9 Modelo de Support Vector Machine (SVM)
Objetivos de Aprendizaje
Al finalizar la lectura de este capítulo el estudiante estará en capacidad de:
- Explicar en sus propias palabras cómo funciona un modelo SVM de clasificación.
- Entrenar y evaluar un modelo SVM en R.
- Calcular métricas de la bondad de ajuste de un modelo de clasificación estimado por medio de un modelo SVM.
- Encontrar los pronósticos de clasificación de un modelo SVM.
9.1 Introducción
En los capítulos anteriores hemos discutido modelos de clasificación de aprendizaje de máquina con filosofías relativamente diferentes. El modelo \(kNN\) (Capítulo 6) emplea los \(k\) vecinos más cercanos para votar sobre la clase de un individuos. El algoritmo de clasificación de árbol (Capítulo 7) construye el modelo de clasificación a través de la creación de divisiones jerárquicas basadas en las variables consideradas. Estos enfoques, diferentes en su filosofía, ayudan a abordar la tarea de clasificación desde diferentes perspectivas. Por otro lado, el Random Forest es un algoritmo que continúa con la idea de los árboles de clasificación y combina múltiples árboles de decisión para mejorar la precisión y generalización del modelo. Cada árbol en el bosque se entrena de forma independiente y luego se combinan los resultados para obtener una predicción más robusta. Estas aproximaciones, combinadas con las aproximaciones de origen estadístico como el modelo Logit (Capítulo 3) y el Naive Bayes (Capítulo 5), se complementan para atacar la tarea de clasificación desde diferentes frentes.
En este Capítulo estudiaremos un método del campo de machine learning que tiene una filosofía totalmente diferente: el modelo Support Vector Machine (SVM)58. El modelo SVM entra a completar nuestra caja de herramientas de métodos para realizar la tarea de clasificación. Estos modelos se caracterizan por comportarse relativamente bien cuando se cuenta con muchas variables explicativas (features), es decir, datos de alta dimensión y con comportamientos no lineales. Estas dos características hacen del modelo SVM, un modelo versátil para resolver una amplia gama de problemas de clasificación (Wang et al., 2009).
Los modelos SVM se han convertido en un método potente y ampliamente utilizado para resolver problemas de clasificación en diferentes campos, como el reconocimiento de imágenes, la categorización de textos, la bioinformática y el marketing. En la siguiente sección estudiaremos intuitivamente cómo funciona este modelo para después realizar una aplicación en R.
9.2 El método
El modelo SVM tiene como principio intentar separar lo mejor posible las diferentes clases empleando un “punto”, línea o hiperplano59. Empleemos unos ejemplos para entender esta idea.
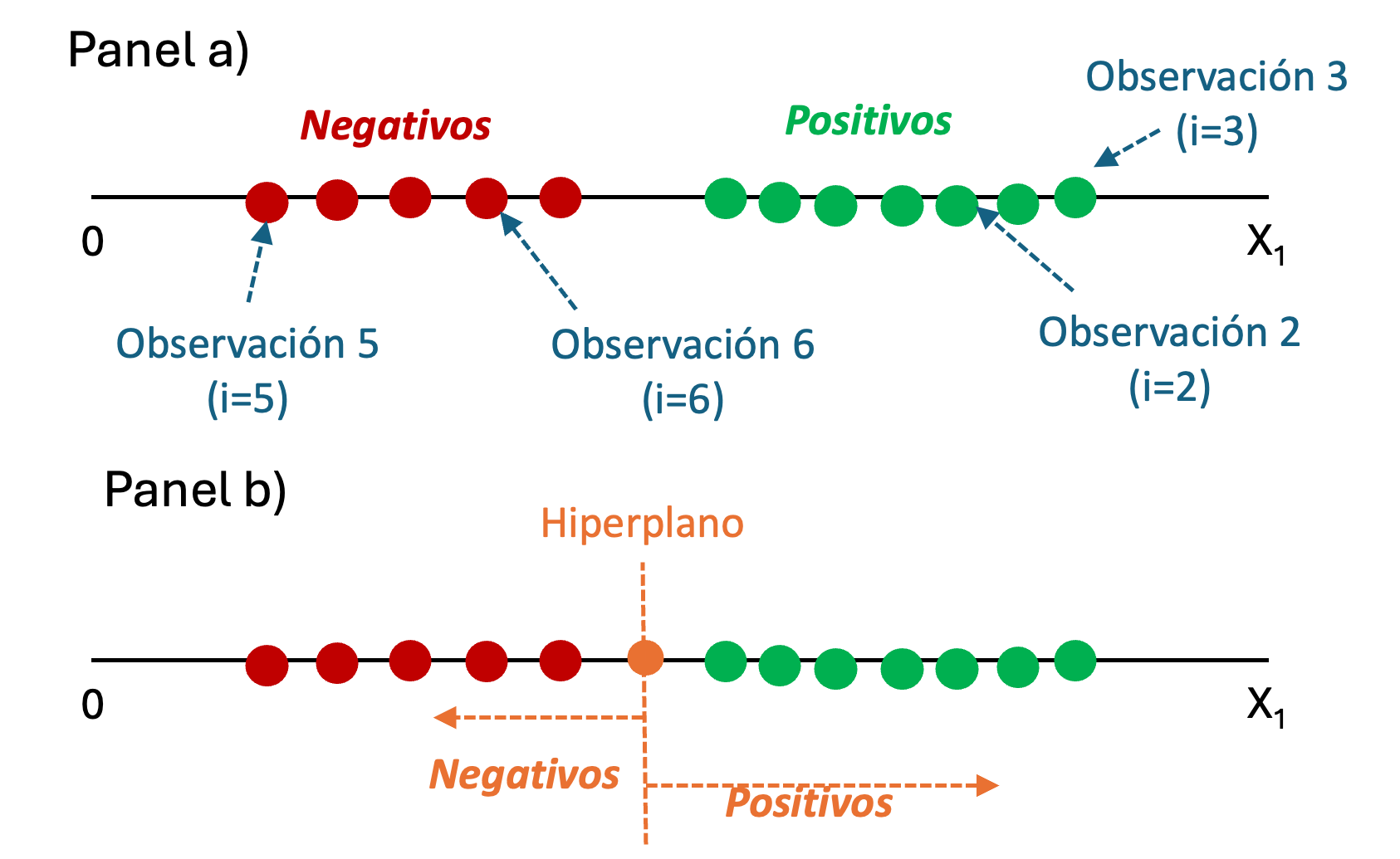
Partamos de un caso muy sencillo en el que tenemos una variable objetivo con dos categorías, tal como lo hemos hecho en los capítulos pasados. Tenemos unas observaciones que corresponden a negativos (puntos rojos) y otras a positivos (puntos verdes) y una sola variable explicativa (feature) \(X_1\), tal como se muestra en el panel a) de la Figura 9.1.
En este contexto, el objetivo del modelo de clasificación, es poder “clasificar” una nueva observación en negativo y positivo empleando una única variable con la que contamos para entrenar el modelo (\(X_1\)). Es decir, tenemos un problema de una dimensión. Para este caso de un feature, la filosofía de este modelo, implica encontrar un “punto” para los valores de \(X_1\) a partir del cual se puede determinar que el individuo se clasificará como positivo. En el panel b) de la Figura 9.1 se presenta un punto (en color naranja) que clasifica bien a todos los individuos.
Figura 9.1: Representación gráfica del modelo SVM para un espacio de una característica (una variable explicativa)
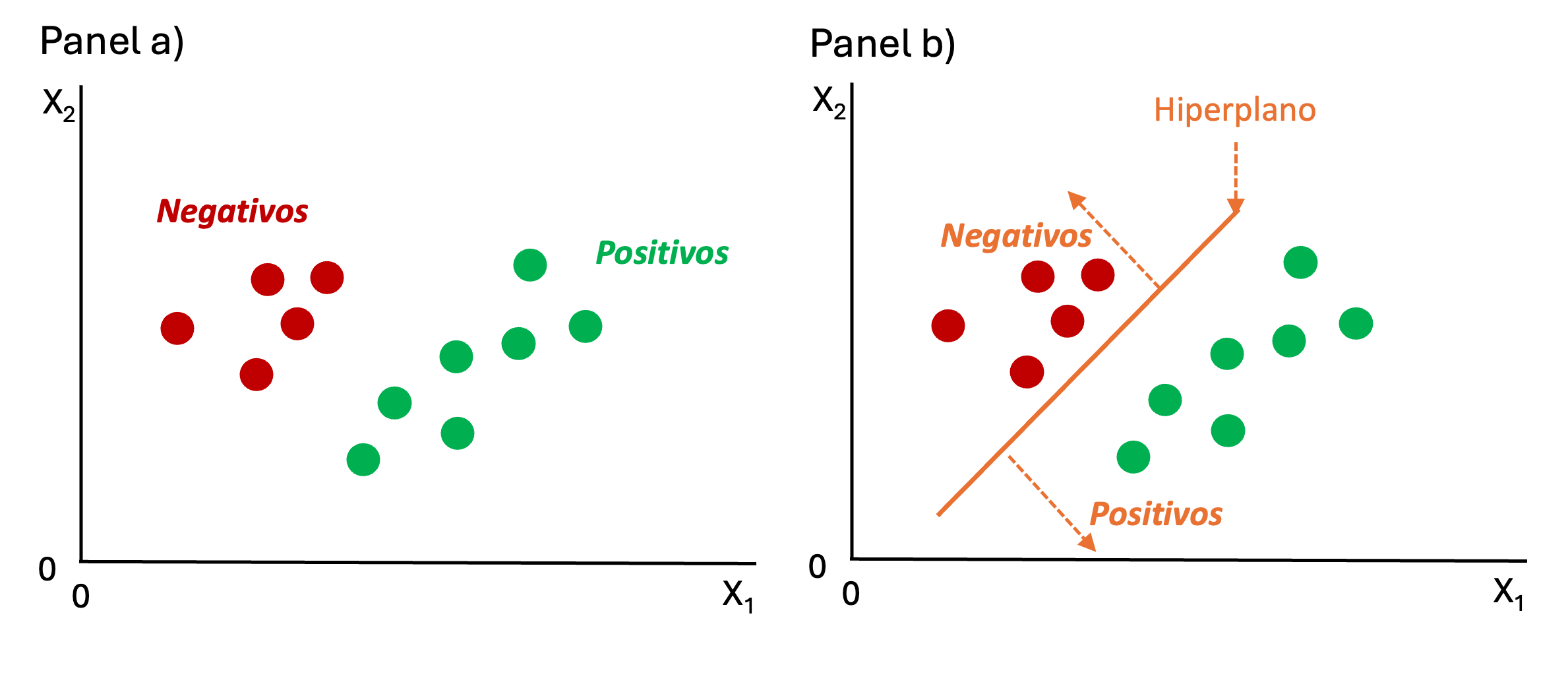
Consideremos el caso en el que se cuenta con dos características (\(X_1\) y \(X_2\)) para clasificar a los individuos en positivos (puntos verdes) y negativos (puntos rojos) como se muestra en la Figura 9.2. En el panel b) de la Figura 9.2 se puede ver cómo el método SVM implicará encontrar una línea (línea naranja) para clasificar las observaciones positivas y negativas. En este caso, todos los individuos han quedado bien clasificados.
Figura 9.2: Representación gráfica del modelo SVM para un espacio de dos características (dos variables explicativas)
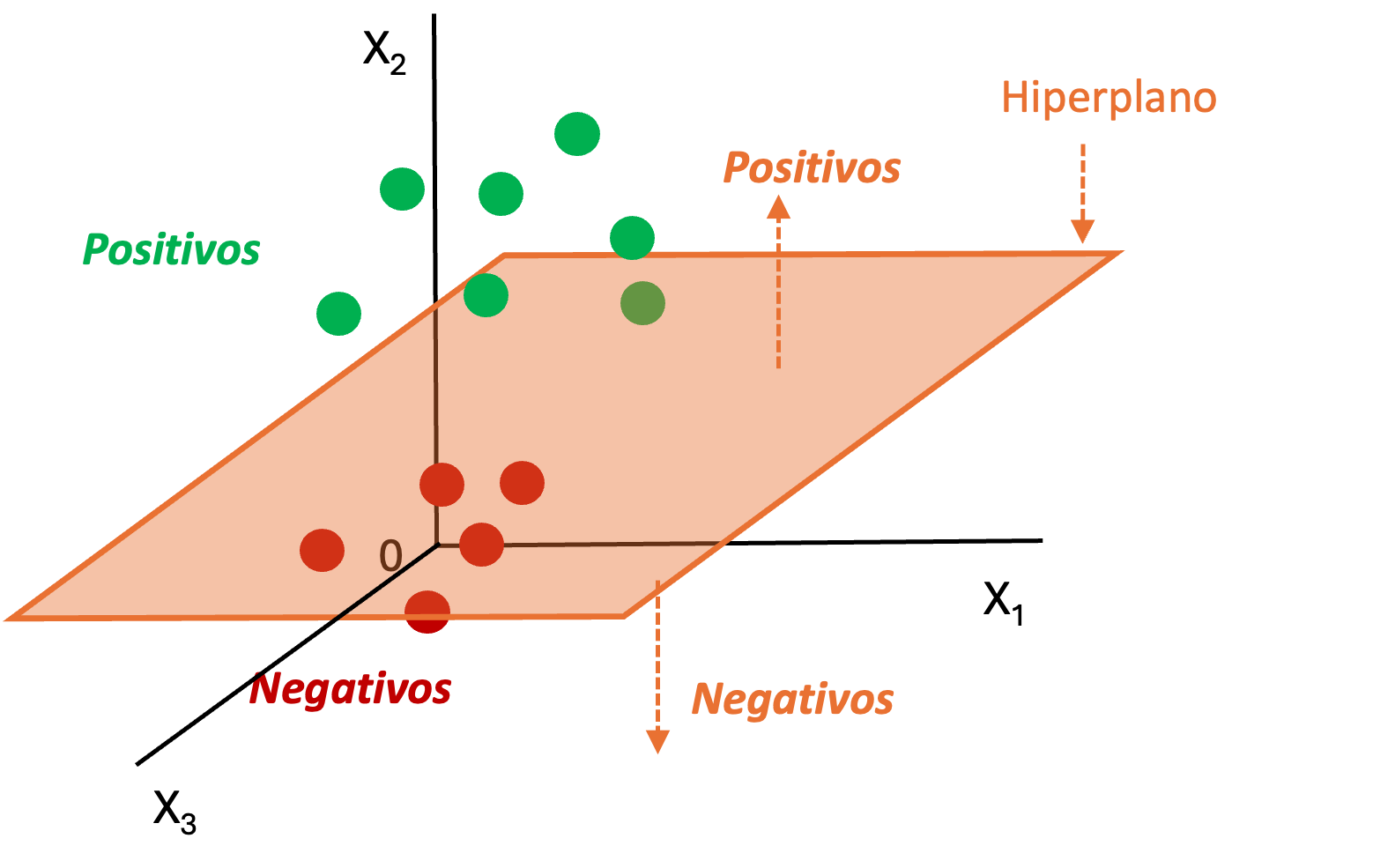
Ahora, supongamos que tenemos 3 variables explicativas (\(X_1\), \(X_2\) y \(X_3\)). En este caso, el algoritmo SVM tendrá que emplear un plano para clasificar los datos (Ver Figura 9.2). Y así sucesivamente, en dimensiones mayores (más variables) se empleará el equivalente a la línea o el plano para clasificar los individuos.
Figura 9.3: Representación gráfica del modelo SVM para un espacio de tres caracteristicas (tres variables explicativas)
En general, los modelos de SVM pueden entenderse a partir del concepto de hiperplano. Un hiperplano es un límite de decisión que separa puntos de datos de diferentes clases en un espacio de características. El objetivo del modelo SVM es encontrar el hiperplano que separa al máximo los puntos de datos de las diferentes clases. Regresemos al caso de dos características, note que se podrían trazar muchas líneas rectas que separen los datos (Ver panel a) de la Figura 9.3). Para encontrar el hiperplano de separación óptimo, el SVM emplea un proceso de optimización.
Figura 9.4: Diferentes posibles hiperplanos y el margen en el modelo SVM
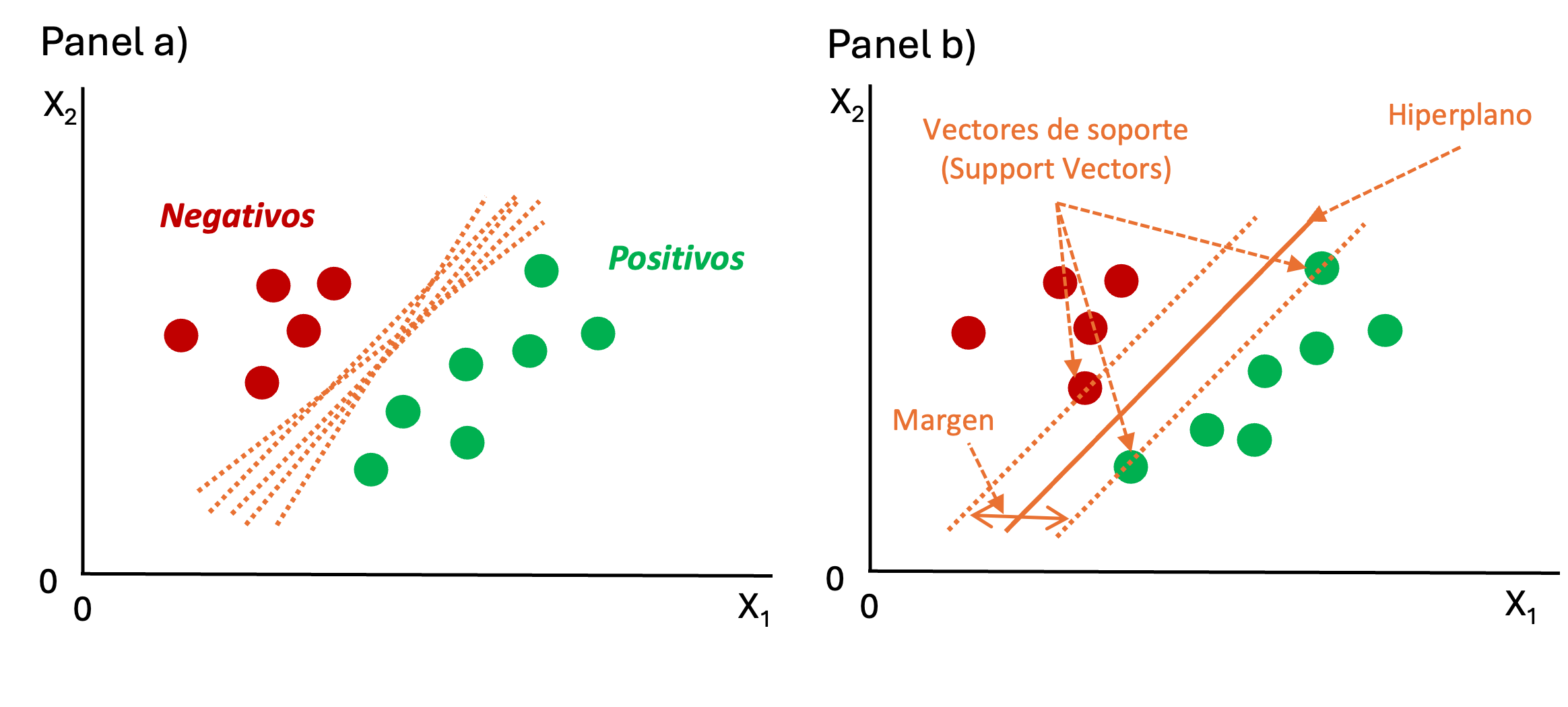
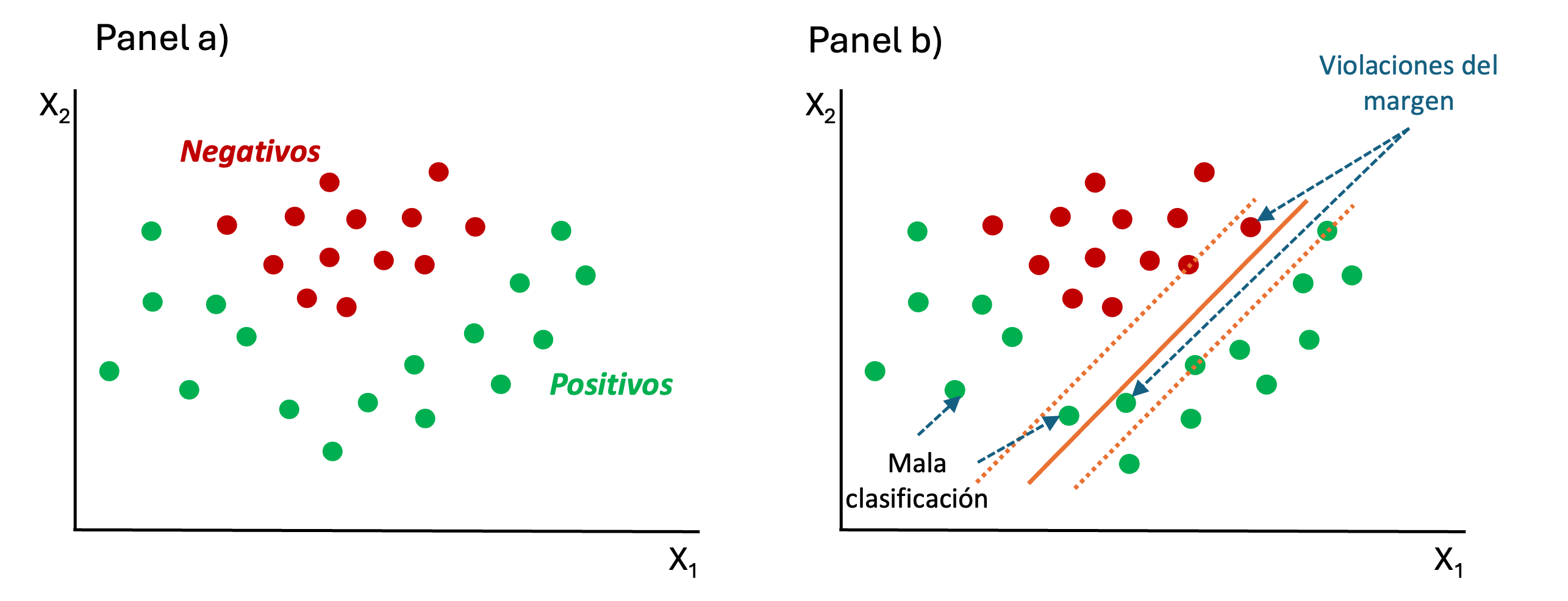
El objetivo de un SVM es encontrar el hiperplano que maximice el margen entre ambas clases. El margen es la distancia mínima entre el hiperplano y los puntos de datos más cercanos a él (Ver panel b) de la Figura 9.4). Los puntos más cercanos son de hecho el soporte del hiperplano, de ahí que esos puntos son llamados vectores de soporte en inglés support vector, lo cuál da el nombre al método (Ver panel b) de la Figura 9.4).
El margen, entonces, corresponde a la distancia entre el hiperplano y los puntos de datos más cercanos de cada clase. Un margen más amplio indica un modelo más robusto y generalizable, ya que hay un mayor espacio entre las clases. Al optimizar el margen de un modelo SVM60 se puede lograr un equilibrio entre precisión para la muestra de entrenamiento y la generalización a cualquier nueva muestra, incluyendo la de evaluación.
En esencia, el hiperplano actúa como una frontera de decisión, clasificando nuevos datos a un lado u otro del mismo y el margen da una zona a lado y lado del hiperplano en la que se pueden encontrar los puntos de datos de las diferentes clases. Este espacio adicional proporcionado por el margen ayuda a mejorar la capacidad del modelo SVM para generalizar de manera efectiva a nuevos individuos aún no observados y realizar predicciones mas precisas.
¡Pero el mundo no necesariamente es lineal! En algunas ocasiones podríamos tener datos como los que se presentan en el panel a) de la Figura 9.5. En un caso como este, el SVM no hará una buena clasificación de los individuos como si ocurrió en los casos mostrados en las Figuras 9.1), 9.2) y 9.3). Si empleamos un hiperplano (que es lineal), en estos datos tendremos puntos mal clasificados y algunas violaciones del margen (Ver panel b) de la Figura 9.5).
Figura 9.5: Datos no lineales y el modelo SVM
En algunas ocasiones los datos no presentan una clasificación clara, o por lo menos que se pueda realizar con un plano (lineal) (como el caso del panel b) de la Figura 9.5). En las Figuras 9.1 y 9.2 se muestran casos en los que los datos se pueden separar fácilmente con un hiperplano. En ese caso, se dice que los datos son linealmente separables. En las Figuras 9.5 y 9.6 se presentan ejemplos de datos que no son linealmente separables.
Figura 9.6: Ejemplo de datos no separables lienalmente

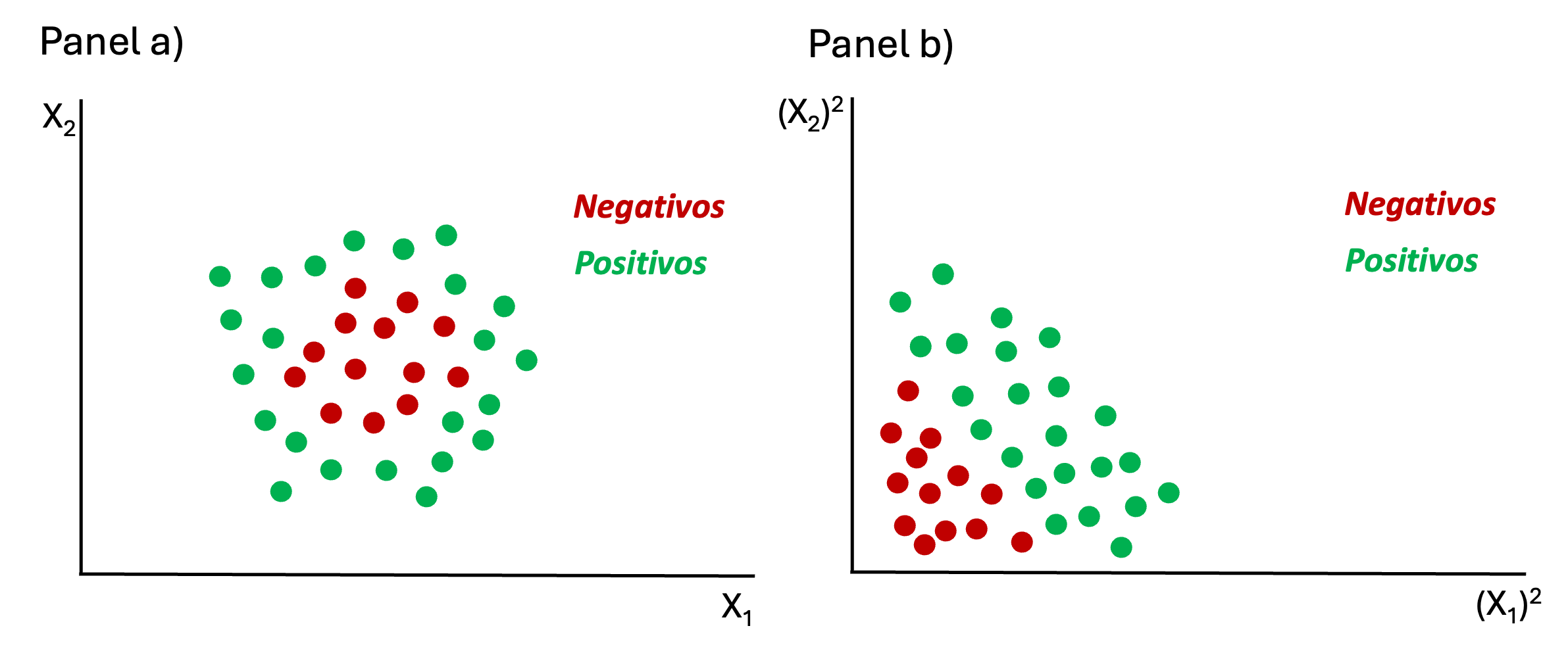
Para resolver este problema, es importante introducir un nuevo concepto: el kernel. El kernel es una función matemática que permite mapear (transformar) los datos originales a un espacio de características (variables) diferentes, donde la separación entre clases se vuelve más evidente61.
El hiperplano62 separa las clases, y el kernel es una herramienta que permite transformar los datos a un espacio diferente donde esa separación es más clara que permite a los SVM trabajar con datos no linealmente separables, mientras que el hiperplano es la frontera que realiza la clasificación63.
Por ejemplo, podemos emplear una transformación como elevar al cuadrado las dos variables para convertir los datos del panel a) de la Figura 9.7 para obtener unos datos linealmente separables como se presenta en el panel b) de la misma figura. Es decir, en el panel b) de la Figura 9.7 se presentan los datos del panel después de aplicarles el kernel. Al trabajar en este nuevo espacio64, ahora se puede encontrar un hiperplano lineal que separe mejor las clases, lo cual no era posible en el espacio original.
Figura 9.7: Ejemplo de datos no separables linealmente transformados con un kernel a datos separables
Existen diferentes tipos de kernels, cada uno con sus propias ventajas y desventajas. Los kernels más comunes son: lineal, polinómico y el RBF (Radial Basis Function)65. Formalmente,
Kernel Lineal: \(K(\mathbf{x}_i, \mathbf{x}_j)=\mathbf{x}_i^T \mathbf{x}_j\) Kernel Polinómico: \(K(\mathbf{x}_i, \mathbf{x}_j) = (\gamma (\mathbf{x}_i^T \mathbf{x}_j + c_0))^d\) Kernel RBF: \(K(\mathbf{x}_i, \mathbf{x}_j) = e^{\gamma ||\mathbf{x}_i^T \mathbf{x}_j ||^2}\) Noten que \(d\) corresponde al grado de la transformación polinómica y \(c_0\) controla cuánto influyen los términos de grado más alto en el kernel polinómico. Un valor de \(c_0\) más alto dará más peso a los términos de grado superior, lo que puede llevar a un límite de decisión menos lineal y flexible. Por otro lado, un valor más bajo de \(c_0\) reduce la influencia de los términos de grado superior, lo que hace que el límite de decisión sea más suave y lineal. Y \(\gamma\) controla la influencia de un solo punto de datos en el ajuste del modelo. Valores bajos de \(\gamma\) significan que los puntos de datos lejanos tienen un impacto grande en el límite de decisión, mientras que valores altos significan que solo los puntos cercanos tienen un impacto significativo.
El kernel RBF es mucho más flexible que los otros dos kernels pues permite ajustarse a transformaciones muy complejas. Por esta razón, esta es la transformación más empleada en la práctica.
Por otro lado, al entrenar un modelo SVM también se debe escoger el parámetro de costo. Este parámetro representa la importancia de clasificar correctamente cada punto de datos en el proceso de entrenamiento. En otras palabras, este parámetro controla el equilibrio entre maximizar el margen y minimizar la clasificación incorrecta de puntos. Un valor alto del costo significa que el modelo intentará clasificar correctamente la mayoría de los puntos de datos de entrenamiento, incluso si eso significa tener un margen más estrecho. Por otro lado, un valor bajo del costo permitirá un margen más amplio, lo que puede resultar en una clasificación incorrecta de algunos puntos de datos de entrenamiento, pero posiblemente una mejor generalización para datos nuevos. En otras palabras, el parámetro de costo establece cuánto error estamos dispuestos a sacrificar para encontrar el hiperplano. Esto se hace con el fin de evitar el overfitting o sobreajuste, además de disminuir la sensibilidad del método ante nuevas observaciones.
Así, en la práctica nos enfrentaremos a decidir:
- el kernel a usar,
- el costo,
- \(d\) y \(c_0\) para el kernel polinómico,
- \(\gamma\) para los kernels polinómico y RBF.
Por lo general, se entrena el modelo SVM para los diferentes kernels empleando una búsqueda de grilla para los parámetros pertinentes. Esa búsqueda de los mejores parámetros se denomina en inglés tune y en la jerga de los científicos de datos como “tunear” el modelo. Y finalmente se selecciona la mejor combinación de parámetros para un SVM y kernel empleando una métrica de selección, por ejemplo el Accuracy.
9.3 Implementación en R
Empecemos por cargar el working space que guardaste en el Capítulo 8.
En este caso, similar a lo ocurrido en el modelo \(kNN\) (Ver Capítulo 6), es necesario usar las variables cuantitativas estandarizadas66 (las de clase numérico (numeric) o entero (integer) para evitar que las escalas diferentes tengan un efecto sobre el algoritmo.
Como se discutió en la Sección 6.3, en este caso las variables a estandarizar son:
age,campaign,previous,emp.var.rate,cons.price.idx,cons.conf.idx,euribor3m.
En la Sección 6.3 ya realizamos dicha estandarización empleando la función scale() de la base de R. Emplearemos los objetos datos_expl_est y y_est en los que tenemos las variables explicativas para la muestra de estimación y la variable objetivo para la muestra de evaluación respectivamente (Ver sección 6.3).
Por otro lado, en el modelo SVM se pueden emplear variables predictoras (features) cualitativas codificadas como variables dummy (de clase factor) tal como lo realizamos en el Capítulo 3. En ese Capítulo empleamos la función dummy_cols() del paquete fastDummies (Kaplan, 2023) para crear las correspondientes variables dummy que hemos venido empleando en los siguientes capítulos.
Dichas variables dummy las tenemos en la columna 10 a la 50 de los objetos datos_dummies_est y datos_dummies_eval que corresponden a las muestras de estimación y evaluación respectivamente.
Procedamos a unir las variables predictoras estandarizadas y las variables en un solo objecto, uno para la muestra de entrenamiento y otra para la de evaluación.
# Crear data.frame con variables cuantitativas escaladas y variables dummies
datos_X_svm_est <- bind_cols(datos_expl_est, datos_dummies_est[, 10:50])
datos_X_svm_eval <- bind_cols(datos_expl_eval, datos_dummies_eval[, 10:50])
# Unir las bases en una sola para la muestra de estimación
datos_svm_est <- cbind(datos_X_svm_est, y_est)Para realizar el entrenamiento del modelo SVM en R, usaremos el paquete caret(Kuhn & Max, 2008) que permite “tunear” el modelo empleando tres funciones: trainControl(), expand.grid() y train. La función trainControl() permite establecer las condiciones bajo las cuales se realizará el ejercicio de tunning. La función expand.grid() establece sobre que valores se va a desarrollar la búsqueda de grilla; y finalmente la función train() pone todo junto y establece el tipo de modelo que se empleará, así como los datos.
Realicemos un ejercicio de “tuneo” del modelo que realice una búsqueda de grilla (search = “grid”)67 y que emplee bootstrapping68 para evaluar sobre diferentes submuestras el desempeño de todas las combinaciones de parámetros a evaluar.
# Cargar la librería
library(caret)
# Fijar la forma como se realizará el tunninng
metodo_tune <- trainControl(
method = "boot",
search = "grid")Dado que queremos entrenar un modelo SVM con kernel lineal, solo necesitamos realizar una búsqueda de grilla sobre el parámetro costo. Consideremos una búsqueda sobre los siguientes valores de costo (\(C\)): 0.01, 0.1, 1, 10 y 50. Esto lo podemos hacer con el siguiente código.
# Establecer la grilla de búsqueda para el costo
grilla_busqueda <- expand.grid(C = c(0.01,0.1,1,10,50))Ya tenemos los objetos metodo_tune y grilla_busqueda en los que hemos especificado el tipo de ejercicio de tunning y la grilla sobre la que se hará el ejercicio, respectivamente. Ahora, solo necesitamos entrenar el modelo SVM empleando la función train().
Similar a las funciones empleadas en capítulos anteriores, el primer argumento de la función es la fórmula (form) que específica las variables dependientes e independiente. Adicionalmente, está el argumento para los datos (data) que deben estar en un objeto de clase data.frame . Otro argumento es method que específica el tipo de modelo a entrenar. Para el caso de un SVM con kernel lineal, este argumento se convierte en method = “svmLinear”. Las funciones que estiman el modelo SVM en caret pertenecen al paquete kernlab . Y por tanto, necesitarás tener instalado dicho paquete para poder entrenar el modelo SVM. Otros dos argumentos son trControl y tuneGrid que especifican el tipo de ejercicio de tunning que se realizará y el espacio sobre el que se realizará la búsqueda de grilla, respectivamente. Finalmente, es necesario especificar cuál métrica (metric) se empleará para seleccionar la mejor combinación de parámetros.
Para nuestro caso, entonces emplearemos como fórmula a la variable y en función de todas las variables en el data.frame datos_svm_est (nuestra muestra de estimación). Emplearemos la especificación del ejercicio de tunning que guardamos en el objeto metodo_tune, el accuracy como métrica de selección del mejor modelo y una búsqueda de grilla sobre los posibles valores de costo definidos en el objeto grilla_busqueda. Todo esto lo logramos con el siguiente código:
set.seed(123)
## empezar el tunning para el modelo svm con kernel lineal
model_svm_lineal <- train(form = y_est ~ ., data = datos_svm_est,
method = "svmLinear",
trControl = metodo_tune,
metric = 'Accuracy',
tuneGrid = grilla_busqueda)Estos cálculos tomarán un tiempo considerable. Dependiendo de tu computador, el cálculo podrá tomar hasta días, ¡ten paciencia! En el objeto model_svm_lineal quedará guardada toda la búsqueda y el mejor modelo (combinación de parámetros) de acuerdo a la métrica seleccionada, así mismo quedará guardado en este objeto muchos otros resultados del proceso de búsqueda. Veamos el objeto model_svm_lineal y todos sus compartimientos:
## Support Vector Machines with Linear Kernel
##
## 32950 samples
## 48 predictor
## 2 classes: 'no', 'yes'
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 32950, 32950, 32950, 32950, 32950, 32950, ...
## Resampling results across tuning parameters:
##
## C Accuracy Kappa
## 0.01 0.8869937 0.1302668
## 0.10 0.8880890 0.1925624
## 1.00 0.8880822 0.1934050
## 10.00 0.8864819 0.1837770
## 50.00 0.8863731 0.2046663
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was C = 0.1.## $names
## [1] "method" "modelInfo" "modelType" "results" "pred"
## [6] "bestTune" "call" "dots" "metric" "control"
## [11] "finalModel" "preProcess" "trainingData" "ptype" "resample"
## [16] "resampledCM" "perfNames" "maximize" "yLimits" "times"
## [21] "levels" "terms" "coefnames" "xlevels"
##
## $class
## [1] "train" "train.formula"Los parámetros que optimizan la métrica seleccionada quedan guardados en el compartimiento con el nombre bestTune. Para nuestro caso, veamos el mejor valor del costo con el siguiente código.
## C
## 2 0.1Ahora podemos realizar la misma tarea empleando el kernel polinómico. Ahora, deberos modificar el espacio sobre el que se realizará la búsqueda de grilla para incorporar, además del costo, el grado del polinomio (degree) y la escala (scale).
# Establecer la grilla de búsqueda para el modelo SVM kernel polimonial
grilla_busqueda <- expand.grid(
C = c(0.01,0.1,1,10),
degree = c(2, 3),
scale = 0.01)Ahora podemos emplear la función train() para entrenar el modelo SVM con kernel polinómico empleando method = svmPoly.
# Tunear el modelo SVM kernel polimonial
model_svm_pol <- train(y_est ~ ., data = datos_svm_est,
method = "svmPoly",
trControl = metodo_tune,
metric = 'Accuracy',
tuneGrid = grilla_busqueda
)Este proceso de tunning tomará un poco menos de tiempo que el caso anterior. Los parámetros que optimizan el accuracy son:
## degree scale C
## 7 2 0.01 10Y finalmente realicemos el mismo ejercicio empleando el kernel RBF. En este caso, debemos modificar la grilla de búsqueda de la siguiente manera:
# Establecer la grilla de búsqueda para el modelo SVM kernel RBF
grilla_busqueda <- expand.grid(
C = c(0.01,0.1,1,10),
sigma = c(0.01, 0.1,1))Y el modelo SVM con kernel RBF (method = “svmRadial”) se puede entrenar con el siguiente código.
# Tunear el modelo SVM kernel RBF
model_svm_rbf <- train(y_est ~ ., data = datos_svm_est,
method = "svmRadial",
trControl = metodo_tune,
metric = 'Accuracy',
tuneGrid = grilla_busqueda
)En este caso los parámetros que optimizan el accuracy son:
## sigma C
## 7 0.01 1Nota que el parámetro de costo que optimiza el accuracy en los tres kernels considerados es diferente. Es decir, siempre deberíamos hacer la búsqueda de grilla sobre el espacio completo y no podemos emplear el resultado de un kernel para los otros. Estos procesos de tunning del modelo SVM son bastante exigentes en recursos de cómputo. Este último proceso toma aún más tiempo.
9.3.1 Bondad de ajuste del modelo
Ahora evaluemos fuera de muestra el comportamiento del modelo SVM para los tres kernels considerados. Para esto, podemos emplear las funciones predict() y confusionMatrix() como lo hemos hecho en los capítulos anteriores. Es decir, en nuestro caso tendremos para el kernel lineal el siguiente código:
# Calcular las predicciones en la muestra de evaluación
pred_svm_lineal <- predict(model_svm_lineal, datos_X_svm_eval)
# Calcular las métricas
mo_svm_lineal <- confusionMatrix(pred_svm_lineal, y_eval, positive = "yes")
mo_svm_lineal## Confusion Matrix and Statistics
##
## Reference
## Prediction no yes
## no 7232 690
## yes 131 185
##
## Accuracy : 0.9003
## 95% CI : (0.8937, 0.9067)
## No Information Rate : 0.8938
## P-Value [Acc > NIR] : 0.02705
##
## Kappa : 0.2695
##
## Mcnemar's Test P-Value : < 2e-16
##
## Sensitivity : 0.21143
## Specificity : 0.98221
## Pos Pred Value : 0.58544
## Neg Pred Value : 0.91290
## Prevalence : 0.10622
## Detection Rate : 0.02246
## Detection Prevalence : 0.03836
## Balanced Accuracy : 0.59682
##
## 'Positive' Class : yes
## En el Cuadro 9.1 se presentan las métricas de los modelos SVM con los tres kernels considerados para la muestra de evaluación.
| Accuracy | Sensitivity | Specificity | Precision | F1 | |
|---|---|---|---|---|---|
| Modelo Logit | 0.847 | 0.617 | 0.874 | 0.368 | 0.461 |
| Naive Bayes | 0.854 | 0.472 | 0.899 | 0.357 | 0.407 |
| kNN | 0.895 | 0.240 | 0.973 | 0.516 | 0.328 |
| RT_gini_500obs | 0.907 | 0.203 | 0.991 | 0.727 | 0.318 |
| RT_gini_podado | 0.909 | 0.254 | 0.986 | 0.689 | 0.371 |
| Random Forest | 0.903 | 0.255 | 0.980 | 0.604 | 0.359 |
| SVM lineal | 0.900 | 0.211 | 0.982 | 0.585 | 0.311 |
| SVM pol | 0.899 | 0.226 | 0.979 | 0.561 | 0.322 |
| SVM RBF | 0.897 | 0.153 | 0.986 | 0.558 | 0.240 |
| Fuente: elaboración propia. |
Poniendo todo junto, tenemos 9 modelos de clasificación candidatos a ser el “mejor” modelo. En términos de accuracy es el que hemos denominado RT_gini_podado. En términos de sensibilidad el mejor modelo es Modelo Logit. En especificidad el mejor modelo es el RT_gini_500obs. En precisión el mejor modelo es RT_gini_500obs. Y en términos del puntaje \(F_1\), el mejor modelo es Modelo Logit. Decidir entre estos modelos no es una tarea fácil y tendrá que ser el negocio, en especial el analytics translator con los tomadores de decisiones que tendrán que determinar que métrica es mas conveniente para el negocio y el uso que se le dará al modelo seleccionado. Este resultado nos permite entender la importancia de realizar un análisis detallado de cada métrica y su relevancia en el contexto específico de aplicación de los modelos de clasificación.
9.4 Comentarios finales
En este Capítulo hemos estudiado el modelo SVM de origen en el machine learning para desarrollar la tarea de clasificación. Este modelo completa la caja de herramientas para realizar esta tarea. Aunque existen aún más modelos, estos son los algoritmos más usados por científicos de datos en la actualidad. Finalmente, como se ha reiterado durante este libro, la práctica ideal es implementar todos los modelos para compararlos. Después de tener el mejor modelo, emplear toda la muestra para estar listo a realizar una predicción para individuos nuevos.
En los siguientes dos capítulos desarrollaremos dos casos de estudio en el que emplearemos todos los modelos estudiados hasta ahora.
Referencias
De hecho, el modelo SVM permite realizar tanto la tarea de clasificación como la de regresión.↩︎
Dependiendo de la cantidad de variables explicativas (features) que se empleen corresponderá a una línea para dos variables, un plano para tres variables, etc. Es decir, un hiperplano.↩︎
Maximizar el margen implica maximizar la distancia entre los vectores de soportes y el hiperplano.↩︎
En el contexto estadístico a la transformación de variables se le conoce como reparametrizar. En el Capítulo 2 de Alonso (2024) se presenta una introducción a este concepto.↩︎
Como lo dice su nombre, el hiperplano es plano; es decir, lineal.↩︎
Si estas familiarizado con el modelo de regresión clásico, de pronto te será común hacer transformaciones de variables para convertir un modelo que no es lineal matemáticamente a uno lineal desde el punto de vista estadístico (Ver Capítulo 2 de Alonso (2024)). Por ejemplo, cuando se emplean logaritmos para linealizar una función Cobb-Douglas. Es decir, linealizar un modelo en regresión múltiple es equivalente a lo que hace la función kernel para el modelo SVM.↩︎
Es decir, trabajar con las variables explicativas transformadas.↩︎
La forma funcional del kernel simula el principio del algoritmo \(kNN\). Es decir, genera una transformación que cuanto más cerca estén dos puntos entre sí en términos de atributos, más probable es que sean similares.↩︎
Es decir, se le quita la respectiva media para centrar los datos y se divide por la desviación estándar para garantizar que la varianza sea uno.↩︎
Otra opción de este argumento es que haga la búsqueda de manera aleatoria (search = “random”).↩︎
Para una explicación del método de bootstraping ver la discusión de la sección 8.2. ↩︎