4 Evaluación e interpretación de modelos Logit
Objetivos del capítulo
Al finalizar la lectura de este documento el estudiante estará en capacidad de:
- Explicar en sus propias palabras cuáles son las métricas específicas a los modelos Logit para determinar la bondad de ajuste.
- Calcular métricas de la bondad de un modelo de clasificación estimado por medio de un modelo de regresión logística.
- Interpretar los resultados de un modelo Logit.
- Calcular los pronósticos de un modelo de clasificación estimado por medio de un modelo de regresión logística.
4.1 Introducción
En el Capítulo 3 estudiamos cómo estimar un modelo Logit en R. Así mismo, se estudió cómo a partir de una conjunto grande de potenciales variables explicativas encontrar el “mejor” modelo, empleando diferentes técnicas de selección automática de modelos. Ahora, es importante discutir cómo comparar diferentes modelos. Como se menciona en el Capítulo 2, la naturaleza de los modelos de clasificación hace que necesitemos herramientas analíticas diferentes a las tradicionales para determinar el ajuste de los modelos. La variable dependiente ya no es continua, sino cualitativa y, en nuestro caso particular, dicotómica. Ya hemos discutido las medidas de ajuste basado en la exactitud del pronóstico (Ver Sección 2.3.2) que son comunes a todos los modelos de clasificación. Además se discutió algunas generalidades para determinar la bondad de un modelo de calificación que genera probabilidades (Ver Sección 2.3.1).
En la siguiente sección nos concentramos en medidas de ajuste específicas al modelo Logit. Posteriormente discutiremos cómo calcular en R estas métricas específicas del modelo Logit, así como las métricas que se aplican a todos los modelos de clasificación como las discutidas en las secciones 2.3.2 y 2.3.1. Finalmente, tras seleccionar el mejor modelo se discutirá como interpretar los resultados del modelo Logit.
4.2 Medidas basadas en el ajuste a la distribución asumida: LRI
Es importante resaltar que en este contexto no tiene mucho sentido emplear una medida como el \({R^2}\) para examinar la bondad de ajuste del modelo, pues el método de estimación no pretende minimizar la suma de los errores cuadrados. En este caso se emplea una medida de bondad de ajuste conocido como el índice de la razón de verosimilitud, comúnmente conocida como el \(LRI\) (por la sigla del término en inglés Likelihood Ratio Index). El \(LRI\) también es conocido como el R cuadrado de McFadden (McFadden’s R squared). Esta medida tiene similitudes con el \({R^2}\) ajustado al no tener interpretación clara, y no verse afectado por la exclusión o inclusión de variables, por otro lado el \(LRI\) se encuentra acotado entre 0 y 1; de tal manera que cuanto más grande el índice, mejor será el ajuste del modelo.
El LRI se calcula de la siguiente manera: \[\begin{equation*} LRI = 1 - \frac{{\ln L\left( {\hat \beta } \right)}}{{\ln {L_0}}} \end{equation*}\] Donde \(\ln L\left( {\hat \beta } \right)\) corresponde al valor de la función de verosimilitud en su máximo y \(\ln {L_0}\) corresponde al valor del logaritmo de la función de verosimilitud si todos los parámetros fueran cero, excepto el intercepto. Este último valor se puede calcular de la siguiente manera: \[\begin{equation*} \ln {L_0} = n\left[ {P\ln \left( P \right) + \left( {1 - P} \right)\ln \left( {1 - P} \right)} \right] \end{equation*}\] Donde \(P\) es la proporción de observaciones para las cuales la dummy es igual a uno, es decir \(P = \left( \# obs = 1 \right) / n\). El \(LRI\) también es conocido como el Pseudo \(R^2\) de McFadden (McFadden, 1972).
Sin embargo, no es el único estadístico disponible. Cox & Snell (1989) proponen el siguiente indicador similar al \(R^2\) ajustado (conocido como Psuedo \(R^2\)): \[\begin{equation*} R^2_{Cox \& Snell} = 1 - \left( \frac{{L_0}}{{L\left( {\hat \beta } \right)}}\right)^\frac{{2}}{{n}} \end{equation*}\]
Por último, otro denominado Pseudo \(R^2\), es el propuesto por Nagelkerke et al. (1991): \[\begin{equation*} R^2_{Nagelkerke} = \frac{{1-\left( \frac{{L_0}}{{L\left( {\hat \beta } \right)}} \right)^\frac{{2}}{{n}}}} {{1-\left(L_0\right)^\frac{{2}}{{n}}}} \end{equation*}\]
Anteriormente se discutió la necesidad de emplear una variable latente (\(Z_i\)), no observable para estimar este tipo de modelos. Si bien esa variable no es observable, se puede estimar empleando los \(\beta\) estimados. Es decir, \[\begin{equation*} \hat{Z}_i = \hat{\beta} ^T \mathbf{x}_i^T \end{equation*}\]
Por otro lado, el error \({\varepsilon_i}\) que no es observable no puede ser estimado en este caso, pues no se cuenta con \(Z_i\), para calcular \({\hat \varepsilon_i} = {Z_i} - {\hat Z_i}\). Esa variable latente puede ser empleada para calcular la probabilidad de que observemos un valor de \(y_i\) igual a uno para el individuo \(i\) con características registradas en \(\mathbf{x}_i\). A esta probabilidad la llamaremos \(h_{\hat{\beta}}(\mathbf{x}_i)\) Esto se puede hacer de la siguiente manera: \[\begin{equation*} h_{\hat{\beta}}(\mathbf{x}_i) = \Lambda \left( {{\hat{\beta} ^T}{{\mathbf{x}}_i^T}} \right) = \Lambda \left( {- \hat{Z}_i } \right) \end{equation*}\]
4.3 Comparación de los modelos empleando R
Continuando con el ejemplo que iniciamos en el Capítulo 3, procedamos a evaluar los dos modelos que tenemos como candidatos a mejor modelo: el modelo 1 (guardado en el objeto modelo1) y el modelo 2 (guardado en el objeto modelo2). Carguemos el working space que guardamos en el Capítulo 3.
4.3.1 \(LRI\)
El \(LRi\) se puede encontrar de diferentes formas en R. \(\ln L\left( {\hat \beta } \right)\) corresponde al valor de la función de verosimilitud en su máximo y se encuentra fácilmente empleando la función logLik() aplicada al objeto de clase GLM que contenga el modelo. \(\ln {L_0}\) corresponde al valor del logaritmo de la función de verosimilitud si todos los parámetros fueran cero. Este corresponde al modelo mínimo que definimos arriba. Así, el \(LRI\) puede ser calculado manualmente de la siguiente manera:
## 'log Lik.' 0.213987 (df=36)## 'log Lik.' 0.2138849 (df=25)Según este indicador el mejor modelo es el 2. También podemos calcular el \(LRI\) (pseudo \(R^2\) de McFadden) y los pseudo \(R^2\) propuestos por Cox & Snell (1989) y por Nagelkerke et al. (1991), usando la función LogRegR2() del paquete descr (Aquino, 2023).
## Chi2 5010.892
## Df 35
## Sig. 0
## Cox and Snell Index 0.1410767
## Nagelkerke Index 0.2773341
## McFadden's R2 0.213987## Chi2 5008.501
## Df 24
## Sig. 0
## Cox and Snell Index 0.1410143
## Nagelkerke Index 0.2772116
## McFadden's R2 0.2138849En todos los 3 estadísticos, el modelo que presenta un mejor ajuste es el modelo2. Adicionalmente, es importante aclarar que estas métricas se calculan con la muestra de estimación y no con la de evaluación, pues fue con esta que se estimó el modelo.
Las siguientes métricas se calcularán sobre la muestra de evaluación y no la de estimación para determinar la capacidad del modelo a predecir en presencia de nueva información, tal como lo haría en la vida real.
4.3.2 Curva ROC y AUC
El primer paso es generar predicciones de la probabilidad de observar un positivo para cada individuo; es decir, debemos calcular \(h_{\hat\beta}(\mathbf{x}_i)\) que lo definimos como \(\Lambda \left( {{\hat{\beta} ^T}{{\mathbf{x}}_i^T}} \right)\). Recuerden que el valor predicho para cada individuo finalmente dependerá de si \(h_{\hat\beta}(\mathbf{x}_i)\) es mayor o no del punto de corte \(\lambda\). Estas predicciones la podemos construir con la función predict() aplicada al objeto de clase glm que tenga el modelo del que se quiere hacer la predicción.
Así mismo, debemos especificar los nuevos datos que se desean emplear para las predicciones (argumento newdata). Finalmente, es necesario especificar el tipo de pronóstico. Para el caso de un pronóstico de probabilidad, se emplea el argumento type = “response”.
Así, los pronósticos de probabilidades para los individuos de la muestra de evaluación de los dos modelos los podemos encontrar de la siguiente manera:
#probabilidades predichas para muestra de evaluación
prob_pred_modelo1 <- predict(modelo1, newdata = datos_eval,
type = "response")
prob_pred_modelo2 <- predict(modelo2, newdata = datos_dummies_eval,
type = "response")Ahora ya tenemos todos los elementos necesarios para construir la curva ROC. Recuerden que esta curva gráfica la sensibilidad (\(TPR\)) y la proporción de falsos negativos (\(FNR\)) para cada valor de corte (\(\lambda\)). Existen muchos paquetes para encontrar la curva ROC y el AUC. Nosotros emplearemos el paquete ROCit (Khan & Brandenburger, 2020).
La función rocit() del paquete ROCit (Khan & Brandenburger, 2020) permite calcular el \(TPR\) y \(FPR\) para diferentes valores de (\(\lambda\)). La función típicamente incluye los siguientes argumentos:
donde:
- score: Un vector que contiene las probabilidades pronosticadas para cada uno de los individuos (\(h_{\hat\beta}(\mathbf{x}_i)\)).
- class: Un vector con los positivos y negativos observados para cada individuo (\(y_i\)).
- method: El método para el calculo de la ROC. Para el caso de modelos Logit {method = “empirical”}. Este no es el valor por defecto.
Calculemos la curva ROC para el modelo 1.
library(ROCit)
roc.modelo1 <- rocit(score = prob_pred_modelo1,
class = datos_eval$y, method = "bin") Y la podemos graficar rápidamente empleando la función plot(). La curva ROC para el modelo1 se presenta en la Figura 4.1.
Figura 4.1: Curva ROC para el modelo 1
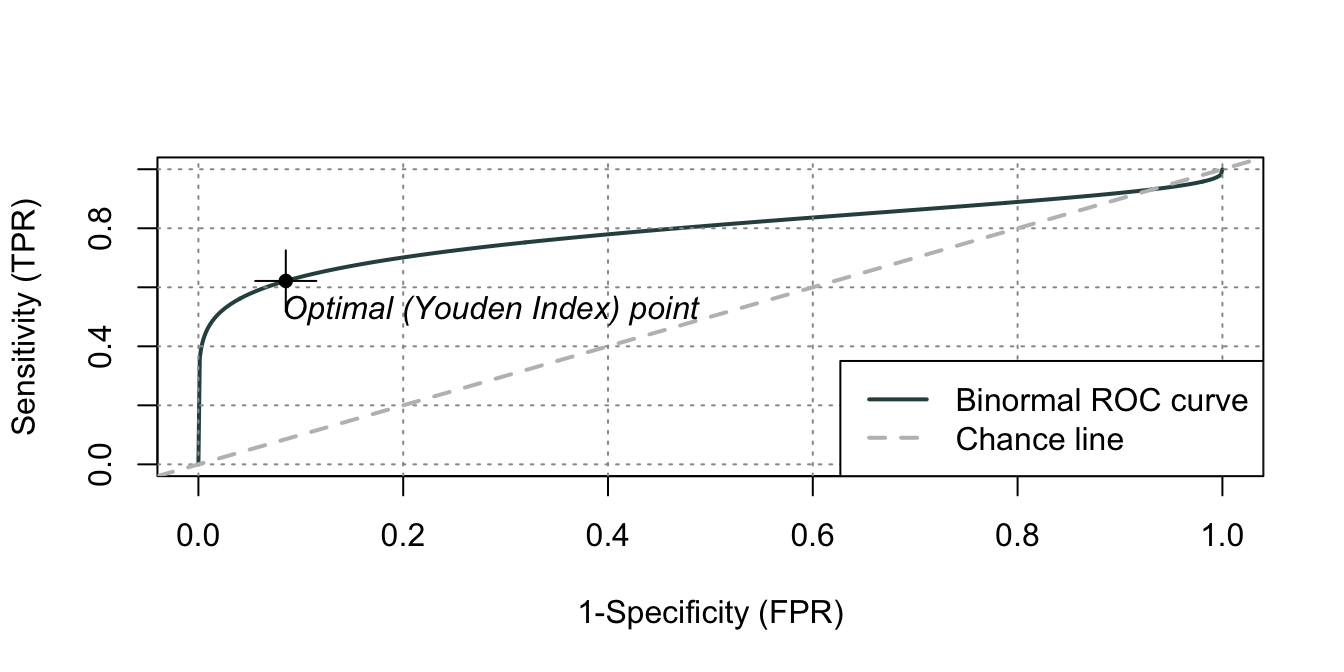
El área bajo la curva para esta ROC (el AUC) se puede obtener con la función summary() aplicada al objeto que acabamos de crear.
##
## Method used: binormal
## Number of positive(s): 875
## Number of negative(s): 7363
## Area under curve: 0.7907Ahora calculemos la otra ROC (Ver Figura 4.2 y la respectiva AUC).
roc_modelo2 <- rocit(score = prob_pred_modelo2,
class = datos_dummies_eval$y, method = "bin")
summary(roc_modelo2 )##
## Method used: binormal
## Number of positive(s): 875
## Number of negative(s): 7363
## Area under curve: 0.7907Figura 4.2: Curva ROC para el modelo 2

Noten que el mejor modelo según esto es el modelo2 que tiene la AUC más alta. Ahora procedamos a escoger el mejor punto de corte para cada uno de los modelos y calculemos las métricas para cada uno de los modelos con su respectivo valor de corte óptimo.
4.3.3 Selección del valor de corte óptimo en R
Como se discutió anteriormente, podemos emplear el Índice de Youden (Youden, 1950) (\(J\)) para detectar el valor de corte óptimo. Recuerden que
\[\begin{equation*} J = TPR + TNR -1 \end{equation*}\] Entonces, para construir \(J\) para todos los posibles \(\lambda\) podemos emplear la función measureit() del paquete ROCit (Khan & Brandenburger, 2020). La función típicamente incluye los siguientes argumentos:donde:
- score Un vector que contiene las probabilidades pronosticadas para cada uno de los individuos (\(h_{\hat\beta}(\mathbf{x}_i)\)).
- class Un vector con los positivos y negativos observados para cada individuo (\(y_i\)).
- measure Las métricas que se quieren calcular. Las opciones son: “ACC”, “SENS” (Sensibilidad también se puede usar “REC” por Recall), “SPEC” (Especificidad), “PREC” (Precisión), “TPR”, “FPR”, “TNR”, ” “FNR” y “FSCR” (Puntaje \(F_1\)).
En este caso las métricas de la muestra de entrenamiento para los dos modelos y diferentes valores de \(\lambda\) se pueden calcular de la siguiente manera:
metricas_modelo1 <- measureit(score = modelo1$fitted.values,
class = datos_est$y,
measure = c("SENS", "SPEC", "PREC", "NPV", "ACC", "FSCR", "FPR"))
metricas_modelo2 <- measureit(score = modelo2$fitted.values,
class = datos_est$y,
measure = c("SENS", "SPEC", "PREC", "NPV", "ACC", "FSCR", "FPR"))Ahora, de los objetos que construimos podemos extraer las métricas que necesitamos para encontrar \(J\) y su máximo. Y adicionalmente extraer el correspondiente valor de corte (Cutoff en inglés). De la siguiente manera encontramos el valor de corte óptimo.
#valor de corte máximo para el modelo 1
opt_pos_modelo1 <- which.max(metricas_modelo1$SENS + metricas_modelo1$SPEC -1)
v_corte_modelo1 <- metricas_modelo1$Cutoff[opt_pos_modelo1]
v_corte_modelo1## [1] 0.1149316#valor de corte máximo para el modelo 2
opt_pos_modelo2 <- which.max(metricas_modelo2$SENS + metricas_modelo2$SPEC -1)
v_corte_modelo2 <- metricas_modelo2$Cutoff[opt_pos_modelo2 ]
v_corte_modelo2 ## [1] 0.1327713Con este valor de corte podemos proceder a determinar las métricas basadas en la “exactitud” del pronóstico.
4.3.4 Métricas basadas en la “exactitud” del pronóstico en R
Vamos a construir las métricas con el mejor punto de corte para cada modelo, para calcular la matriz de confusión y las métricas podemos emplear la función confusionMatrix() del paquete caret (Kuhn & Max, 2008). Esta función solo necesita los positivos y negativos que el modelo predice y los observados. Así mismo, es importante especificar cuál es la categoría positiva con el argumento positive.
# predicción de positivos y negativos
pred_modelo1 <- ifelse( prob_pred_modelo1 > v_corte_modelo1, "yes", "no")
pred_modelo1 <- as.factor(pred_modelo1)
# Cargar paquete
library(caret)
mo_logit_1 <- confusionMatrix(pred_modelo1, datos_eval$y, positive = "yes")
Metrica_modelo1 <- cbind(mo_logit_1$byClass[1],
mo_logit_1$byClass[3],
mo_logit_1$byClass[5],
mo_logit_1$byClass[4],
mo_logit_1$overall[1])
# predicción de positivos y negativos
pred_modelo2 <- ifelse( prob_pred_modelo2 > v_corte_modelo2, "yes", "no")
pred_modelo2 <- as.factor(pred_modelo2)
mo_logit_2 <- confusionMatrix(pred_modelo2, datos_eval$y, positive = "yes")
Metrica_modelo2 <- cbind(mo_logit_2$byClass[1],
mo_logit_2$byClass[3],
mo_logit_2$byClass[5],
mo_logit_2$byClass[4],
mo_logit_2$overall[1])
tabla <- rbind(Metrica_modelo1,Metrica_modelo2)
tabla <- as.data.frame(tabla)
row.names(tabla) <- c("Modelo 1","Modelo 2")
names(tabla) <- c("SENS", "SPEC", "PREC", "NPV", "ACC")En el Cuadro 4.1 se presentan los resultados de las métricas. Se puede observar que el modelo 2 tiene una sensibilidad mayor que el modelo 1. Al tiempo, el valor negativo predictivo (\(NPV\)) es mayor en el modelo 2. El modelo 1 tiene una mejor accuracy (exactitud). Noten que no es tan fácil decidir basándonos en estas métricas, pues como sabemos existe un compromiso entre estas. En este caso, parece que el modelo 2 es mejor. Pero escoger entre los modelos no es tarea fácil. Esta decisión, al final tendrá que ser una decisión de negocio, pues cada negocio puede determinar que es más deseable para su caso. Por ejemplo, en este caso no parece delicado si se espera que un cliente adquiera el producto y no lo adquiera, pero sería algo más delicado que tengamos potenciales compradores del producto financiero que no se encuentren. En este caso, el modelo 2 podría ser algo mejor, seguiremos trabajando con este.
| SENS | SPEC | PREC | NPV | ACC | |
|---|---|---|---|---|---|
| Modelo 1 | 0.633 | 0.338 | 0.338 | 0.951 | 0.829 |
| Modelo 2 | 0.618 | 0.366 | 0.366 | 0.951 | 0.846 |
| Fuente: elaboración propia. |
4.3.5 Matriz de confusión
Ahora calculemos la matriz de confusión del modelo2.
# Cargar paquete
library(caret)
# Matriz de confusión
confusionMatrix(pred_modelo2, datos_dummies_eval$y, positive = "yes") ## Confusion Matrix and Statistics
##
## Reference
## Prediction no yes
## no 6427 334
## yes 936 541
##
## Accuracy : 0.8458
## 95% CI : (0.8379, 0.8536)
## No Information Rate : 0.8938
## P-Value [Acc > NIR] : 1
##
## Kappa : 0.3769
##
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.61829
## Specificity : 0.87288
## Pos Pred Value : 0.36628
## Neg Pred Value : 0.95060
## Prevalence : 0.10622
## Detection Rate : 0.06567
## Detection Prevalence : 0.17929
## Balanced Accuracy : 0.74558
##
## 'Positive' Class : yes
## Esta matriz de confusión refleja lo ya discutido. Noten que aquí podemos ver que el modelo no es tan bueno como pensábamos. En nuestro caso, el modelo predice correctamente 809 clientes que tomarían el producto financiero y 1196 incorrectamente. Pero el modelo es bueno pronosticando los que no lo tomarían, solo clasifica 66 clientes erróneamente, es decir predice que no tomarán el producto cuando si lo toman.
Finalmente, recuerde que todas las predicciones de la clasificación se encuentran en el objeto pred_modelo2. Una vez seleccionado el mejor modelo y adaptado este al negocio, podemos emplear todos los datos para estimar de nuevo el mejor modelo y tenerlo listo para datos de nuevos clientes que van llegando para predecir si estos tomarán o no el producto financiero.
4.4 Interpretación de los resultados del modelo Logit
Los coeficientes \(\beta\) no tienen interpretación directa. Lo único que podemos hacer con ellos, sin ningún cálculo adicional es determinar el signo del efecto de la variable sobre la probabilidad de observar un positivo.
Para encontrar una interpretación, es importante calcular el efecto marginal promedio de cada variable. Es decir: \[\begin{equation*} \frac{{\partial E\left[ {{{{y}}_{\bf{i}}}\left| {{\beta ^T}{{\mathbf{x}}}_{\bf{i}}^{\bf{T}}} \right.} \right]}}{{\partial {{{\mathbf{x}}}_{{\bf{j,i}}}}}} = \Lambda \left( {{\beta ^T}{{\mathbf{x}}}_{\bf{i}}^{\bf{T}}} \right)\left[ {1 - \Lambda \left( {{\beta ^T}{{\mathbf{x}}}_{\bf{i}}^{\bf{T}}} \right)} \right]{\beta _j} = \left( {\frac{{{e^{{\beta ^T}{{\mathbf{x}}}_{\bf{i}}^{\bf{T}}}}}}{{1 + {e^{{\beta ^T}{{\mathbf{x}}}_{\bf{i}}^{\bf{T}}}}}}} \right)\left[ {1 - \left( {\frac{{{e^{{\beta ^T}{{\mathbf{x}}}_{\bf{i}}^{\bf{T}}}}}}{{1 + {e^{{\beta ^T}{{\mathbf{x}}}_{\bf{i}}^{\bf{T}}}}}}} \right)} \right] \cdot {\beta _j} \end{equation*}\] donde \(i = 1,2,...n\) y \(j = 1,2,...k\). Este efecto marginal se puede calcular en las medias de las variables explicativas o se evalúa para cada individuo y se calcula su promedio. La segunda aproximación es más común en la actualidad.
Esto se puede hacer fácilmente en R empleando la función logitmfx() del paquete mfx (Fernihough, 2019). Esta función solo necesita tres argumentos, la fórmula del modelo, los datos y si se desea calcular el efecto marginal en la media de las variables explicativas (atmean = TRUE) o el promedio de los efectos marginales de todos los individuos (atmean = FALSE). En este caso:
# Cargar paquete
library(mfx)
# Calcular los efectos marginales
efectos_marginales <- logitmfx(modelo2$formula,
data = datos_dummies_est, atmean = F)## Call:
## logitmfx(formula = modelo2$formula, data = datos_dummies_est,
## atmean = F)
##
## Marginal Effects:
## dF/dx Std. Err. z P>|z|
## euribor3m 0.03199342 0.00645217 4.9586 7.102e-07 ***
## poutcomenonexistent 0.04030968 0.00581560 6.9313 4.170e-12 ***
## poutcomesuccess 0.22401550 0.01607660 13.9343 < 2.2e-16 ***
## mon_may -0.04058915 0.00437328 -9.2812 < 2.2e-16 ***
## mon_mar 0.14846388 0.01711968 8.6721 < 2.2e-16 ***
## cons_price_idx 0.12065602 0.00854030 14.1278 < 2.2e-16 ***
## cons_conf_idx 0.00141552 0.00038878 3.6409 0.0002717 ***
## c_telephone -0.04939945 0.00470832 -10.4919 < 2.2e-16 ***
## emp_var_rate -0.10012371 0.00885917 -11.3017 < 2.2e-16 ***
## d_mon -0.01727206 0.00405349 -4.2610 2.035e-05 ***
## mon_nov -0.04416916 0.00493625 -8.9479 < 2.2e-16 ***
## mon_jun -0.03752536 0.00538670 -6.9663 3.254e-12 ***
## campaign -0.00402372 0.00082672 -4.8671 1.133e-06 ***
## def_unknown -0.02036516 0.00450572 -4.5198 6.189e-06 ***
## j_blue_collar -0.01208323 0.00449583 -2.6877 0.0071956 **
## mon_aug 0.01801637 0.00736639 2.4458 0.0144550 *
## j_retired 0.02472478 0.00735297 3.3626 0.0007722 ***
## j_student 0.02646280 0.00923536 2.8654 0.0041651 **
## mon_oct -0.02127139 0.00714989 -2.9751 0.0029292 **
## d_wed 0.01295586 0.00449533 2.8821 0.0039507 **
## e_university_degree 0.00576099 0.00371856 1.5493 0.1213210
## previous 0.00906205 0.00469484 1.9302 0.0535803 .
## d_thu 0.00640267 0.00425693 1.5041 0.1325666
## j_services -0.00887494 0.00577531 -1.5367 0.1243659
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## dF/dx is for discrete change for the following variables:
##
## [1] "poutcomenonexistent" "poutcomesuccess" "mon_may"
## [4] "mon_mar" "c_telephone" "d_mon"
## [7] "mon_nov" "mon_jun" "def_unknown"
## [10] "j_blue_collar" "mon_aug" "j_retired"
## [13] "j_student" "mon_oct" "d_wed"
## [16] "e_university_degree" "d_thu" "j_services"Una forma opcional de obtener los efectos marginales y de visualizarlos es el paquete margins (Leeper, 2021). Con la función margins() podemos calcular los efectos marginales; no obstante, solo nos permite obtener los efectos marginales en la media de las variables explicativas. Esta función requiere dos argumentos principalmente, el primero el objeto con el modelo, y type, para indicar el tipo de efecto marginal a estimar, en nuestro caso es “response”. Veamos un ejemplo:
## factor AME SE z p lower upper
## c_telephone -0.0525 0.0053 -9.9410 0.0000 -0.0628 -0.0421
## campaign -0.0040 0.0008 -4.8810 0.0000 -0.0056 -0.0024
## cons_conf_idx 0.0014 0.0004 3.6631 0.0002 0.0007 0.0022
## cons_price_idx 0.1207 0.0081 14.9869 0.0000 0.1049 0.1364
## d_mon -0.0179 0.0044 -4.0968 0.0000 -0.0265 -0.0094
## d_thu 0.0063 0.0041 1.5235 0.1276 -0.0018 0.0145
## d_wed 0.0126 0.0043 2.9602 0.0031 0.0043 0.0210
## def_unknown -0.0214 0.0050 -4.2906 0.0000 -0.0311 -0.0116
## e_university_degree 0.0057 0.0037 1.5619 0.1183 -0.0015 0.0129
## emp_var_rate -0.1001 0.0086 -11.7004 0.0000 -0.1169 -0.0834
## euribor3m 0.0320 0.0064 4.9986 0.0000 0.0194 0.0445
## j_blue_collar -0.0124 0.0047 -2.6206 0.0088 -0.0216 -0.0031
## j_retired 0.0229 0.0063 3.6234 0.0003 0.0105 0.0353
## j_services -0.0091 0.0061 -1.4959 0.1347 -0.0211 0.0028
## j_student 0.0243 0.0078 3.1086 0.0019 0.0090 0.0396
## mon_aug 0.0172 0.0067 2.5589 0.0105 0.0040 0.0304
## mon_jun -0.0420 0.0068 -6.2065 0.0000 -0.0552 -0.0287
## mon_mar 0.1035 0.0088 11.7353 0.0000 0.0862 0.1208
## mon_may -0.0422 0.0047 -8.9003 0.0000 -0.0515 -0.0329
## mon_nov -0.0509 0.0066 -7.6948 0.0000 -0.0639 -0.0379
## mon_oct -0.0231 0.0084 -2.7362 0.0062 -0.0396 -0.0065
## poutcomenonexistent 0.0408 0.0060 6.8215 0.0000 0.0291 0.0525
## poutcomesuccess 0.1734 0.0137 12.6366 0.0000 0.1465 0.2003
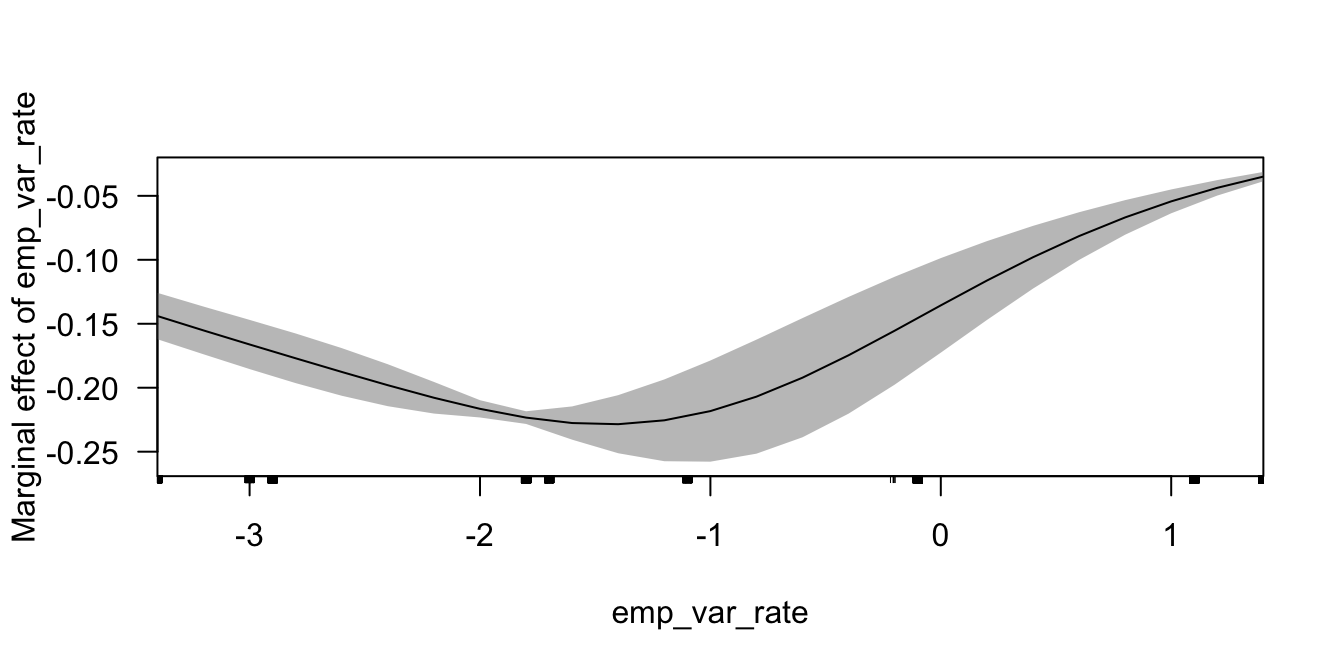
## previous 0.0091 0.0047 1.9322 0.0533 -0.0001 0.0183Como podemos observar, los efectos marginales varían levemente. Para visualizar los efectos marginales podemos usar la función cplot() también del paquete margins (Leeper, 2021). Esta función necesita de tres argumentos, el primero, al igual que en la función margins(), es el objeto que contiene el modelo; el segundo x es el nombre de la variable de la cual queremos visualizar los efectos marginales y el tercero what se refiere a sí queremos visualizar los efectos marginales o los valores predichos para ciertos valores de la variable, en nuestro caso what=“effect”. En la Figura 4.3 se presenta el efecto marginal para la variable emp_var_rate y el área sombreada indica los respectivos intervalos de confianza al 95%.
Figura 4.3: Efecto marginal de la variable seleccionada
Finalmente, guarda el espacio de trabajo para ser empleado en los siguientes capítulos.
4.5 Comentarios Finales
Antes de terminar es importante decir que la mayoría de los métodos de inferencia usados para el modelo de regresión lineal también aplican para el modelo Logit, como por ejemplo, probar cualquier tipo de restricción lineal de la forma \(R\beta = C\) por medio de la prueba de Wald.
En este capítulo hemos discutido cómo evaluar e interpretar los resultados de modelos Logit. En los próximos capítulos estudiaremos otros modelos estadísticos, así como también métodos de aprendizaje de máquinas, que permiten realizar la tarea de clasificación. Este modelo estadístico hace parte de la caja de herramientas para resolver problemas de clasificación en los negocios. A priori, es imposible saber si este método será mejor que los de aprendizaje de máquina y por eso es común que se empleen diferentes aproximaciones y se comparen.
Las aplicaciones de estos métodos de clasificación son muchas en el mundo de los negocios y definitivamente estos modelos son necesarios en la caja de herramientas de un científico de datos.