1 Generalidades de la tarea de clasificación
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras qué es la tarea de clasificación
- Explicar en sus propias palabras qué tipos de analítica puede realizar la tarea de clasificación
1.1 Introducción
En los últimos años se ha acelerado la transformación del mundo de los negocios por la disponibilidad de mayores volúmenes de datos y capacidad de computo que permiten emplear modelos de analítica para responder preguntas de negocio y así generar valor a las organizaciones (Alonso, 2024). Emplear herramientas de Business Analytics y Big Data permiten tanto optimizar los procesos actuales como generar características diferenciadoras para cada organización.
Los datos se han convertido en un recurso estratégico para las organizaciones, y el business analitycs es la herramienta mediante la cual, las organizaciones pueden monetizar ese recurso (Alonso, 2024). El business analitycs es el proceso científico de transformar datos en insights con el propósito de tomar mejores decisiones (Alonso, 2024).
Las tareas del business analitycs implican la necesidad de escoger la mejor herramienta para responder la pregunta de negocio planteada. Las respuestas a las preguntas de negocio implican diferentes tareas que se pueden clasificar en una de las siguientes categorías:
- Resumir
- Visualizar
- Clusterizar (Agrupar)
- Clasificar
- Detectar excepciones
- Encontrar reglas de asociación (o buscar coocurrencia de productos)3
- Pronosticar
- Estimar regresiones4
La tarea de Clasificación tiene como finalidad construir un modelo que permita predecir la categoría de un individuo o un objeto. En otras palabras, se emplea para categorizar o clasificar datos en diferentes grupos o clases. Esta tarea es útil para analizar conjuntos de datos para los cuáles queremos predecir la pertenencia a una categoría específica en función de ciertas características o atributos de los individuos.
Por ejemplo, en algunas situaciones se deseará determinar si un nuevo cliente comprará o no nuestro producto. En este caso, las categorías son compra o no compra. En la Figura 1.1 se presenta una representación gráfica de esta tarea.
Figura 1.1: Tarea de clasificación
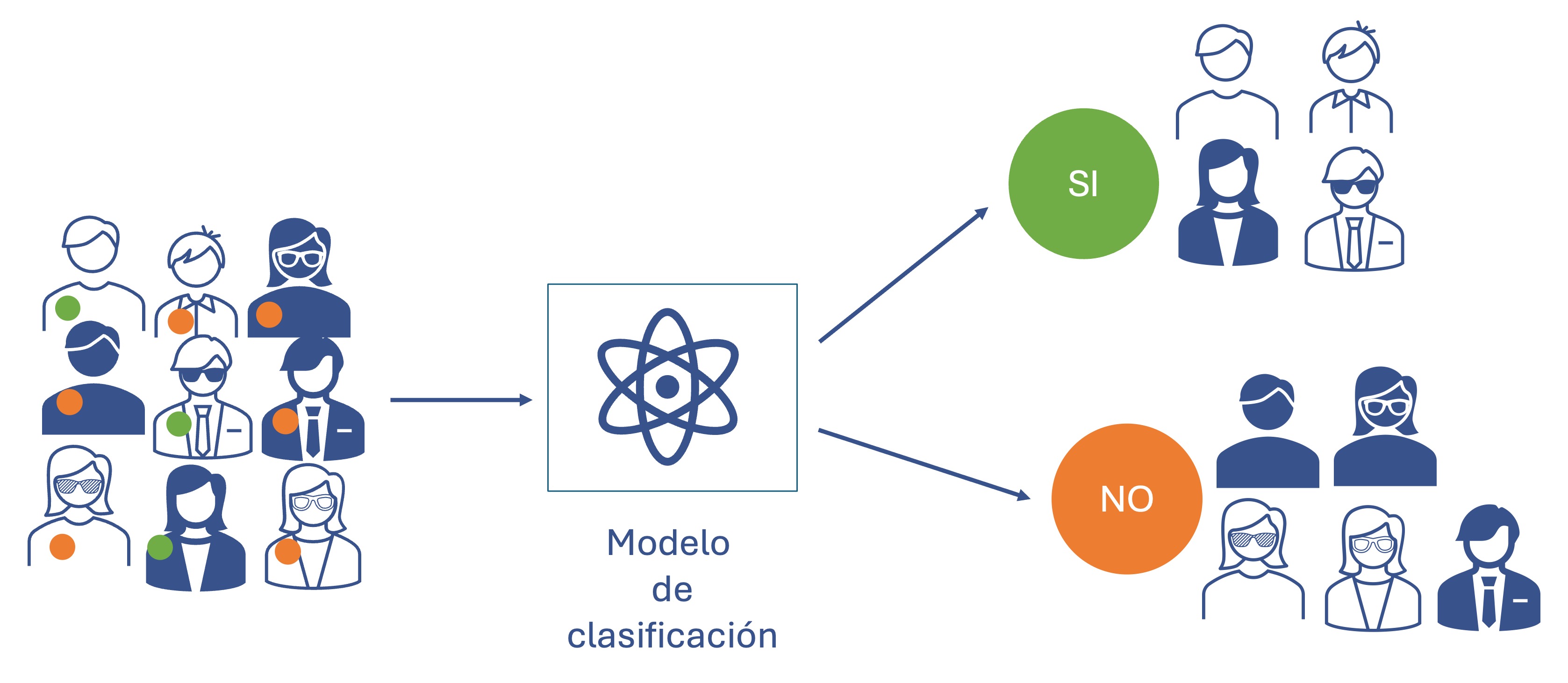
Figura 1.2: Material multimedia: tarea de clasificación

Más ejemplos de preguntas de negocio que se pueden responder con la tarea de clasificación son:
- ¿Cuáles clientes cancelarán su suscripción a nuestro servicio?
- ¿Qué clientes no pagarán sus facturas a tiempo?
- ¿Cuáles de los candidatos serán un buen “match” para la posición que está disponible?
- ¿Qué productos seran devueltos por los clientes?
- ¿Cuáles de los proyectos se completarán dentro del plazo establecido?
- ¿Qué clientes responderán comprando el producto tras recibir una oferta de descuento?
- ¿Qué clientes comprarán un producto complementario?
- ¿Cuáles leads5 se convertirán en clientes?
- ¿Qué clientes recomendarán nuestros productos o servicios a otros?
Como ya te debe quedar claro, la gama de preguntas de negocio que se pueden responder con la tarea de clasificación es muy grande.
Por otro lado, aunque suene raro, es importante anotar que la tarea de clasificación se realiza típicamete con modelos de clasificación como el modelo Logit (Ver Capítulo 3), el modelo clasificador bayesiano ingenuo o Naive Bayes en inglés (Ver Capítulo 5), el modelo kNN (Ver Capítulo 6), Árboles de decisión (Ver Capítulo 7), el modelo Random Forest (Ver Capítulo 8) y Suport Vector Machine o SVM (Ver Capítulo 9), entre otros. Esos modelos, en algunas ocasiones pueden ser empleados para hacer otro tipo de tarea de analítica. Por ejemplo, algunos modelos de clasificación pueden ser empleados para detectar excepciones; y más específico anomalías. Por ejemplo se puede emplear modelos de clasificación para responder la pregunta ¿es esta operación de tarjeta de crédito fraudulenta o no? Así, la tarea de clasificación se realiza con modelos de clasificación, sin embargo, los modelos de analítica pueden servir para hacer tareas diferentes a la clasificación.
Los modelos de clasificación se estiman o entrenan empleando una muestra de individuos6 para los cuales se cuenta con observaciones de las características de estos y su clasificación (variable objetivo). Así estos modelos corresponden a modelos de aprendizaje supervisado7, pues la muestra contiene la variable objetivo que se encuentra etiquetada con la característica bajo estudio8. La misión del modelo o algoritmo es aprender de esos datos cuál es el patrón que permitiría predecir la categoría (variable objetivo) de un individuo dadas las características de este.
Regresando a las tareas del business analytics, una manera más común de clasificar los ejercicios de analítica es según su propósito. En ese caso se tienen cuatro tipos de analítica (Ver Figura 1.3):
Analítica Descriptiva: Esta analítica se enfoca en resumir y visualizar los datos para obtener información sobre lo que ha sucedido en el pasado. Ayuda a comprender patrones y tendencias.
Analítica Diagnóstica: Esta analítica busca entender por qué algo ha sucedido. Examina los datos para identificar las causas raíz de los problemas o éxitos pasados.
Analítica Predictiva: Esta analítica utiliza modelos estadísticos y de aprendizaje de máquina para hacer pronósticos y predecir eventos futuros.
Analítica Prescriptiva: Esta analítica se centra en recomendar acciones y soluciones óptimas para lograr un objetivo.
Figura 1.3: Material multimedia: tipos de analítica

Estos cuatro tipos de analítica engloban las ocho tareas del business analytics. La tarea de clasificación permite realizar analítica diagnóstica, descriptiva y prescriptiva (Ver Figura 1.4).
Figura 1.4: Relación entre las tareas de analítica y los tipos de analítica
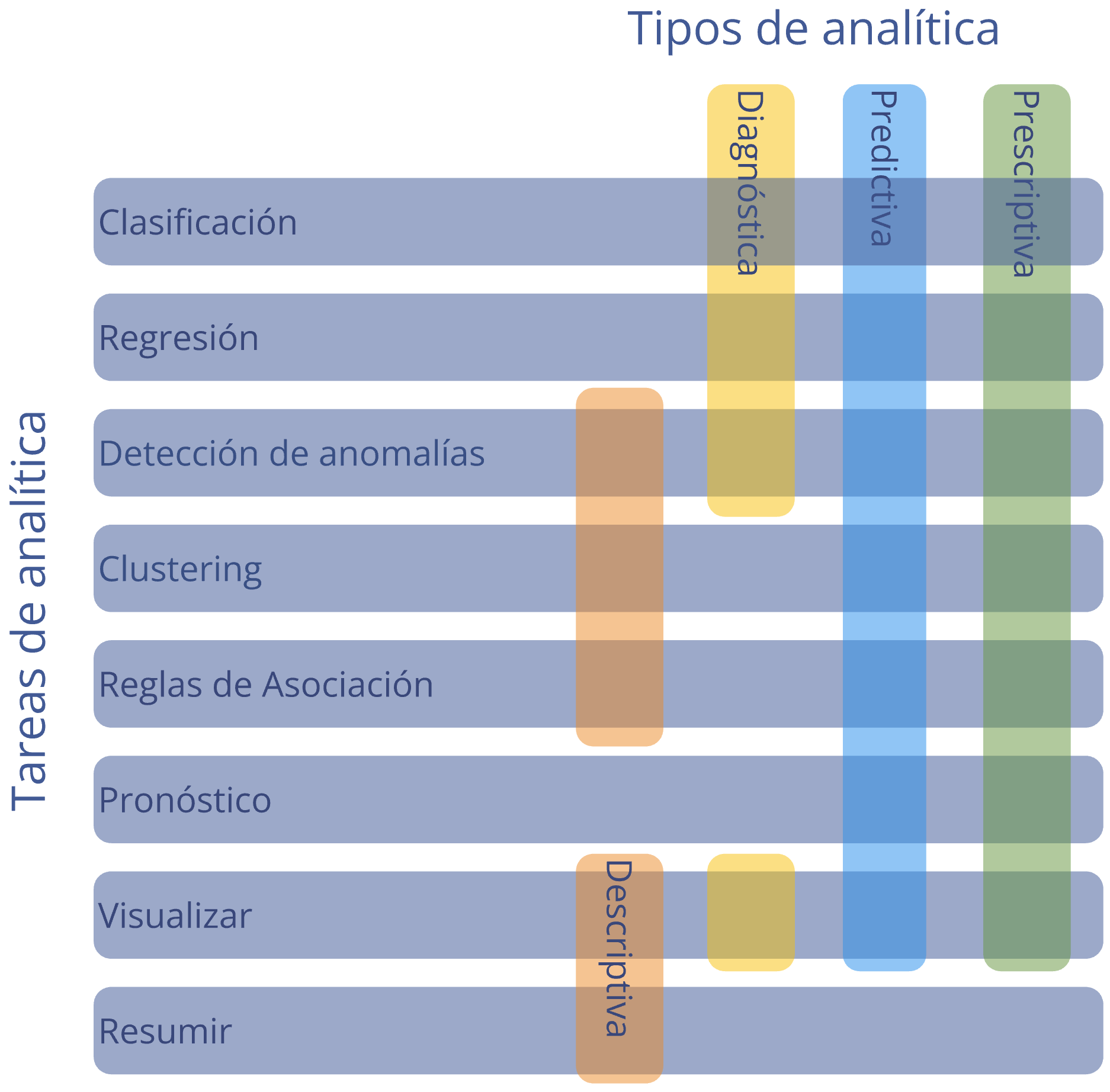
La analítica diagnóstica responde a la pregunta ¿por qué está pasando algo? En el contexto de las preguntas de clasificación, dependiendo de los modelos que se empleen, se podrá determinar por qué un individuo queda clasificado en una categoría u otra. Por ejemplo, supongamos que queremos responder la pregunta de negocio ¿qué variables son las más importantes para que un cliente siga siendo mi cliente en los próximos 6 meses? Esta pregunta implica una tarea de clasificación: clasificar a los clientes actuales entre aquellos que continuarán después de 6 meses y aquellos que no, dadas sus características. Los modelos de clasificación (como el modelo Logit que será discutido en el Capítulo 3) pueden determinar cuáles variables son importantes al momento de determinar si un cliente dejará de ser mi cliente y cuáles no. Y para un determinado individuo podremos saber el porqué de su no continuidad; es decir, cuáles variables pesaron más en ese individuo para no continuar como cliente.
La analítica predictiva busca responder la pregunta: ¿Qué es posible que ocurra?. Los modelos de clasificación podrán determinar que categoría probablemente tendrá un individuo dadas sus características. Por ejemplo, supongamos que una institución del sector financiero quiere responder la pregunta de negocio ¿me pagará este individuo si le otorgo un crédito de libre inversión? En ese caso, un modelo de clasificación podrá clasificar a un individuo, dadas sus características, entre las categorías si pagará y no pagará. Así, el modelo permite predecir el comportamiento que tendrá ese individuo.
La analítica prescriptiva busca responder la pregunta: ¿qué necesito hacer? Los modelos de clasificación nos permiten hacer este tipo de analítica al sugerir qué deberíamos hacer en algunas situaciones. Por ejemplo, un negocio quisiera responder a la pregunta ¿cuáles variables accionables9 puedo manipular para lograr que un cliente me compre un producto adicional? En ese caso, el modelo de clasificación nos podrá sugerir qué hacer para lograr el objetivo.
1.2 Comentarios Finales
Los modelos de clasificación no solamente responden a preguntas que impliquen que los individuos u objetos sean clasificados en dos categorías, las categorías pueden ser relativamente muchas. De hecho, los problemas de clasificación pueden ser menos tradicionales, como clasificar una imagen. Por ejemplo, para que un carro autónomo pueda funcionar, tiene que clasificar (entender) las señales de tránsito que “observa”.
Si ya te es familiar los modelos de regresión múltiple10, te parecerá que los modelos de clasificación se parecen en parte, pues se trata de emplear diferentes variables independientes (características de los individuos) para explicar una variable objetivo. Pero se diferencia de los modelos de regresión en que la variable dependiente de estos modelos es una variable cualitativa que toma relativamente pocos valores (Por ejemplo, compra o no compra o pagará o no pagará), mientras que la variable dependiente de los modelos de regresión corresponden a una variable cuantitativa continua o discreta.
Los modelos de clasificación que se emplean en el business analitycs tienen dos orígenes: modelos estadísticos y modelos de aprendizaje de máquina11. En este libro nos concentraremos en diferentes modelos que hacen parte de los dos campos mencionados anteriormente.
En el los Capítulos 3 y 5 estudiaremos los modelos Logit y clasificador bayesiano ingenuo (Naive Bayes) que tienen un origen estadístico. Por otro lado, en los Capítulos 6 a 9 estudiaremos modelos machine learning como el modelo kNN, Árboles de decisión, el modelo Random Forest y Suport Vector Machine. Para cada uno de estos modelos, se aborda la parte formal del modelo junto con una aplicación en R (R Core Team, 2023).
Antes de iniciar a estudiar los diferentes modelos de clasificación que estudiaremos, es importante concentrar la atención sobre cómo determinar si un modelo es un buen modelo de clasificación. Eso lo estudiaremos en el Capítulo 2.
Referencias
Para una discusión detallada de esta tarea y cómo implementarla en R se puede consular Alonso & Arboleda (2025).↩︎
Para una discusión detallada del modelo clásico de regresión y cómo implementarlo en R se puede consultar Alonso (2024).↩︎
En este contexto, los leads son los posibles clientes potenciales que han mostrado interés en el producto o servicio de una empresa. ↩︎
Típicamente para los modelos de clasificación se emplean muestras de corte transversal. Es decir, a muchos individuos se les observa sus características y la variable objetivo en el mismo período. ↩︎
En el campo del aprendizaje de máquina se distinguen dos tipos de aprendizaje: supervisado y no supervisado. En el aprendizaje no supervisado los datos no contienen etiquetas o la “respuesta correcta”. El aprendizaje no supervisado busca descubrir patrones o estructuras ocultas en los datos.↩︎
Es decir, con la respuesta correcta ya conocida.↩︎
Por una variable accionable en la jerga de los negocios, es aquella que le permite a la organización desarrollar estrategias y campañas que permitan el logro de un objetivo (Alonso, 2024).↩︎
Ver Alonso (2024) para una discusión amplia del modelo clásico de regresión.↩︎
También conocido como aprendizaje automático o aprendizaje automatizado. Este término viene del inglés machine learning.↩︎