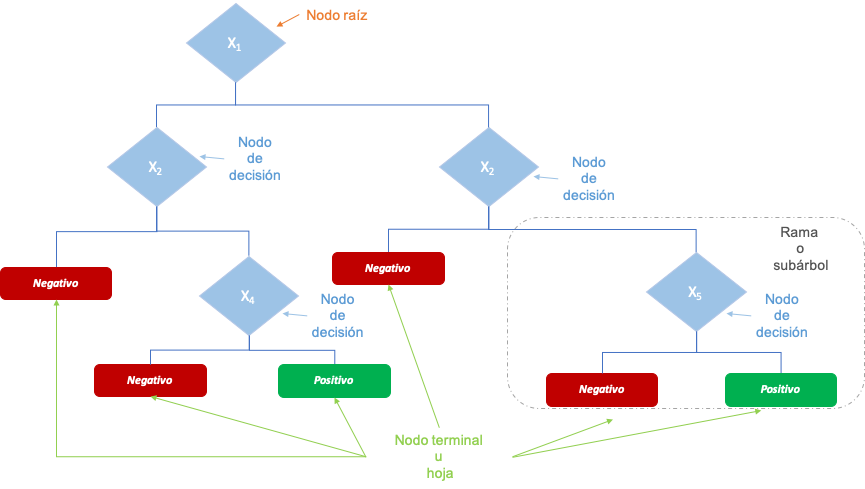
En la Figura 7.2 se presenta un árbol de decisión un poco más complicado. Una Rama (Branch) o Subárbol es una subsección del árbol. El proceso de eliminar ramas se denomina poda (pruning). Crear más ramas se conoce como splitting. Finalmente, un nodo de decisión que se divide en subnodos, se denomina nodo padre, mientras que los subnodos se conocen como nodos hijos.
Figura 7.2: Terminología de los árboles de clasificación
7.2 Podando árboles
Es importante anotar que uno de los problemas de este tipo de algoritmo es que los árboles de decisión tienden a convertirse en bastante complejos rápidamente (grandes). Lo cuál esta asociado con el overfitting. Es decir, que el modelo quede demasiado entrenado para la muestra de tal manera que no sea posible actuar bien en otra muestra (nuevos datos que quisiéramos clasificar en el futuro). Para evitar este crecimiento se usan técnicas de “poda” (pruning).
Un método es el que se conoce como pre-poda (pre-pruning). Esto implica parar el “crecimiento del árbol cuando este alcanza un determinado tamaño. Por ejemplo, se le puede pedir al algoritmo que pare cuando ha llegado un determinado nivel de profundidad (Ver Figura 7.3 panel a). Otra técnica de pre-poda (Ver Figura 7.3 panel b) implica parar el crecimiento de una rama cuando se alcance un mínimo de observaciones.
Figura 7.3: Técnicas de poda
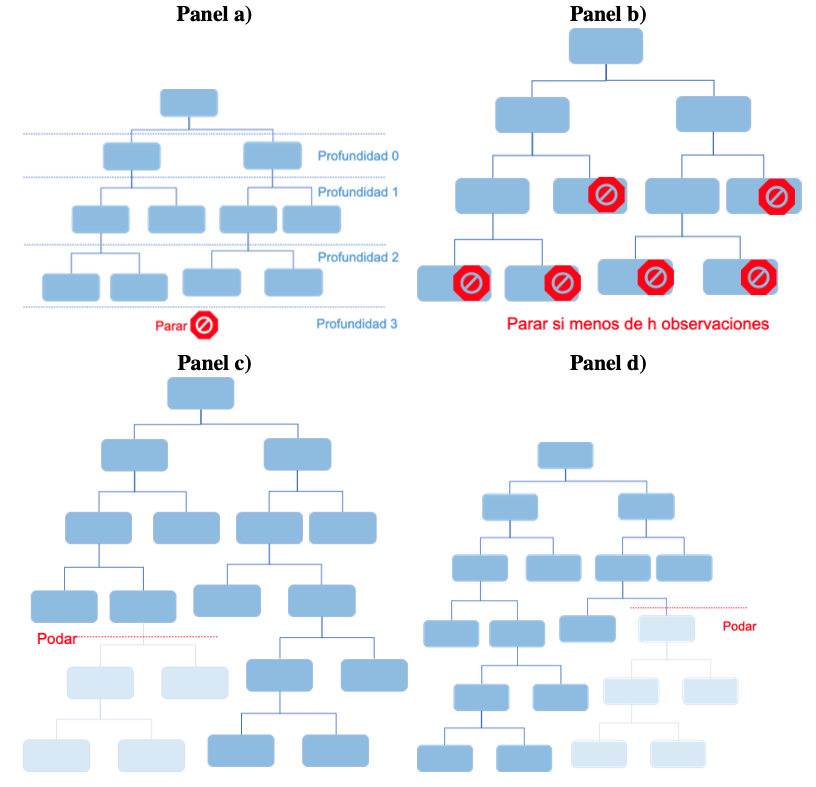
Parar el “crecimiento” de un árbol en un momento temprano, puede evitar que este encuentre patrones importantes. Para tratar de evitar esto pueden emplearse técnicas de post-poda. Por ejemplo (Ver Figura 7.3 paneles c) y d) ), se puede dejar crecer un árbol tan grande como se pueda y después podar algunas ramas usando la contribución a minimizar errores de cada rama.
Miremos esto de una manera intuitiva; un árbol se puede entender como un gran cuestionario que se le aplica a los datos, cada rama representa preguntas. Ese cuestionario grande nos lleva a una respuesta final: la clasificación de cada individuo (hoja o nodo terminal). Cada pregunta divide el grupo de datos en ramas más pequeñas, acercándonos a la clase a la que pertenece cada individuo.
La complejidad de un árbol de clasificación tiene que ver con su tamaño y profundidad (número de ramas). Un árbol con pocos niveles y ramas es simple, mientras que uno con muchos niveles y ramas intrincadas es más complejo.
Un árbol muy simple podría no capturar todas las relaciones importantes en los datos, lo que conduce a errores en las clasificaciones, lo que llevaría a falta de precisión en la clasificación; pero un árbol con muchos niveles nos puede llevar al overfitting52. Adicionalmente, un árbol complejo puede ser difícil de entender y seguir, haciendo que sea poco práctico. Y en algunos casos, los árboles complejos requieren más memoria RAM para almacenar y más tiempo para procesar, lo cual puede ser inconveniente si se cuenta con una base de datos muy grande. Por eso es importante “podar” un árbol. Es decir, eliminar ramas que no aportan mucho a la clasificación, buscando un equilibrio entre precisión y complejidad.
Como vimos, podar es cortar ramas innecesarias para mantener el árbol lo más pequeño y preciso posible. Como se discutió arriba, las técnicas de poda son variadas. Por ejemplo, se puede definir un límite de profundidad o número de ramas máximo para el árbol; a esta técnica se le llama pre-poda. Es decir, se para el crecimiento antes que necesitemos podar el árbol. Para la pre-poda se pueden emplear diferentes criterios, como el número de niveles o el número de observaciones por rama. Por otro lado, está la posibilidad de que el árbol crezca y se corten ramas innecesarias: post-poda.
En últimas, queremos aplicarle un “cuestionario” a los individuos que nos permita realizar la clasificación sin que éste sea muy complejo.
En la post-poda se emplea a menudo un parámetro denominado el parámetro de complejidad (\(cp\)). El \(cp\) es la mejora mínima del modelo necesaria en cada nodo para permitir que ese nodo no sea cortado. El \(cp\) intenta resumir en un número el costo de la complejidad del árbol53 sumando la tasa de casos mal clasificados (en los nodos terminales) (\(R(T)\)) y el número de divisiones (splits) (\(T\)) multiplicado por un término de penalización \(\alpha\) (\(\alpha >0\)). Es decir,
\[\begin{equation*} cp(T, \alpha) = R(T) + \alpha T \end{equation*}\]
Así, el parámetro de complejidad es función del número de splits (\(T\)) del árbol y del término de penalización que se convierte en un parámetro. En la práctica, se puede emplear el \(cp\) para acelerar la búsqueda de divisiones porque puede identificar divisiones que no cumplen este criterio y eliminarlas antes de ir demasiado lejos.
7.3 Selección de umbrales
Antes de pasar a estudiar cómo hacer esto en R, la pregunta que queda es ¿cómo hace el algoritmo para seleccionar los umbrales? Como se mencionó anteriormente, la idea del método de árboles de decisión es dividir la muestra de tal manera que se creen grupos homogéneos. Es decir, que se creen nodos terminales puros.
Esto implica, que el proceso de separación del algoritmo necesitará emplear algún tipo de medida de no pureza (heterogeneidad). Existen diferentes medidas de impuridad como por ejemplo el Coeficiente de Gini, Coeficiente de Entropía, la Ganancia de información, la Razón de ganancia, la Reducción de varianza y Chi-cuadrado. Concentrémonos en los dos primeros.
El coeficiente de Gini54 en este contexto para un problema de clasificación binario para cada uno de los dos posibles nodo hijo (\(j\)) se define como:
\[\begin{equation} Gini_j=1-{(p_j)^2}-{(q_j)^2} \tag{7.1} \end{equation}\] donde \(p_j\) es la proporción de positivos en el nodo hijo \(j\) y \(q_j\) es la proporción negativos en el mismo nodo. Entonces, para un nodo padre al encontrar un umbral, se calculan el coeficiente de Gini para los dos nodos hijos y se crea un promedio ponderado por los casos (individuos) que son clasificados en cada uno de los nodos hijos como proporción de los casos que llegan al nodo padre. Es importante recalcar que entre más pequeño sea el coeficiente de Gini para el nodo \(j\) , mejor la tarea de separar los individuos (mayor será la homogeneidad y por tanto su pureza).
El algoritmo de clasificación con un árbol de decisión empleando como medida de impureza el coeficiente de Gini implicará los siguientes pasos:
- Encontrar el umbral para cada variable continua que minimice el coeficiente de Gini ponderado (la suma ponderada de los dos coeficientes de Gini de los nodos hijos). Es decir, encontrar el valor de la variable continua que genere el mejor “split” de la muestra. Esto implica evaluar todos los posibles umbrales (punto medios entre todas las observaciones) para cada variable.
- Calcular los coeficientes de Gini para los nodos de las variables dicotómicas. En caso de existir variables categóricas con mas de una clase, se agrupan las clases de tal manera que se minimice el coeficiente de Gini para esa variable.
- Seleccionar la variable con el coeficiente de Gini más bajo como la variable que corresponderá al nodo raíz, y generar los dos nuevos nodos.
- Repetir 1 a 2 para cada nuevo nodo.
- Seleccionar la variable con el coeficiente de Gini ponderado mejor como el nuevo nodo de decisión.
- Repetir 4 y 5 hasta que se encuentre un nodo para el cual no existe más variables que presten un coeficiente de Gini que sea menor al coeficiente de Gini del nodo padre o hasta que no existan más variables a evaluar. En este caso se encontró un nodo terminal.
A este algoritmo se le conoce como CART (por su sigla en inglés Classification and Regression Tree55.) .
Otra medida de desigualdad muy empleada es el Coeficiente de Entropía también conocido como índice de información (information index). Este coeficiente es una medida de la aleatoriedad en la información que se procesa. Cuanto mayor es la entropía, más difícil es sacar conclusiones de esa información. En este contexto, para un problema de clasificación binario para cada uno de los dos posibles nodos hijos (\(j\)) se define como:
\[\begin{equation} E_j=1-p_jlog(p_j)-q_jlog(q_j) \tag{7.2} \end{equation}\] Al igual que en el caso del coeficiente de Gini, para cada posible nodo de decisión se calcula el promedio ponderado de cada uno de los dos nodos hijos.
En este caso, el algoritmo que emplea el criterio de entropía para armar el árbol de decisión se conoce como ID3. Este algoritmo sigue una regla sencilla: un nodo con una entropía de cero será un nodo terminal (hoja) y un nodo con una entropía mayor que cero necesita una división adicional.
A priori, es imposible determinar qué algoritmo (con el índice de Gini o el de entropía u otro) para construir árboles de decisión es mejor, por eso una buena práctica es emplear varios criterios y evaluar su comportamiento. Tampoco es posible saber a priori si el árbol de decisión hace mejor tarea o no que un modelo Logit, Naive Bayes o que el algoritmo \(kNN\). Por eso es común calcular todas estas opciones y compararlos con las métricas que ya conocemos.
En las siguientes secciones veremos cómo correr este algoritmo en R y comparar los resultados con otros métodos de clasificación.
7.4 Implementación del algoritmo en R
Para realizar un ejemplo práctico en R (R Core Team, 2023) emplearemos la misma base de datos que empleamos para el modelo Logit (Capítulo 3), el modelo Naive Bayes (Capítulo 5) y el algoritmo \(kNN\) (Capítulo 6).
Recuerda que la pregunta de negocio que queremos responder en este caso es: ¿se puede construir un modelo que pueda predecir si un cliente adquirirá o no el producto bancario?
Carga el working space que guardaste en el Capítulo 6. Para el detalle del pre-procesamiento de la muestra ver el Capítulo 3.
7.4.1 Corriendo el algoritmo con el criterio de Gini
El algoritmo de construcción de árboles de clasificación, tanto empleando el coeficiente de Gini como el de entropía, se puede implementar en R con diferentes paquetes. En esta ocasión emplearemos el paquete rpart (Therneau & Atkinson, 2022).
La función rpart() del paquete rpart permite implementar este algoritmo y muchos otros de partición. En nuestro caso solo necesitamos los siguientes argumentos de esta función:
donde:
- formula: Una fórmula que determina la variable dependiente (de salida) y las variables de entrada (las que irán en los nodos).
- data: Un objeto de clase data.frame que contiene los datos.
- method: para nuestro caso tenemos un método de clasificación, por eso usaremos method = “class”.
- parms: argumento que permite definir el criterio para generar los splits. Si parms = list(split = “information”) se emplea el coeficiente de entropía (o índice de información). Si parms = list(split = “gini”) se emplea el coeficiente de Gini. Este último es el criterio por defecto.
- control: Este argumento permite controlar el crecimiento del árbol.
Empecemos creando un árbol con el criterio de Gini para separar las muestras:
set.seed(123)
library(rpart)
RT_res_gini <- rpart(formula = y ~. ,
data= datos_dummies_est, method = "class",
parms = list(split = "gini"), control = rpart.control(cp = 0))Podemos observar el árbol de decisión empleando la función rpart.plot() del paquete rpart.plot (Milborrow, 2022).
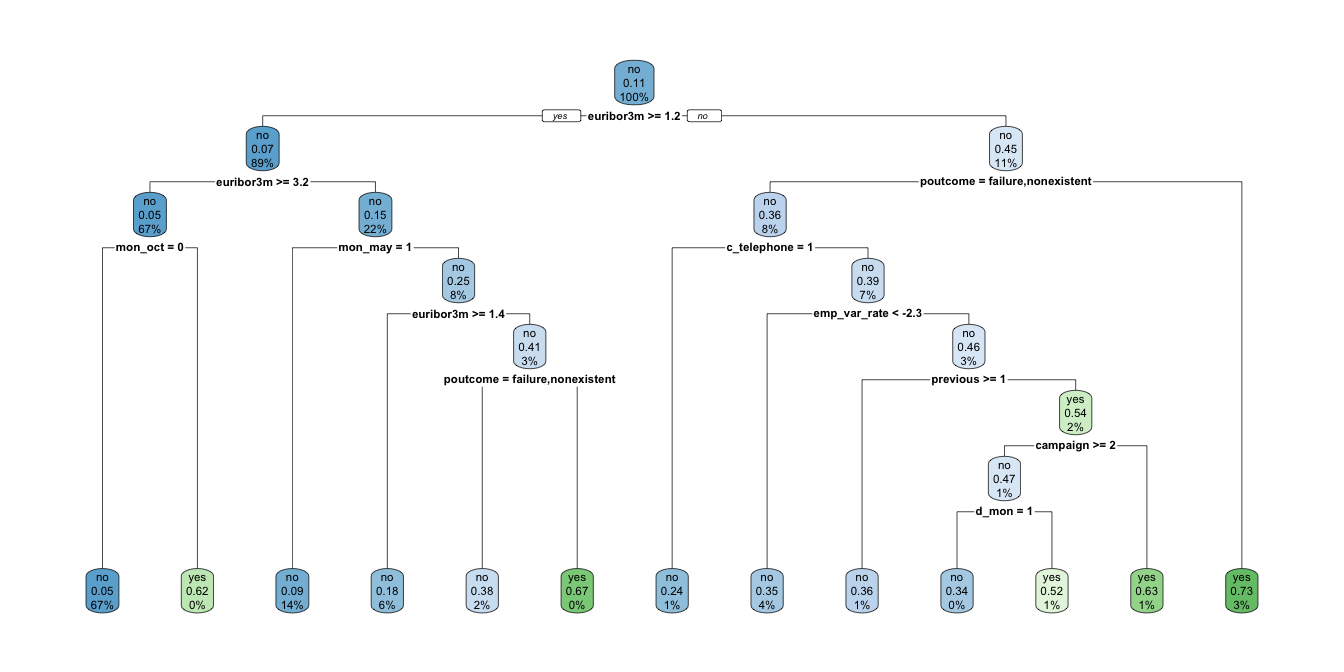
Este árbol es bastante complejo (Ver Figura 7.4). Necesitamos hacer una poda.
Figura 7.4: Árbol sin podas

7.4.1.1 Poda
Empleemos las técnicas de pre-poda discutidas anteriormente. Por ejemplo, limitemos el crecimiento del árbol hasta 4 niveles (Ver Figura 7.6):
RT_res_gini_4niveles <- rpart(y ~ .,
data= datos_dummies_est,
method = "class", parms = list(split = "gini"),
control = rpart.control(cp = 0, maxdepth = 4))Figura 7.5: Árbol podado hasta 4 niveles
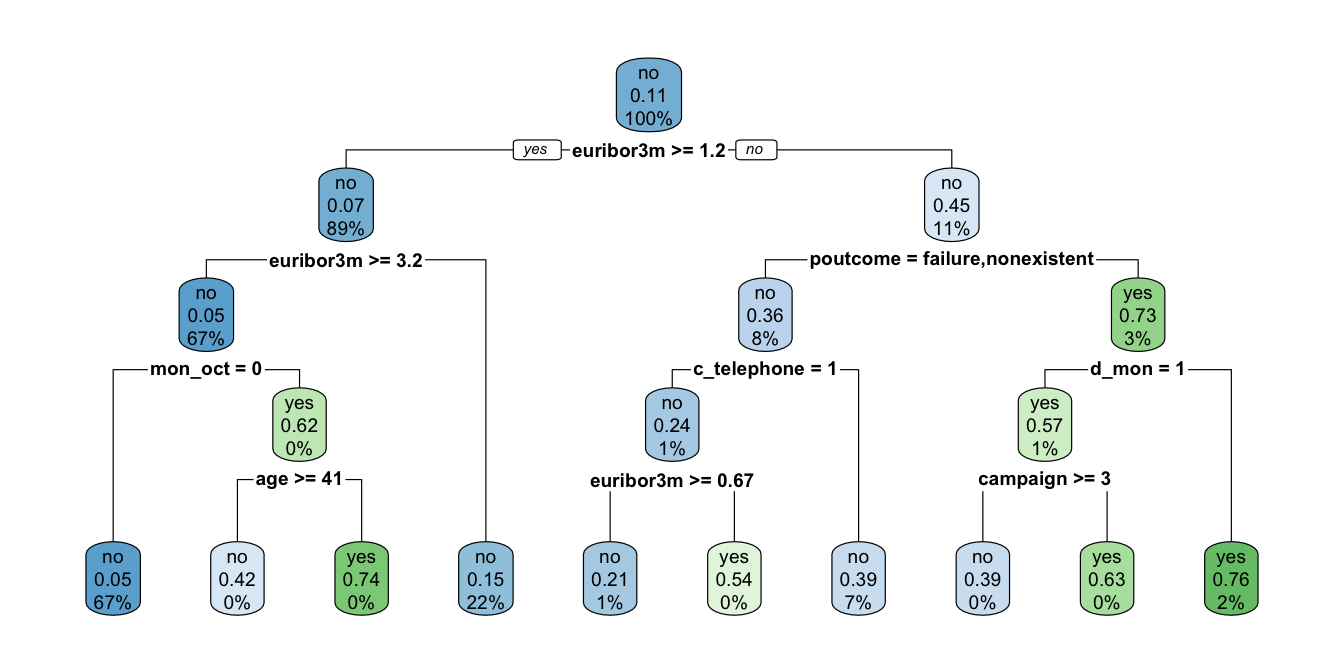
El árbol con 4 niveles se puede observar en la Figura 7.5. Ahora intentemos para el crecimiento cuando los nodos no tengan mas de 500 observaciones.
RT_res_gini_500obs <- rpart(y ~ . , data= datos_dummies_est, method = "class",
parms = list(split = "gini"),
control = rpart.control(cp = 0, minsplit = 500))Figura 7.6: Árbol con ramas con 500 observaciones o más
Ahora consideremos la posibilidad de una post-poda partiendo del árbol de decisión que construimos inicialmente (el objeto RT_res_gini). Como se explicó anteriormente, para establecer dónde realizar la post-poda se puede emplear el parámetro de complejidad (\(cp\)) del árbol. Estamos buscando el \(cp\) que minimice el error del modelo (columna xerror en la próxima salida de R). El \(cp\) para los diferentes splits y sus respectivos errores se pueden extraer del objeto de clase rpart empleando la función printcp().
##
## Classification tree:
## rpart(formula = y ~ ., data = datos_dummies_est, method = "class",
## parms = list(split = "gini"), control = rpart.control(cp = 0))
##
## Variables actually used in tree construction:
## [1] age c_telephone campaign
## [4] cons_conf_idx cons_price_idx d_mon
## [7] d_thu d_tue d_wed
## [10] def_unknown e_basic_6y e_high_school
## [13] e_professional_course e_university_degree e_unknown
## [16] emp_var_rate euribor3m h_yes
## [19] j_blue_collar j_housemaid j_management
## [22] j_retired j_self_employed j_student
## [25] j_technician l_yes m_married
## [28] m_single mon_jul mon_jun
## [31] mon_may mon_oct poutcome
## [34] previous
##
## Root node error: 3765/32950 = 0.11426
##
## n= 32950
##
## CP nsplit rel error xerror xstd
## 1 5.1129e-02 0 1.00000 1.00000 0.015338
## 2 3.1873e-03 2 0.89774 0.89774 0.014628
## 3 2.3904e-03 6 0.88313 0.89270 0.014592
## 4 2.1780e-03 7 0.88074 0.88818 0.014559
## 5 1.3280e-03 12 0.86985 0.88499 0.014536
## 6 1.1952e-03 18 0.86189 0.88712 0.014551
## 7 1.1510e-03 20 0.85950 0.89296 0.014594
## 8 1.0624e-03 23 0.85604 0.89270 0.014592
## 9 9.2961e-04 37 0.84117 0.89456 0.014605
## 10 8.8535e-04 45 0.83267 0.89323 0.014596
## 11 7.9681e-04 48 0.83001 0.89588 0.014615
## 12 7.3779e-04 63 0.81753 0.90120 0.014653
## 13 6.6401e-04 72 0.81089 0.90305 0.014666
## 14 6.1974e-04 77 0.80744 0.90518 0.014682
## 15 5.7548e-04 80 0.80558 0.90518 0.014682
## 16 5.3121e-04 88 0.80027 0.90571 0.014686
## 17 4.7809e-04 102 0.79283 0.91049 0.014720
## 18 4.6481e-04 108 0.78991 0.91235 0.014733
## 19 4.4267e-04 112 0.78805 0.91262 0.014735
## 20 3.9841e-04 127 0.78088 0.91501 0.014752
## 21 3.5414e-04 148 0.77185 0.91952 0.014784
## 22 3.3201e-04 151 0.77078 0.92058 0.014792
## 23 3.2463e-04 155 0.76946 0.92191 0.014801
## 24 2.6560e-04 167 0.76388 0.94130 0.014937
## 25 1.9920e-04 230 0.74422 0.94210 0.014943
## 26 1.3280e-04 238 0.74263 0.94475 0.014961
## 27 1.2499e-04 258 0.73997 0.94927 0.014993
## 28 1.1383e-04 276 0.73758 0.94954 0.014995
## 29 8.8535e-05 283 0.73679 0.95139 0.015007
## 30 6.6401e-05 292 0.73599 0.95325 0.015020
## 31 5.3121e-05 296 0.73572 0.95644 0.015042
## 32 0.0000e+00 301 0.73546 0.96600 0.015108En este caso el error mínimo (xerror) se encuentra para 12 splits y corresponde a un \(cp\) de 0.001328. Esto se puede ver gráficamente empleando la función plotcp(), como se presenta en la Figura 7.7.
Figura 7.7: Parámetro de complejidad (cp) y error relativo (xerror) para el modelo del árbol construido con el criterio de Gini
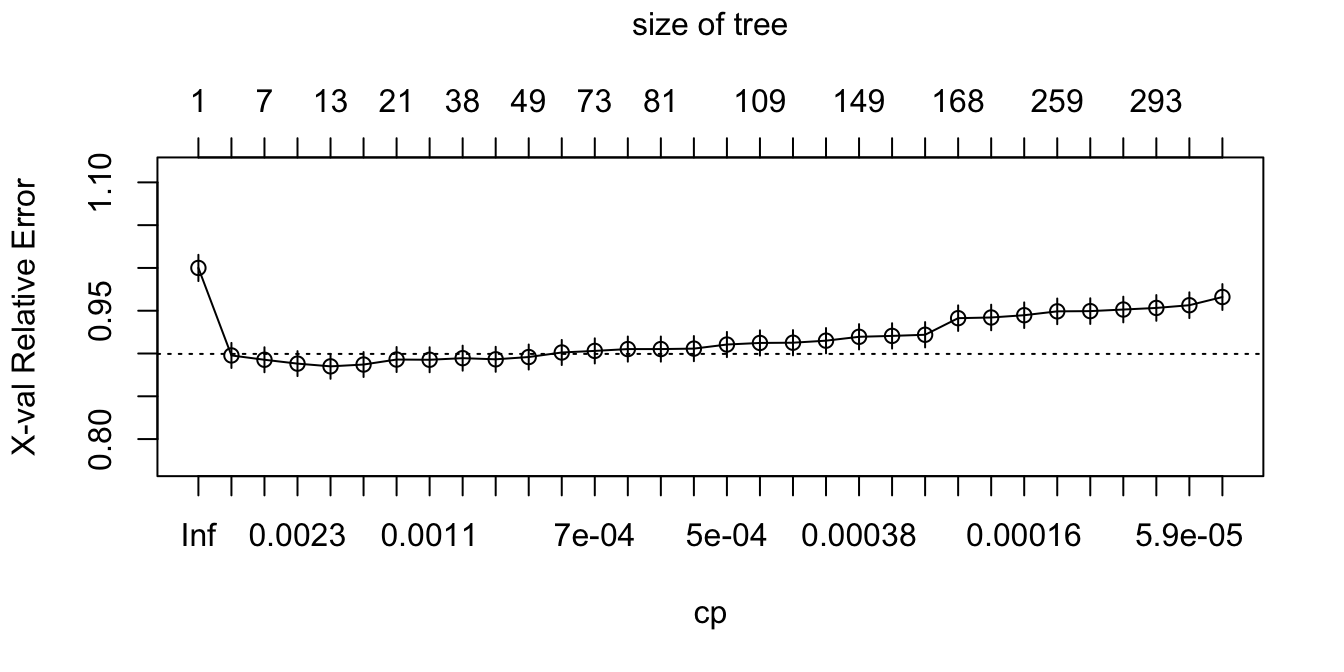
En la Figura 7.7 se presenta el parámetro de complejidad (\(cp\)) (eje horizontal, parte inferior) del árbol y el error relativo (eje vertical). Ahora, podemos el árbol empleando un \(cp\) de 0.001328. El siguiente código produce el árbol podado que se presenta en la Figura 7.8.
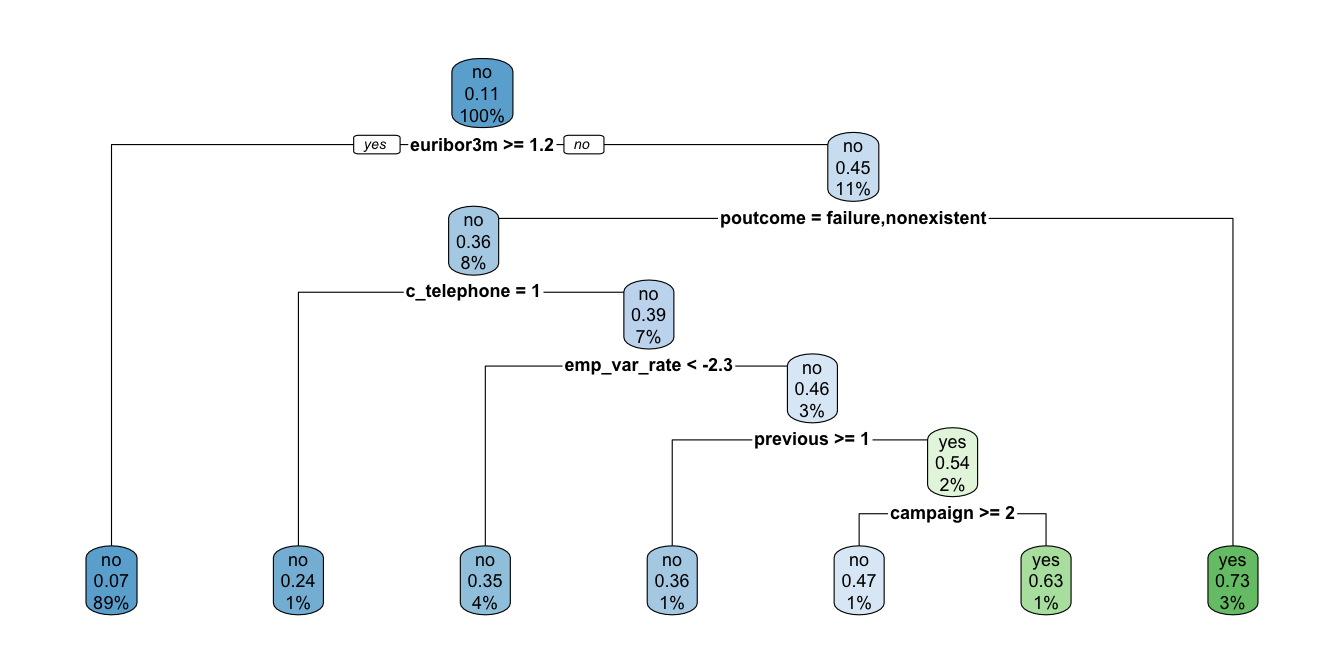
Figura 7.8: Árbol construido con el criterio de Gini post-podado empleando el parámetro de complejidad
7.4.2 Corriendo el algoritmo con el criterio de entropía
Ahora podemos repetir el ejercicio empleando el índice de entropía como criterio para la separación de las muestras. Es decir, primero corramos el árbol sin ninguna poda con el siguiente código:
RT_res_info<- rpart(formula = y ~ ., data= datos_dummies_est,
method = "class",
parms = list(split = "information"),
control = rpart.control(cp = 0))Ahora empleemos como método de pre-poda una profundidad máxima de 4 niveles, y guardemos los resultados en el objeto RT_res_info_4niveles.
RT_res_info_4niveles <- rpart(formula = y ~ ., data= datos_dummies_est,
method = "class",
parms = list(split = "information"),
control = rpart.control(cp = 0, maxdepth = 4))Y ahora empleemos como criterio de pre-poda que el número máximo de observaciones por rama sea de 500. Esto lo podemos hacer con el siguiente código:
RT_res_info_500obs <- rpart(formula = y ~ ., data= datos_dummies_est,
method = "class",
parms = list(split = "information"),
control = rpart.control(cp = 0, minsplit = 500))Finalmente, empleemos una post-poda con el parámetro de complejidad (\(cp\)).
#Guardar los resultados del cp en un objeto para encontrar el mínimo con una función
res2 <- printcp(RT_res_info)## [1] 0.0013280217.4.3 Bondad de ajuste del modelo
Ahora comparemos el ajuste de los seis modelos podados: tres podados con el criterio de Gini y tres con el de entropía.
Ahora generemos la matriz de confusión y las correspondientes métricas, para determinar cuál de todas las seis aproximaciones es la mejor. Primero debemos generar las predicciones fuera de muestra para la clase. Esto se puede hacer de manera similar a lo que hicimos en el caso del modelo Logit, Naive Bayes y el \(kNN\).
pred_RT_res_gini_4niveles <- predict(RT_res_gini_4niveles, newdata = datos_dummies_eval, type = "class") ## Confusion Matrix and Statistics
##
## Reference
## Prediction no yes
## no 7305 720
## yes 58 155
##
## Accuracy : 0.9056
## 95% CI : (0.899, 0.9118)
## No Information Rate : 0.8938
## P-Value [Acc > NIR] : 0.0002286
##
## Kappa : 0.2539
##
## Mcnemar's Test P-Value : < 2.2e-16
##
## Sensitivity : 0.17714
## Specificity : 0.99212
## Pos Pred Value : 0.72770
## Neg Pred Value : 0.91028
## Prevalence : 0.10622
## Detection Rate : 0.01882
## Detection Prevalence : 0.02586
## Balanced Accuracy : 0.58463
##
## 'Positive' Class : yes
## Ahora replica esto para los otros 5 modelos
En el Cuadro 7.1 se reportan las métricas que permiten comparar todos los modelos que hemos estimado hasta ahora.
| Accuracy | Sensitivity | Specificity | Precision | F1 | |
|---|---|---|---|---|---|
| Modelo Logit | 0.846 | 0.618 | 0.873 | 0.366 | 0.460 |
| Naive Bayes | 0.854 | 0.472 | 0.899 | 0.357 | 0.407 |
| kNN | 0.897 | 0.167 | 0.984 | 0.551 | 0.256 |
| RT_gini_4niveles | 0.906 | 0.177 | 0.992 | 0.728 | 0.285 |
| RT_gini_500obs | 0.907 | 0.203 | 0.991 | 0.727 | 0.318 |
| RT_gini_podado | 0.909 | 0.254 | 0.986 | 0.689 | 0.371 |
| RT_info_4niveles | 0.906 | 0.177 | 0.992 | 0.728 | 0.285 |
| RT_info_500obs | 0.907 | 0.203 | 0.991 | 0.727 | 0.318 |
| RT_info_podado | 0.909 | 0.254 | 0.986 | 0.689 | 0.371 |
| Fuente: elaboración propia. |
Hasta aquí el mejor modelo en términos de accuracy es el que hemos denominado RT_gini_podado. En términos de sensibilidad el mejor modelo es Modelo Logit. En especificidad el mejor modelo es el RT_gini_4niveles. En precisión el mejor modelo es RT_gini_4niveles. Y en términos del puntaje \(F_1\), el mejor modelo es Modelo Logit. Decidir entre estos modelos no es una tarea fácil y tendrá que ser el negocio, en especial el analytics translator con los tomadores de decisiones, que tendrán que determinar cuál métrica es más conveniente para el negocio y el uso que se le dará al modelo seleccionado.
Finalmente, guarda el espacio de trabajo para ser empleado en los siguientes capítulos.
7.5 Comentarios Finales
En este Capítulo hemos explorado el método de árbol de decisión aplicado a tareas de clasificación. Como se mencionó anteriormente, a priori, es imposible saber si este método será mejor que el estadístico u otros de aprendizaje de máquina y por eso es una buena práctica que se empleen diferentes aproximaciones y se comparen fuera de muestra.
Las aplicaciones de estos métodos de clasificación son muchas en el mundo de los negocios y definitivamente estos modelos son necesarios en la caja de herramientas de un científico de datos.
Referencias
También conocido como aprendizaje automático o aprendizaje automatizado. Este término viene del inglés machine learning.↩︎
Cuando se emplea el \(cp\) para hacer la poda, a la aproximación se le conoce como Cost-complexity pruning (CCP). ↩︎
Los economistas usan el coeficiente de Gini como una medida de desigualdad en la distribución del ingreso.↩︎