9 Gráficos avanzados
En los Capítulos 3, 4 y 5 se discutieron tipos de gráficos (capa de Geometría) que generan visualizaciones de uso relativamente frecuente y sencillas de entender. Sin embargo, hay otras geometrías no tan comunes que pueden cumplir una mejor tarea en comunicar el mensaje, dependiendo del auditorio que se cuente y de la posibilidad de explicar cómo se debe interpretar la visualización.
Las visualizaciones que presentaremos en este capítulo representan un mayor reto a la hora de escribir las líneas de código. Por esta razón, creamos un capítulo especialmente dedicado a gráficos avanzados, para que tengas en cuenta otras posibilidades de mostrar los datos. Así mismo, estas visualizaciones probablemente no serán entendidas por todo tipo de auditorio si no se explica cómo funcionan. Estas visualizaciones son un gran reto, pero en algunas ocasiones podrán ser más potentes que las visualizaciones tradicionales.
Recuerda que la naturaleza de los datos y el tipo de público al que irá dirigida la visualización indicará qué tipo de visualización (capa de Geometría) es apropiada.
9.1 Gráficos avanzados de distribución
9.1.1 Lollipop
En la Figura 9.1 observamos una visualización conocida como lollipops41. Esta representa la distribución de países por continente para el año 2007, empleando la información del paquete gapminder (Bryan, 2017).
Figura 9.1: Distribución de los países por continente disponibles en los datos de gapminder para 2007
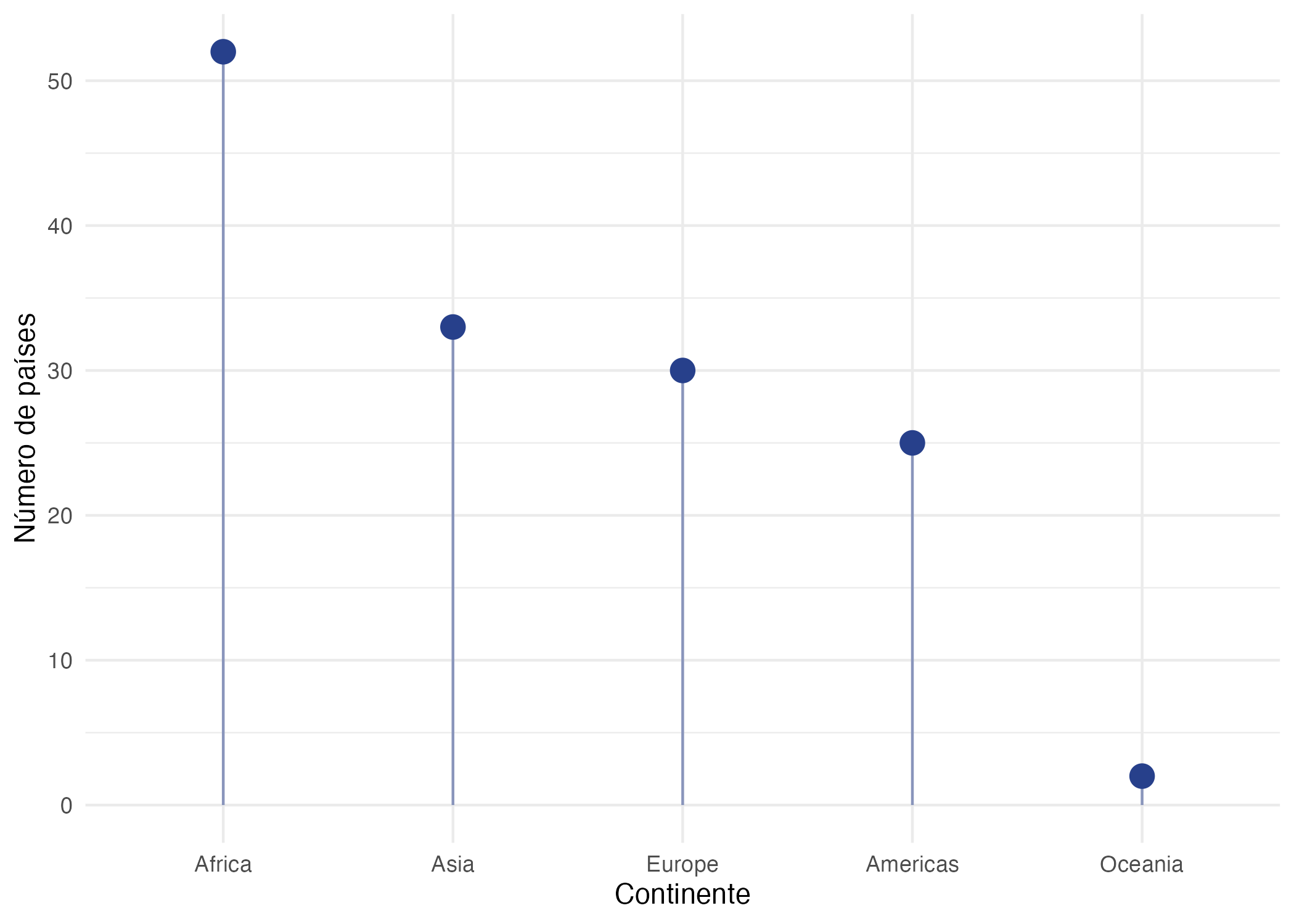
Esta visualización implica una línea “anclada” desde el eje horizontal y un punto al final (círculo) para marcar el valor. También se puede modificar la visualización para que la línea empiece en el eje vertical, como el caso de la Figura 9.2. Siguiendo nuestras recomendaciones para mejorar una visualización, también organizamos los datos.
Figura 9.2: Distribución de los países por continente disponibles en los datos de gapminder para 2007
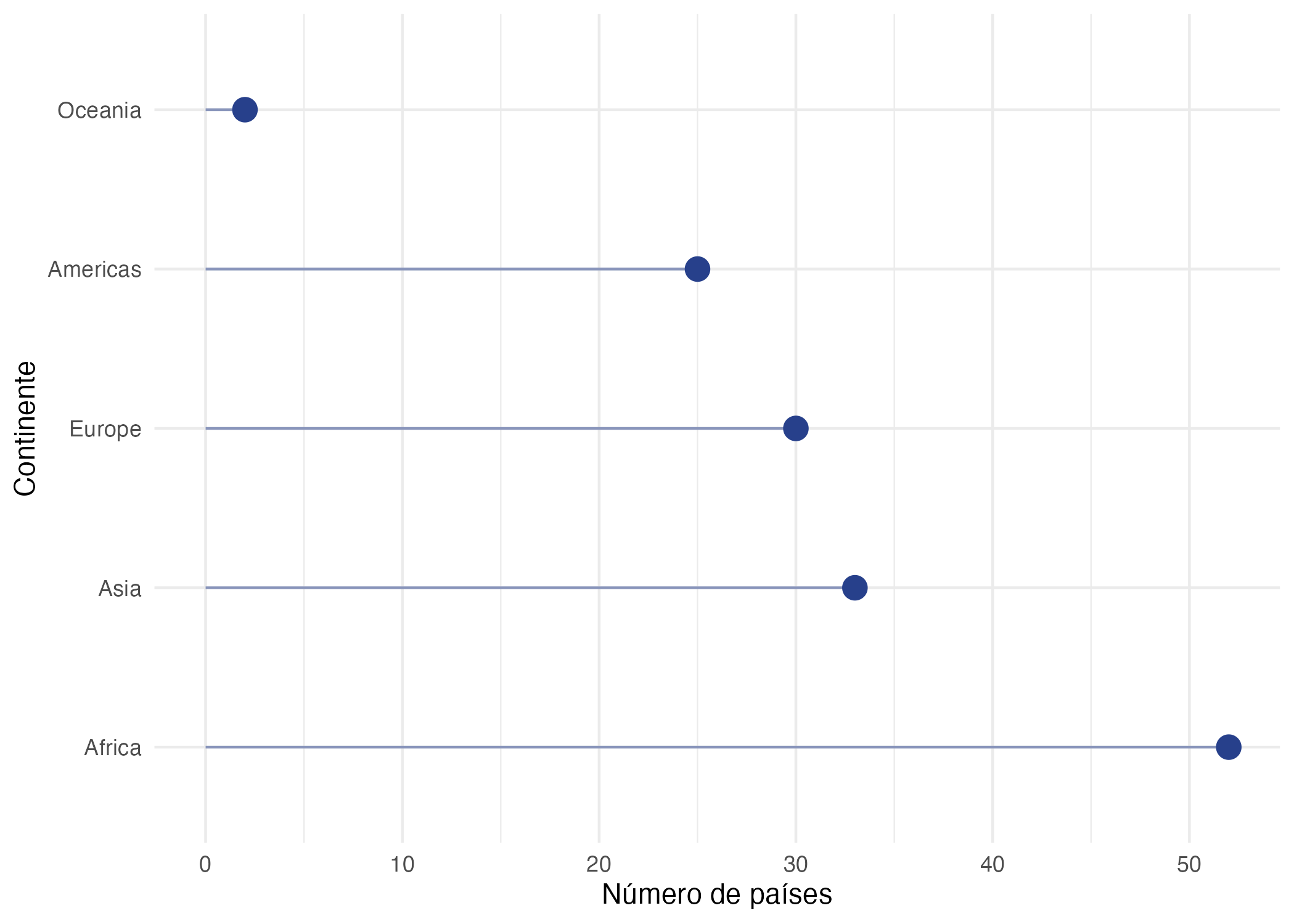
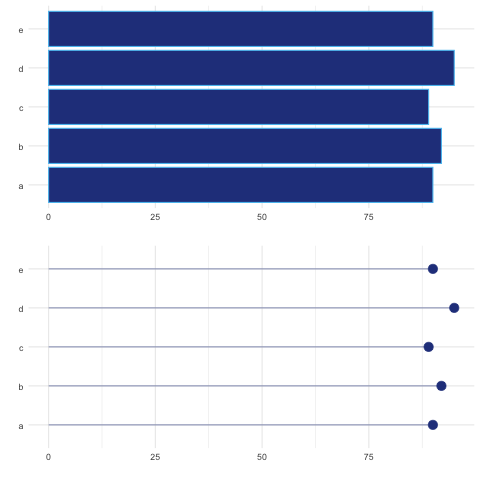
Esta visualización cumple la misma función del gráfico de barras que vimos en la sección 3.2 (ver Figura 3.3). La ventaja de este tipo de gráfica es que puede ser menos cargada que emplear barras, en especial si se trata de un gran número de observaciones que contienen valores altos; por ejemplo, en el rango de 80 a 90% (sobre 100%). Un gran conjunto de columnas altas puede resultar visualmente agresivo y los lollipops funcionarían mejor. La Figura 9.3 nos presenta un ejemplo de esto.
Figura 9.3: Ejemplo cuando funciona mejor un grafico de lolipops que uno de barras
Las visualizaciones de lollipops se pueden construir fácilmente con el paquete ggplot2, agregando dos capas específicas: los puntos y los segmentos. Para incluir los puntos utilizaremos la función geom_point(), mientras que los segmentos serán dibujados utilizando la función geom_segment(). Esta última función dibuja un segmento que va desde x hasta xend de forma horizontal y de y hasta yend de forma vertical. Estos argumentos son necesarios para que nuestra capa de geometría realice un gráfico de lollipops.
La Figura 9.1 se puede crear empleando el objeto gapminder del paquete con su mismo nombre, haciendo los siguientes pasos:
- Filtrar los datos para el año 200742.
- Agrupar las observaciones y contar cuántas observaciones hay por continente.43
- Crear la visualización con ggplot2 empleando una capa de Geometría de puntos y una capa de Geometría de segmentos.
Es decir, el código será el siguiente:
#Cargar los paquetes
library(ggplot2)
library(gapminder)
library(dplyr)
# se emplea el operador pipe para
# pasar y filtrar los datos
gapminder %>%
filter(year==2007) %>%
group_by(continent) %>%
count() %>%
ggplot(aes(x=continent, y=n)) +
# crear segmentos
geom_segment( aes(x=reorder(continent, -n),
xend=continent, y=0, yend=n),
color="royalblue4", alpha = 0.5) +
#crear puntos
geom_point(color="royalblue4", size=4) +
labs(y="Número de países",
x="Continente")+
theme_minimal()Sin embargo, utilizar este tipo de visualización tiene algunas desventajas. El centro del círculo del lollipop marca el valor, de la misma forma del borde recto en un gráfico de barras, pero no es fácil de determinar de forma precisa. Además, la mitad del círculo se extiende más allá del valor que representa, por lo que puede llevar a interpretaciones erradas de la variable que se está mostrando.
9.1.2 Violines
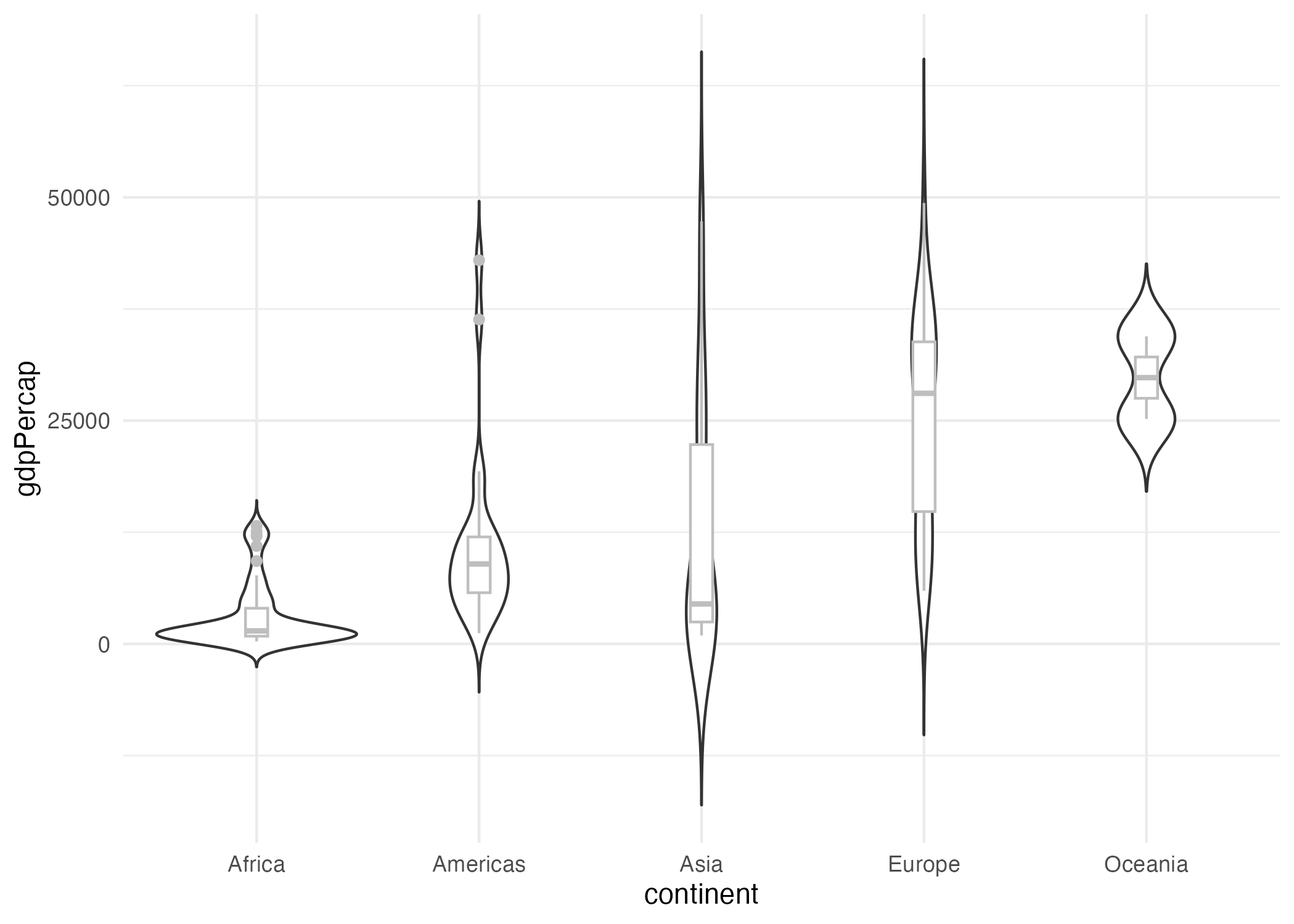
Otra forma de visualizar la distribución de una característica de una muestra (variable) es usando un gráfico de violines44 . Estos son una forma más sofisticada de Boxplot (diagrama de cajas) estudiado en la Sección 3.3. Esta visualización también es conocida como gráfico de densidad de espejo. La Figura 9.4 muestra un ejemplo de este tipo de gráficos.
En la Figura 9.4 podemos apreciar la distribución de la variable PIB per cápita para el año 2007 por continente. Las partes más anchas de los gráficos de violines representan los valores para los cuales hay más observaciones. Por otro lado, las partes más delgadas muestran los valores para los cuales hay menos observaciones (ver Figura 9.4). Para más información, puedes ver el siguiente video de 3 minutos.
En general, a pesar de que las estadísticas descriptivas, como la media, la mediana y la desviación estándar son fáciles de calcular, puede ser difícil hacernos una idea de cómo son todos los datos disponibles. En estos casos, es muy útil tener una gráfica de la distribución de los datos como un gráfico de violín.
El gráfico de violín se puede construir en ggplot2 empleando la capa de Geometría con ese nombre (en inglés): geom_violin(). Empleando el siguiente código, podemos obtener la Figura 9.4:
# cargar paquetes
library(ggplot2)
library(gapminder)
library(dplyr)
ggplot(gapminder %>%
filter(year==2007), aes(x=continent, y=gdpPercap))+
# incluir geometría de violín
geom_violin(trim=FALSE)+
theme_minimal()
Figura 9.4: Distribución del PIB per cápita por continente para 2007
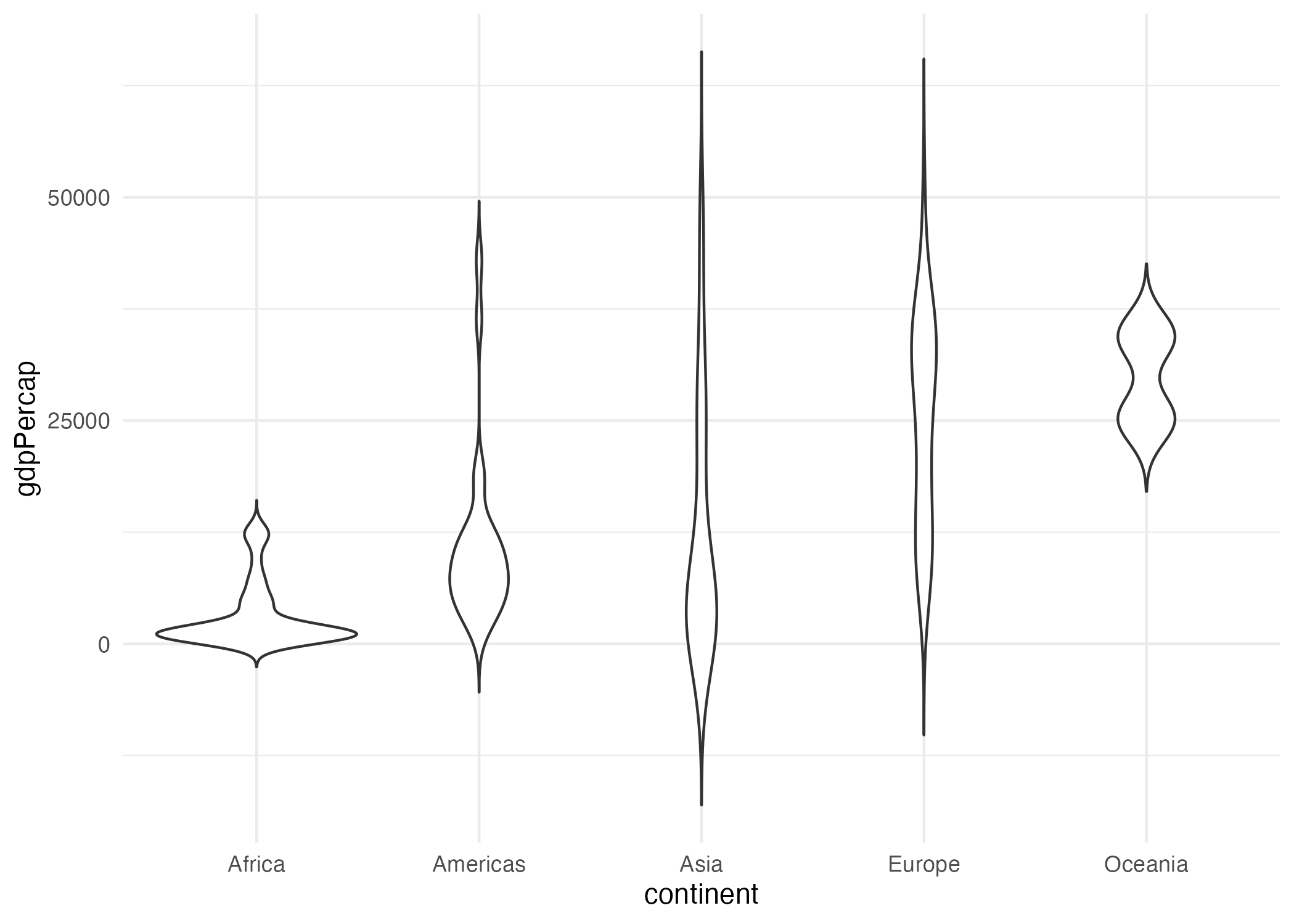
El argumento trim de la la función geom_violin() hace que la cola de los violines se “aplaste”, de forma que no quede cuadrada. Puedes jugar un poco haciendo caso omiso a este argumento.
A su vez, podemos ponerle más información a la gráfica. Agregando a la capa de Geometría la función geom_boxplot() podemos tener un Boxplot en la misma visualización. Así, obtendríamos la visualización de la Figura 9.5. Intenta crear esta visualización45.
Figura 9.5: Distribución del PIB per cápita por continente para 2007 según los datos de gapminder
9.1.3 Calendario (distribución en el tiempo)
En ocasiones, contamos con datos de una variable cuantitativa observada diariamente y tenemos la correspondiente fecha para cada observación (una serie de tiempo diaria). La aproximación tradicional es realizar un gráfico de líneas (ver Sección 4.1) para mostrar la evolución en el tiempo de la variable. Pero en algunos casos sería interesante ver cómo se distribuye la variable en los diferentes días. En esos casos un gráfico de Calendario podría ser apropiado para mostrar los datos. El objetivo de este tipo de visualizaciones es mostrar los días en los que más observaciones hay, empleando una escala de colores para mostrar las observaciones por día. Es común que el día con más observaciones (o el valor a mapear es el mayor) se le asigne el color mas fuerte.
La Figura 9.6 muestra un ejemplo de este tipo de visualizaciones. Aquí, se muestra el número de visitas que hicieron los estudiantes de un curso virtual a la plataforma donde eran evaluados. El curso tenía una duración de seis semanas. Cada una de estas correspondía a un módulo, el cual concluía con un cuestionario. Los estudiantes tenían de jueves a jueves para acceder y realizar la evaluación correspondiente de la semana.
Figura 9.6: Número de visitas a la plataforma por día
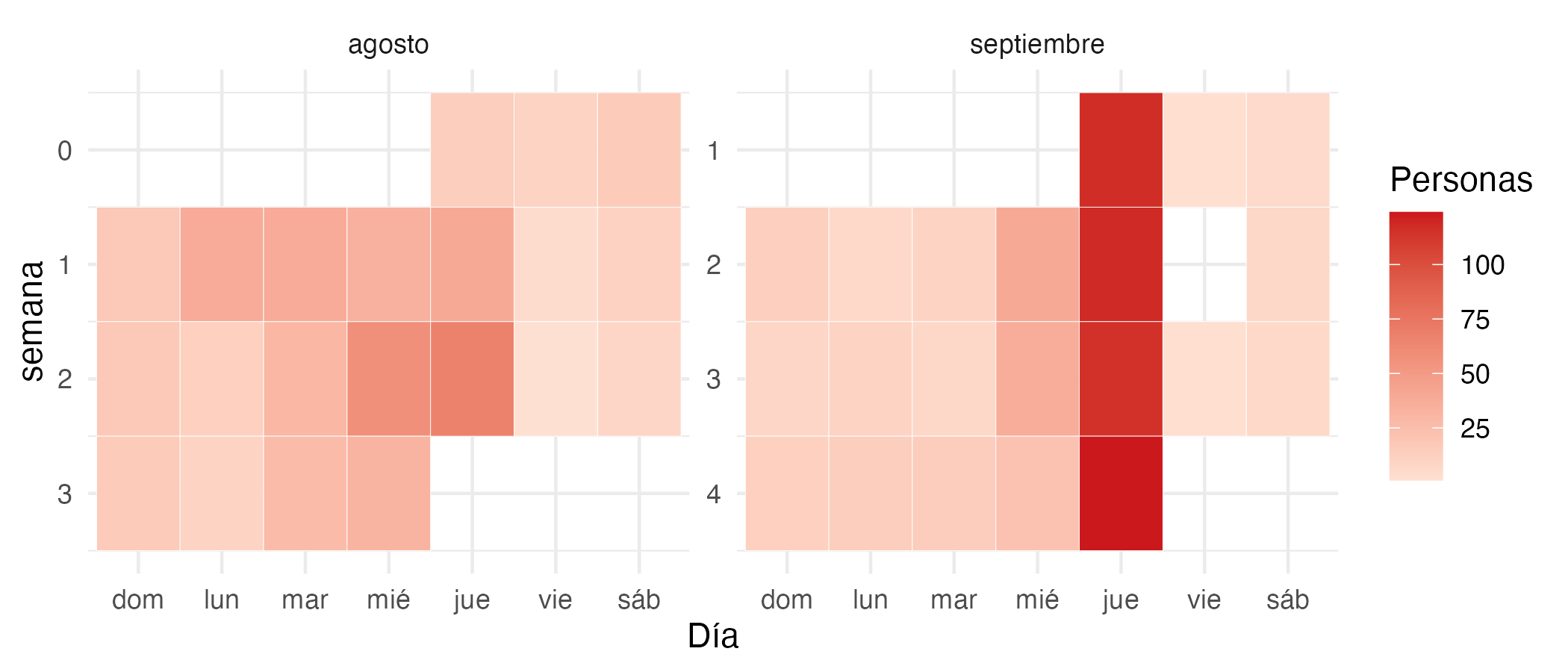
Es fácil apreciar, por la intensidad del color, que los días jueves fueron en que más visitas tuvo la plataforma; relacionado con el último día en el que estaba la disponible la actividad de la semana.
Este gráfico es fácil de replicar. Sin embargo, hay que tener en cuenta que los datos deben tener el formato adecuado. Hemos dispuesto el archivo calendario.RData para que puedas ver cómo funciona el código y la estructura que deben tener los datos. En el archivo, hay guardado un objeto con el nombre de calendario. Este tiene cuatro variables correspondientes al día, semana, número de estudiantes y mes. Puedes comprobar fácilmente con la función str() (R Core Team, 2018) que la clase de las variables semanadia y mes_texto es factor, con sus respectivos niveles asignados46. Este paso es importante, pues determinará el orden en que se visualizarán los meses y los días en nuestra visualización.
A continuación, usamos la función ggplot() para iniciar nuestro gráfico. La capa de Geometría que llamaremos es la función geom_tile(). El eje x corresponderá al día y el eje y al número de la semana. El argumento fill, que determina la variable que coloreará cada día, será el número de estudiantes. La capa de Facets la modificaremos usando la función facet_wrap(), donde especificamos la variable para dividir los gráficos después del operador virgulilla (~). Por defecto, el orden de la variable semana será determinado de menor a mayor. Para cambiar esto, modificamos la capa de Escalas con la función scale_y_reverse(), la cual invierte el orden del eje.
Una función opcional que empleamos para personalizar nuestra visualización es scale_fill_gradient(), que cambia la capa de Escalas. Esta nos permite elegir los colores de los valores altos y bajos del fill con los argumentos high y low respectivamente. Para cambiar el nombre de los ejes y leyendas, llamamos a la función labs(). Puedes jugar un poco con las funciones y argumentos para cambiar los resultados a tu gusto. Los datos necesarios los puedes descargar en la página Web del libro.
# cargar paquetes
library(ggplot2)
library(dplyr)
# cargar los datos
load("./09-avanz/calendario.RData")
ggplot(calendario, aes(x = semanadia, y = semana)) +
geom_tile(aes(fill = n), colour = "white") +
facet_wrap(~mes_texto, scales = "free") +
scale_y_reverse() +
theme_minimal() +
scale_fill_gradient(low="#fee0d2",high="#cb181d")+
labs(fill="Personas", x="Día")9.2 Gráficos avanzados de evolución
9.2.1 Dumbbell
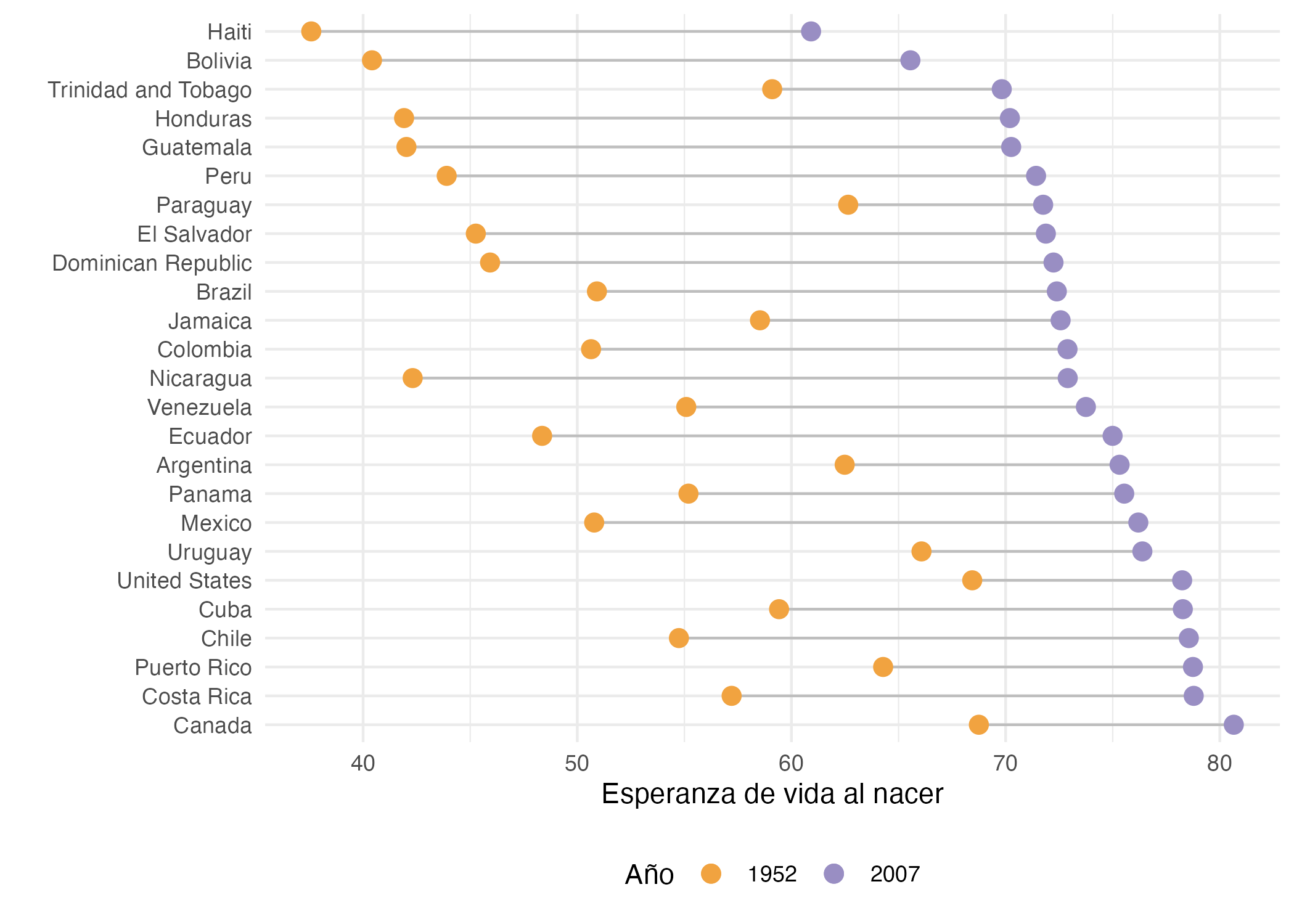
La Figura 9.7 nos presenta una visualización llamada dumbbell47. Este tipo de gráficas muestran la evolución de variables de clase numeric o integer.
A diferencia de los gráficos de líneas presentados en la sección 4.1, los dumbbell pueden mostrar de manera más puntual la comparación entre dos periodos de tiempo específicos (recordemos que los gráficos de líneas nos muestran varios períodos de tiempo, como es el caso mostrado por la Figura 4.3).
La Figura 9.7 es un ejemplo de gráfico de dumbbell, usando los datos del paquete gapminder (Bryan, 2017). Esta visualización muestra la evolución de la esperanza de vida al nacer entre 1952 y 2007 para cada uno de los países del continente americano.
Figura 9.7: Evolución de la esperanza de vida al nacer de América entre 1952 y 2007
Antes de realizar esta visualización es necesario acomodar la base de datos. Para eso, seguiremos los siguientes pasos:
- Filtrar los datos, teniendo en cuenta que las observaciones que necesitamos deben corresponder a América y ser del año 1952 o 200748.
- Seleccionar las variables que vamos a usar49. En este caso, necesitamos el país, el año y la expectativa de vida al nacer.
- Pasar los datos a formato ancho o wide50.
- Usamos ggplot2 para crear la visualización. Para los dumbbell se deben tener en cuenta tres capas de la geometría: El punto inicial, el punto final y el segmento que los une. Esto lo haremos a través de las funciones geom_point() y geom_segment().
# Cargar los paquetes
library(ggplot2)
library(gapminder)
library(dplyr)
library(tidyr)
gapminder %>%
filter(continent=="Americas" & year==2007 |
continent=="Americas" & year==1952) %>%
select(country, year, lifeExp) %>%
pivot_wider(names_from = year, values_from = lifeExp) %>%
ggplot() +
geom_segment( aes(x=reorder(country, -`2007`),
xend=country, y=`1952`, yend=`2007`),
color="grey") +
geom_point( aes(x=country, y=`1952`, color="1952"), size=3) +
geom_point( aes(x=country, y=`2007`,color="2007"), size=3 ) +
coord_flip()+
scale_color_manual(values = c(`1952` = "#f1a340",
`2007`= "#998ec3"))+
labs(color="Año",x="",y="Esperanza de vida al nacer")+
theme_minimal() + theme(legend.position = 'bottom')Siguiendo las recomendaciones para mejorar las visualizaciones presentadas en el Capítulo 6, reorganizamos los datos empleando la función reorder() del core de R (R Core Team, 2018). Esta función organiza las observaciones de menor a mayor de acuerdo a la expectativa de vida del año 2007 (puedes jugar un poco con las anteriores líneas de código para cambiar la salida a tu gusto). También, debemos incluir dos veces la función geom_point(); especificando cada variable que irá en el punto. En nuestro ejemplo, corresponde a la esperanza de vida al nacer en los años 1952 y 2007. Para mayor facilidad a la hora de interpretar este gráfico, hemos agregado colores en los puntos, para identificar a qué año se refiere la información.
Nota que la construcción de este gráfico es muy parecido al del lollipop. Sin embargo, el segmento no está anclado a ningún eje y hay un geom_point() extra, indicando la posición del otro punto.
Utilizar este tipo de visualización tiene la ventaja de que el análisis se concentra en solo dos periodos de tiempo; pero dependiendo de lo que se quiere mostrar, puede que se necesite una evolución que incluya más información, como lo realizamos en la sección 4.1.
9.2.2 Ranking (evolución de una variable ordinal)
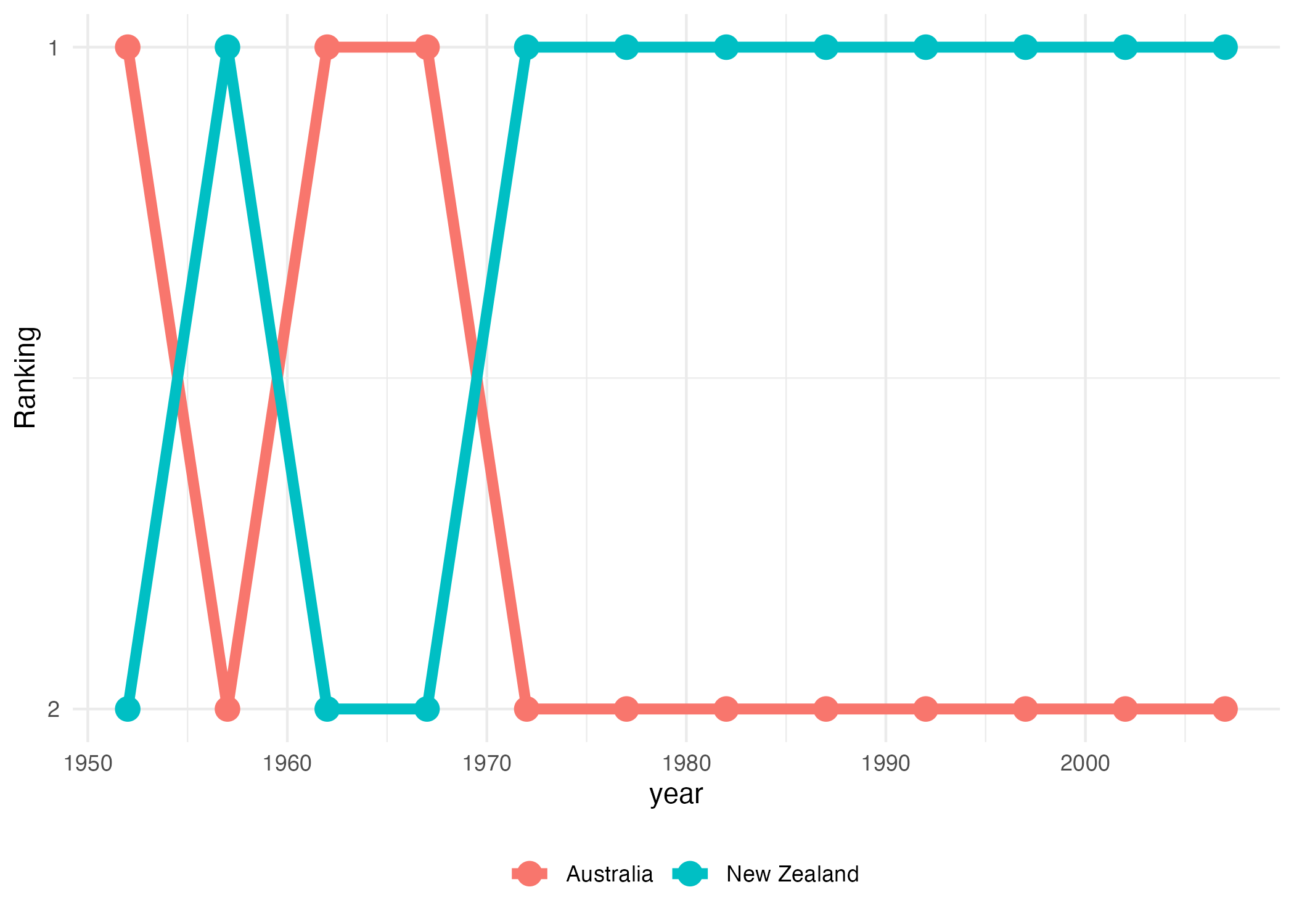
La Figura 9.8 muestra como cambió la posición año tras año en el Ranking de los países de Oceanía con la mayor esperanza de vida al nacer, empleando los datos disponibles en el objeto gapminder.
Estas visualizaciones muestran el lugar que ocupan las observaciones al ordenar de mayor a menor (o viceversa), la variable a la que le queremos hacer el ranking. De esta forma, podemos ver la evolución de la variable desde otra perspectiva.
Figura 9.8: Ranking de la esperanza de vida al nacer para los países de Oceanía
Para realizar la Figura 9.8, puedes emplear las siguientes líneas de código:
#Se cargan los paquetes
library(ggplot2)
library(gapminder)
library(dplyr)
ggplot(gapminder %>%
filter(continent=="Oceania") %>%
group_by(year) %>%
arrange(lifeExp)%>%
mutate(Ranking = row_number()), aes(x = year,
y = Ranking,
group = country))+
geom_line(aes(color = country), size = 2) +
geom_point(aes(color = country), size = 4) +
scale_y_reverse(breaks = 1:nrow(gapminder %>%
filter(continent=="Oceania") %>%
arrange(lifeExp)%>% mutate(Ranking = row_number())))+
theme_minimal() +
theme(legend.position="bottom") +
labs(color="")Primero, debemos manipular la base de datos, de forma que creemos un ranking por año de los países de Oceanía para la variable de interés. Para esto, creamos la variable Ranking, usando las funciones filter(), group_by(), arrange(), mutate() y row_number(), del paquete dplyr51.
En la capa de Aesthetics agregamos las variables que queremos dibujar (mapear). En nuestro ejemplo, serán el año (year), Ranking y el país (country). La capa de Geometría es manipulada con las funciones geom_line() y geom_point().
Una buena práctica para la realización de estos gráficos es organizar la escala del eje y (que muestra la posición en el ranking), de forma que el número uno se encuentre en la posición más alejada del eje x, mostrando la primera posición. Para esto, usamos la función scale_y_reverse() para cambiar la capa de Escalas.
Una visualización de evolución de Ranking es muy útil para determinar fácilmente qué observación tiene el valor mayor en una variable; sin embargo, tiene la desventaja de que no muestra los valores individuales, solo el orden. Es decir, sabremos que la posición uno tiene un mayor valor que la segunda, pero no tenemos conocimiento de cuál es la diferencia entre ambas observaciones.
9.3 Gráficos avanzados de composición
Cuando la naturaleza de los datos muestra cómo se distribuye la información en un solo período de tiempo, lo más apropiado es un gráfico de composición. Estos gráficos buscan mostrar en una foto las principales características de la información, como los subgrupos que hacen parte de la muestra en un momento específico de tiempo.
9.3.1 Treemap
Los treemap52 muestran la distribución de los datos en un solo periodo de tiempo usando rectángulos para identificar qué observaciones componen los grupos y subgrupos.
Como en los ejemplos de composición que vimos en la sección 3, el área de los treemap es proporcional al valor que están graficando; pero tienen la ventaja de que es posible agregar subgrupos. Esto permite que la información sea más detallada que los gráficos simples de composición.
Es fácil identificar, según la Figura 9.9, que, para el año 2007, el país con la mayor población es China, como muestra el tamaño del rectángulo correspondiente a este país.
Figura 9.9: Composición de la población por continente para el año 2007

Para hacer este gráfico se utilizó la base de datos del paquete gapminder (Bryan, 2017) , y se realizaron los siguientes pasos:
- Primero debemos instalar dos librerías: treemap (Tennekes, 2023) y treemapify (Wilkins, 2021). Estas nos permitirán hacer treemaps usando la estructura de ggplot2. Es decir, esta librería incluye una capa de Geometría nueva (geom_treemap) que funciona como todas las otras capas vistas hasta ahora.
- Filtramos el objeto gapminder para que los datos nos muestren la composición de un solo año. En este caso, usaremos 200753.
- Realizamos la gráfica, teniendo en cuenta agregar en la geometría la función geom_treemap() del paquete treemapify.
Para la realizar la gráfica 9.9 puedes correr las siguientes líneas de código:
#Se cargan los paquetes
library(ggplot2)
library(gapminder)
library(treemap)
library(treemapify)
library(dplyr)
gapminder %>%
filter(year==2007) %>%
ggplot(aes(area = pop, label = country)) +
geom_treemap(fill = "royalblue4") +
geom_treemap_text(colour = "white", place = "centre")+
theme_minimal() + theme(legend.position = 'bottom')Hasta ahora, hemos revisado cómo realizar un treemap graficando una variable numérica (correspondiente al área del rectángulo) y una categórica (la observación representada por el nombre en el rectángulo). Sin embargo, podemos agregar otra variable numérica a través del color, como lo muestra la Figura 9.10.
En este ejemplo, estamos graficando la población (mapeada al área del rectángulo) y la expectativa de vida (mapeada al color del relleno) por país, representadas por el área y la intensidad del color del rectángulo, respectivamente.
Figura 9.10: Composición y esperanza de vida por país para el año 2007
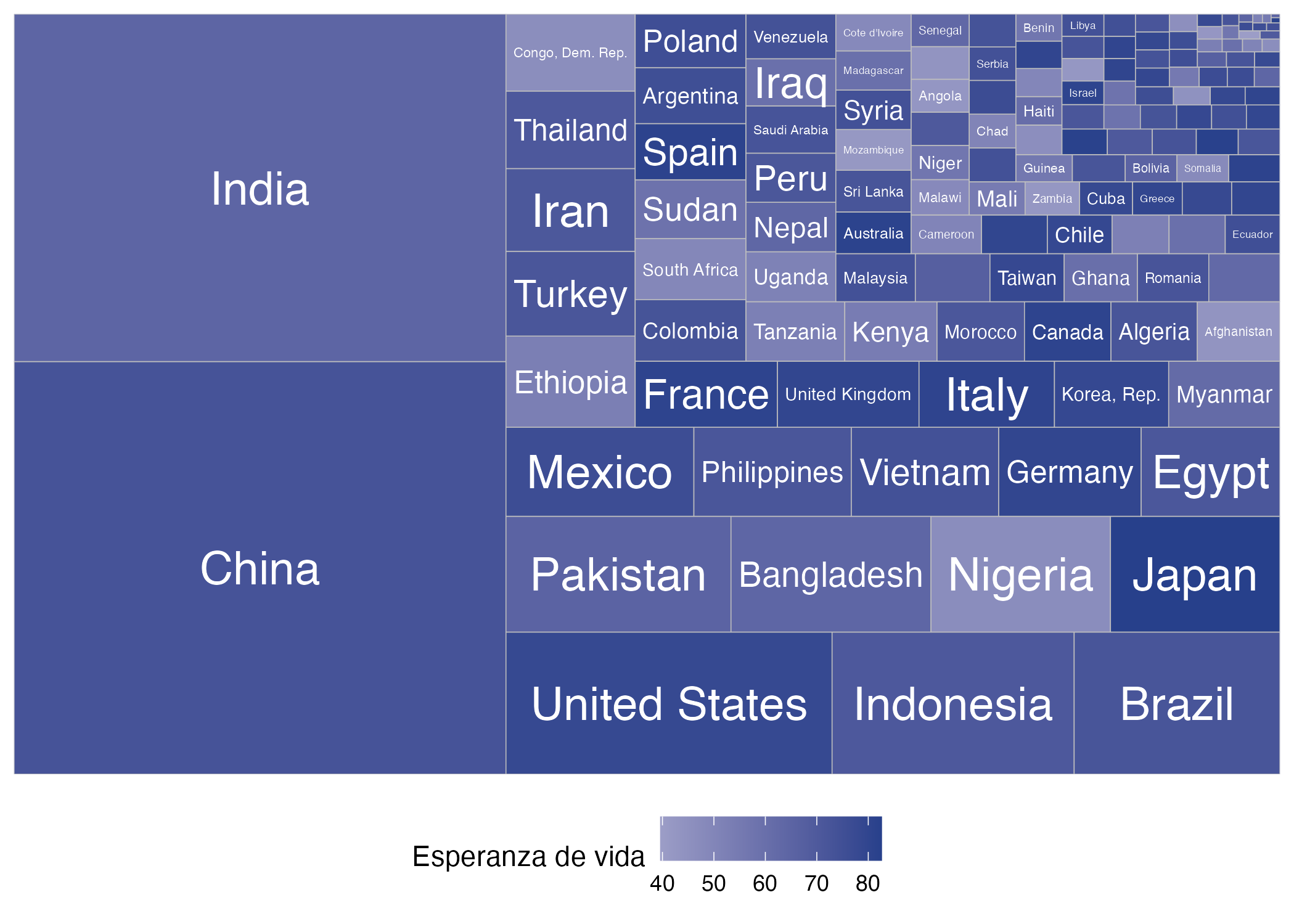
Para lograr la Figura 9.10, vamos a modificar un poco las líneas de código de la Figura 9.9, de la siguiente forma:
- Agregamos en la capa de Aesthetics el argumento fill y la variable que será representada a través del color. En este caso, es la expectativa de vida al nacer.
- Por defecto, el color del treemap más claro representará el valor más alto de nuestra nueva variable numérica. Para modificar esto, y a su vez elegir la escala de colores, cambiaremos la capa de Escalas a través de la función scale_fill_gradient2(), incluida en el paquete ggplot2.
Implementar las siguientes líneas de código nos permitirá que la expectativa de vida al nacer vaya del color blanco al color azul, correspondiendo el tono más fuerte a un mayor valor de la variable.
#Se cargan los paquetes
library(ggplot2)
library(gapminder)
library(treemap)
library(treemapify)
library(dplyr)
gapminder %>%
filter(year==2007) %>%
ggplot(aes(fill = lifeExp, area = pop, label = country)) +
geom_treemap() +
geom_treemap_text(colour = "white", place = "centre")+
scale_fill_gradient2(low="white", high = "royalblue4") +
labs(fill = "Esperanza de vida") +
theme_minimal() + theme(legend.position = 'bottom')Ya hemos logrado graficar dos variables numéricas y una categórica usando un treemap; pero esto no es todo lo que permite hacer este tipo de visualización. Como ya lo mencionamos, es posible agregar las observaciones en subgrupos. Por la naturaleza de los datos, tenemos que los continentes son la variable categórica disponible que vamos a utilizar, tal y como se muestra en la Figura 9.11.
Figura 9.11: Composición y esperanza de vida por país
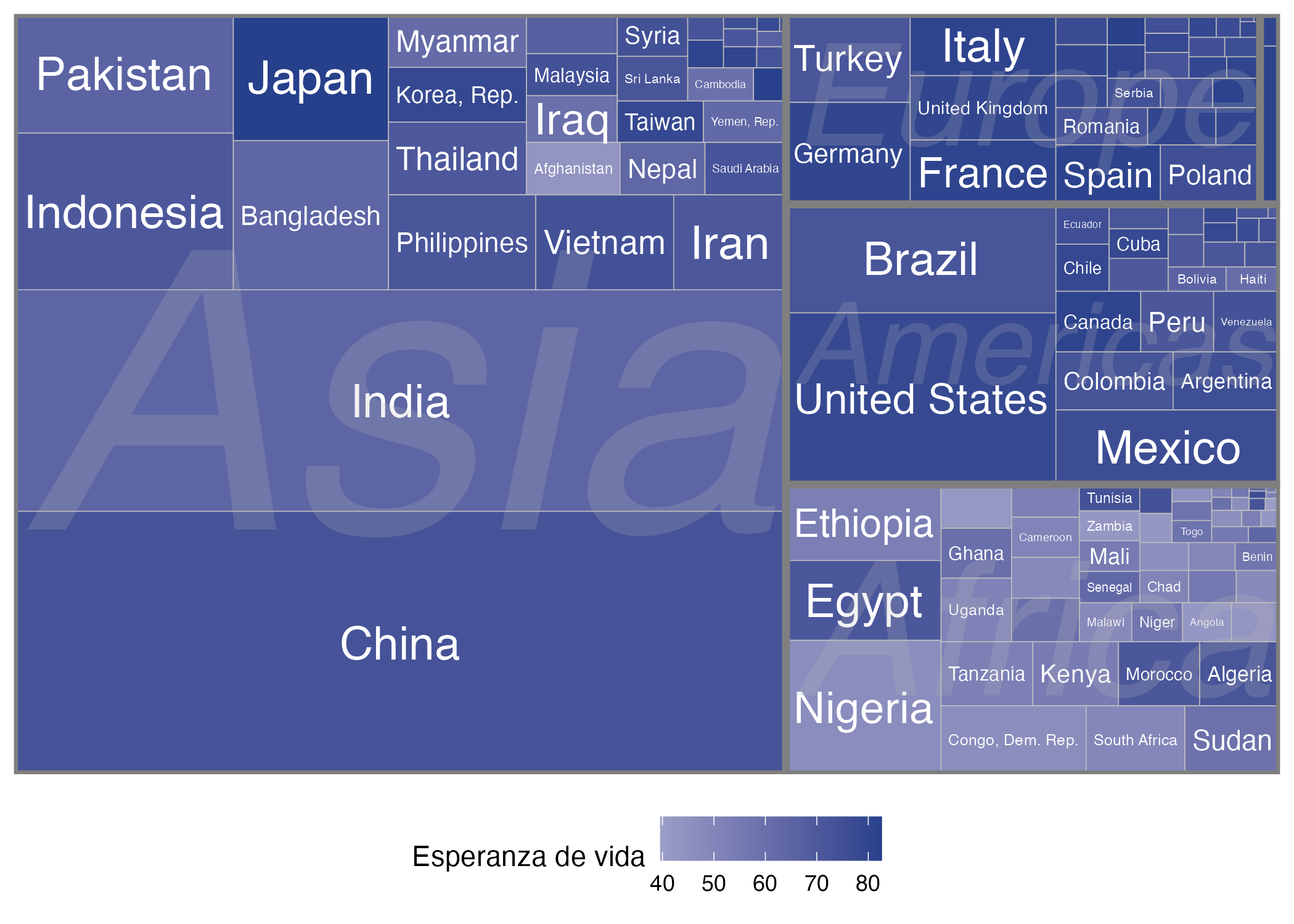
Esto lo podemos lograr agregando en la capa de Aesthetics el argumento subgroup, especificando la variable continente, como se muestra en las siguientes líneas de código:
#Se cargan los paquetes
library(ggplot2)
library(gapminder)
library(treemap)
library(treemapify)
gapminder %>%
filter(year==2007) %>%
ggplot(aes(fill = lifeExp, area = pop, label = country,
subgroup = continent)) +
geom_treemap() +
geom_treemap_subgroup_border() +
geom_treemap_text(colour = "white", place = "centre")+
scale_fill_gradient2(low="white", high="royalblue4") +
geom_treemap_subgroup_text(place = "centre", grow = T,
alpha = 0.2, colour ="grey",
fontface = "italic") +
labs(fill = "Esperanza de vida") +
theme_minimal() + theme(legend.position = 'bottom')Los treemaps son una buena herramienta para mostrar la composición de las observaciones y sus subgrupos cuando no hay muchos individuos que vayan a ser graficados. Otra desventaja de estas visualizaciones es que puede ser difícil comparar las áreas o la intensidad del color si los valores son muy parecidos entre sí.
9.3.2 Waffle
Los gráficos de waffle son otra alternativa para mostrar la composición de los datos en un solo período de tiempo. Cada observación está representada por un cuadrado, y el color de su área corresponde al grupo del que hace parte.
La Figura 9.12 muestra la cantidad de países que hay por continente en 2007, según la base de datos gapminder (Bryan, 2017). Como podrás ver, los waffle son una forma sencilla y poco detallada de mostrar composición, pues el color nos indica a qué continente pertenece cada país (cuadro).
Es importante notar que los waffle tienen sentido cuando se van a graficar variables clase integer, pues estamos contando las veces en las que las observaciones se encuentran en una categoría.
Figura 9.12: Número de países por continente
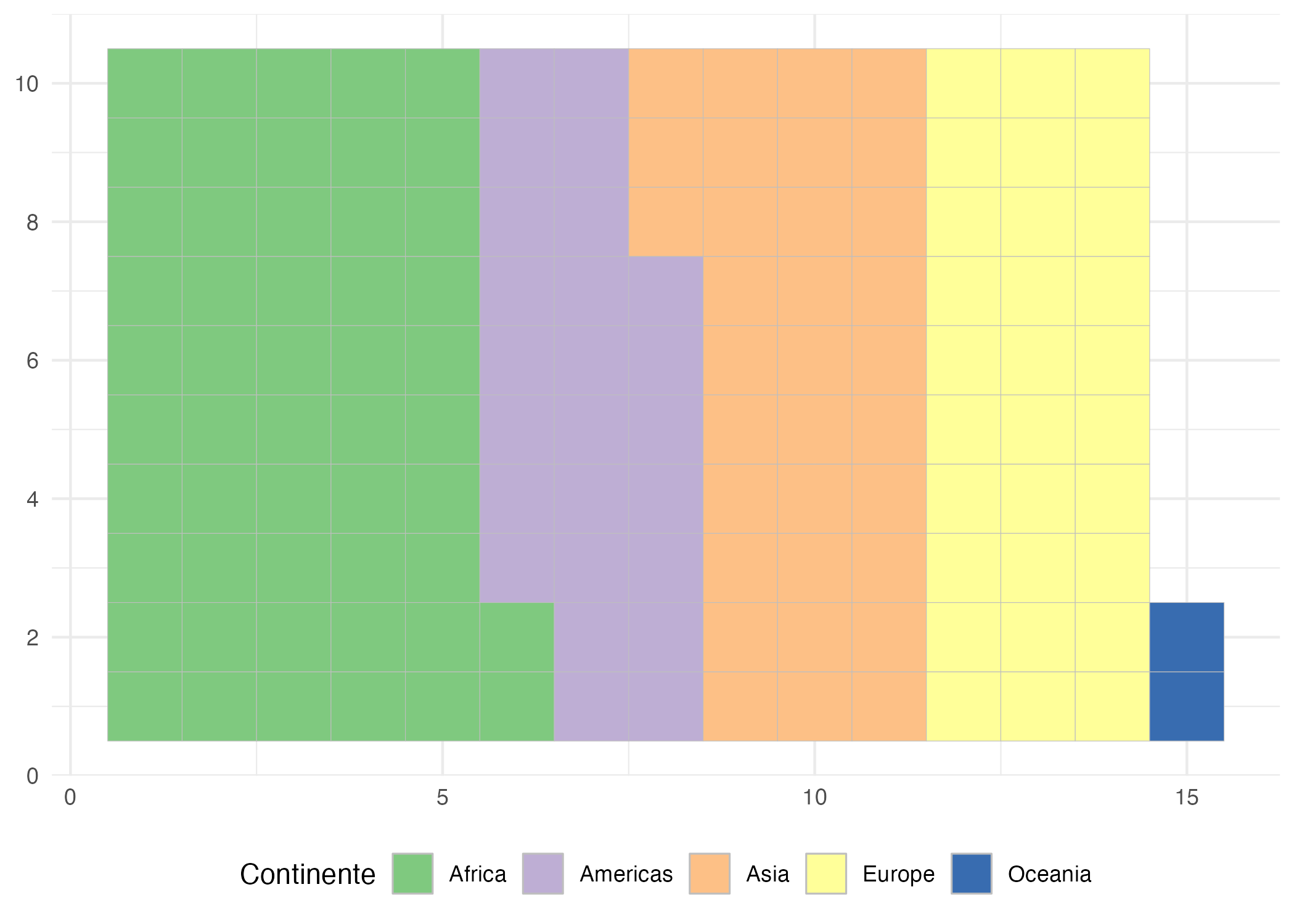
Para realizar la Figura 9.12, primero necesitamos instalar el paquete waffle (Rudis & Gandy, 2019), que contiene la geometría necesaria para crear el gráfico de waffle. Si no encuentras una versión del paquete adecuada para tu versión de R en el repositorio de CRAN, puedes descargar uno del repositorio del creador del paquete (Ver código).
Antes de pasar a usar ggplot() para realizar nuestro waffle, debemos crear una base de datos a partir de gapminder que tenga el número de países por continente en un año. Para esto, primero usaremos la función filter() para seleccionar el año 2007; después, agruparemos por la variable continent, usando la función group_by(); finalmente, contaremos las observaciones agrupadas con la función count(). Las funciones anteriores están disponibles en el paquete dplyr (Wickham, François, et al., 2023)54.
#Se cargan los paquetes
library(gapminder)
library(dplyr)
datos.waffle <- gapminder %>%
filter(year==2007) %>%
group_by(continent) %>%
count() Ahora tenemos el objeto datos.wafle con dos columnas: continent y n. Esta última corresponde al número de países que compone cada continente. Ahora, construyamos nuestra visualización especificando la capa Aesthetics con los argumentos fill para el color de relleno y values para el valor. Después, adicionaremos la capa de Geometría con la función geom_waffle() y terminamos personalizando nuestra visualización.
#Se cargan los paquetes
library(ggplot2)
# install.packages("waffle", repos = "https://cinc.rud.is")
library(waffle)
library(scales)
datos.waffle %>%
ggplot(aes(fill = continent, values=n)) +
geom_waffle(colour="grey", na.rm = TRUE)+
scale_fill_manual(values = c("#7fc97f","#beaed4",
"#fdc086","#ffff99","#386cb0"))+
scale_y_continuous(breaks= pretty_breaks())+
scale_x_continuous(breaks= pretty_breaks())+
labs(fill="Continente")+
theme_minimal()+ theme(legend.position = 'bottom')En la función geom_waffle() empleamos dos argumentos. El primer argumento es colour que define el color de las líneas que dividen los cuadrados. El segundo argumento, na.rm determina si se remueven o no los NA de los datos.
Adicionalmente, para personalizar nuestro gráfico, hemos decidido agregar un vector de colores de forma manual. Esto implica modificar la capa de Escalas por medio de la función scale_fill_manual() y empleando como argumento los colores que deseamos emplear. Otra sugerencia a la hora de emplear este tipo de visualización es asegurarse de que los ejes sean números enteros, pues no tiene mucho sentido utilizar otra escala para estos gráficos. Lo anterior lo resolvemos modificando la capa de Escalas, usando la función scale_y_continuous() y scale_x_continuous(), del paquete ggplot2, y especificando el argumento breaks con la función pretty_breaks(), disponible en el paquete scales (Wickham & Seidel, 2022).
Noten que en este caso se cuenta con 142 países. Por eso, tenemos dos cuadros que parecen desalineados. Una variante del gráfico de waffle es expresar las categorías no como número (términos absolutos) sino como porcentaje (términos relativos). Pero será necesario aproximar los porcentajes a números enteros. La Figura 9.13 muestra los mismos datos de la Figura 9.12 pero en forma de porcentajes, aproximando a números enteros. Si bien se pierde precisión con esta aproximación, es visualmente “más” agradable que la primera versión (Figura 9.12) y da una idea aproximada de la composición de los países por continente. Esto se logra asignándole al argumento make_proportional el valor de TRUE en la función geom_waffle(). Este argumento es por defecto igual a FALSE.El código para esta figura se muestra a continuación.
Figura 9.13: Proporción de países por continente
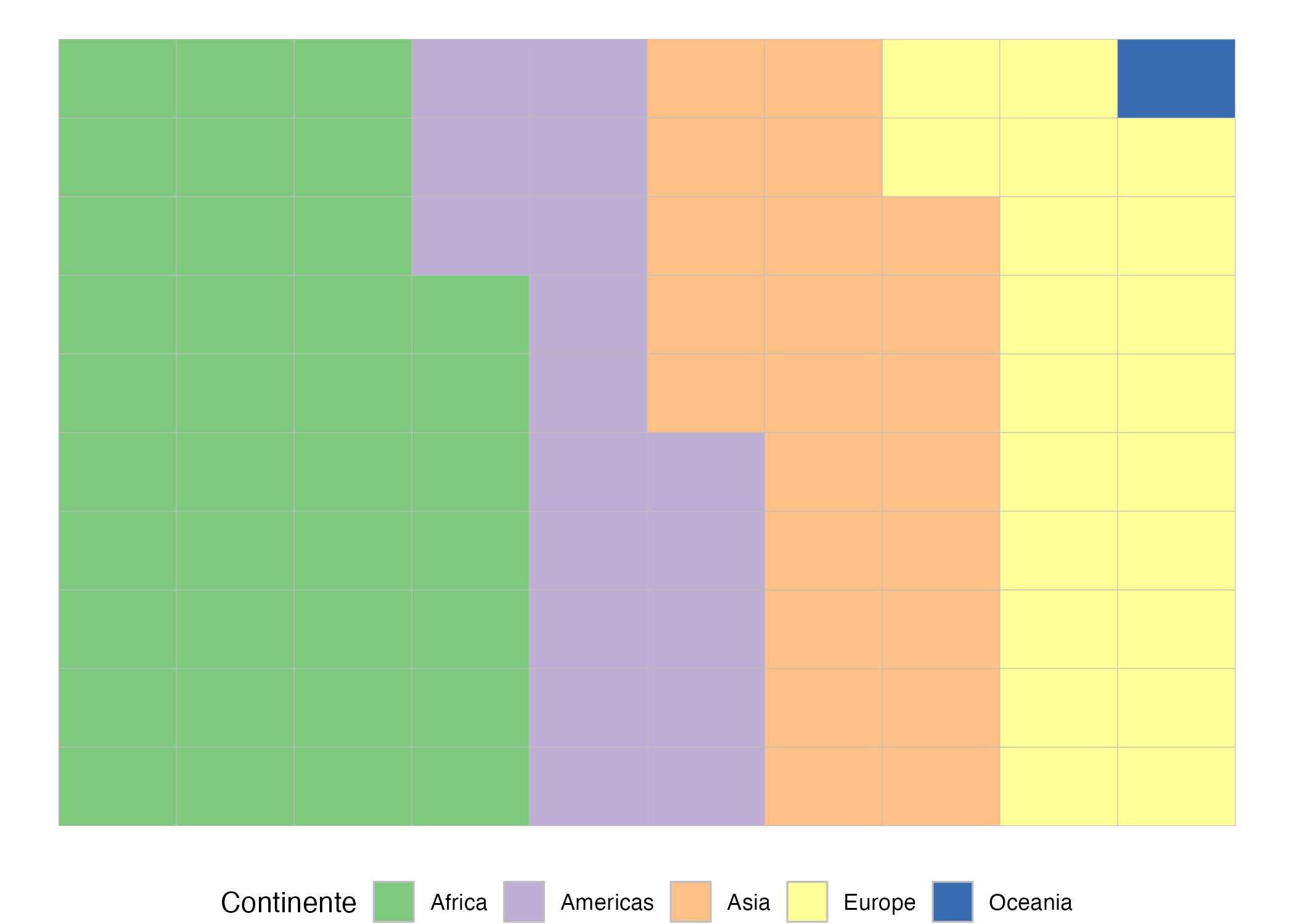
#Se cargan los paquetes
library(ggplot2)
library(gapminder)
library(dplyr)
# install.packages("waffle", repos = "https://cinc.rud.is")
library(waffle)
library(scales)
datos.waffle %>%
ggplot(aes(fill = continent, values=n)) +
geom_waffle(colour="grey", na.rm = TRUE,
make_proportional = TRUE)+
scale_fill_manual(values = c("#7fc97f","#beaed4",
"#fdc086","#ffff99","#386cb0"))+
scale_y_continuous(breaks= pretty_breaks())+
scale_x_continuous(breaks= pretty_breaks())+
labs(fill="Continente")+
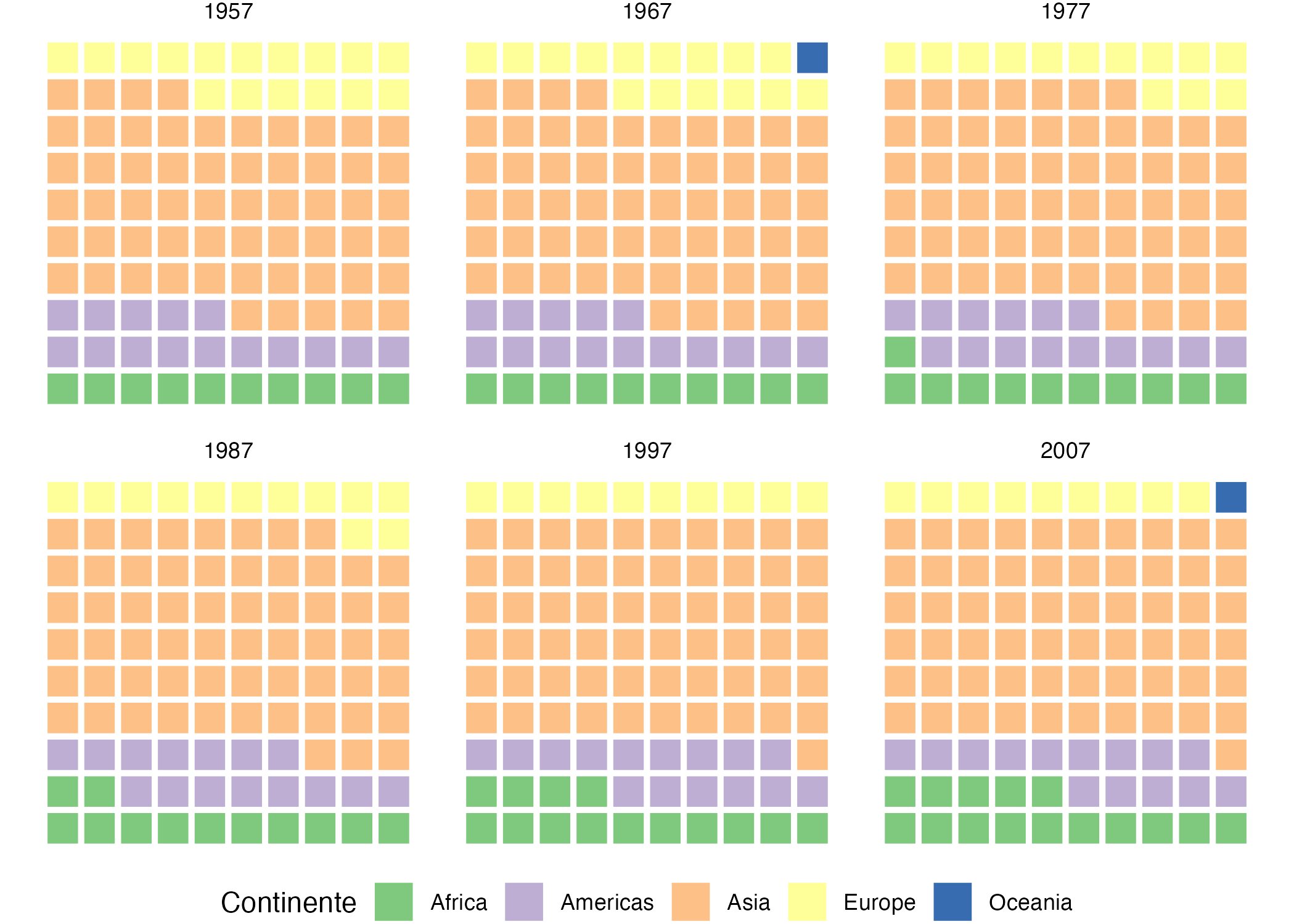
theme_void()+ theme(legend.position = 'bottom')El gráfico de waffle tambien puede ser útil par mostrar la evolución de la composición. Por ejemplo, en la Figura 9.14 se presenta la evolución a través del tiempo de la participación porcentual en la población de cada uno de los continentes.
Figura 9.14: Evolución de la particiapción porcentual de cada continente en la población mundial
La Figura 9.14 se puede construir empleando el siguiente código:
# Se crea la base de datos
datos.wafle.pob <- gapminder %>%
group_by(continent, year) %>%
summarise(pop= sum(pop)) %>%
filter(year %in% c(1957, 1967, 1977, 1987, 1997, 2007))
# Se crea la visualización
datos.wafle.pob %>%
ggplot(aes(fill = continent, values = pop)) +
geom_waffle(color = "white", size = 1.125, n_rows = 10,
flip = TRUE, na.rm = TRUE,
make_proportional = TRUE) +
facet_wrap(~year, ncol = 3) +
scale_x_continuous(breaks= pretty_breaks())+
scale_y_continuous(breaks= pretty_breaks())+
scale_fill_manual(values = c("#7fc97f","#beaed4",
"#fdc086","#ffff99","#386cb0"))+
coord_equal() +
theme_void()+
labs(fill="Continente") +
theme(legend.position = 'bottom') Nota que en este caso estamos empleando la capa de Facets para hacer repetir los gráficos de waffle por año.
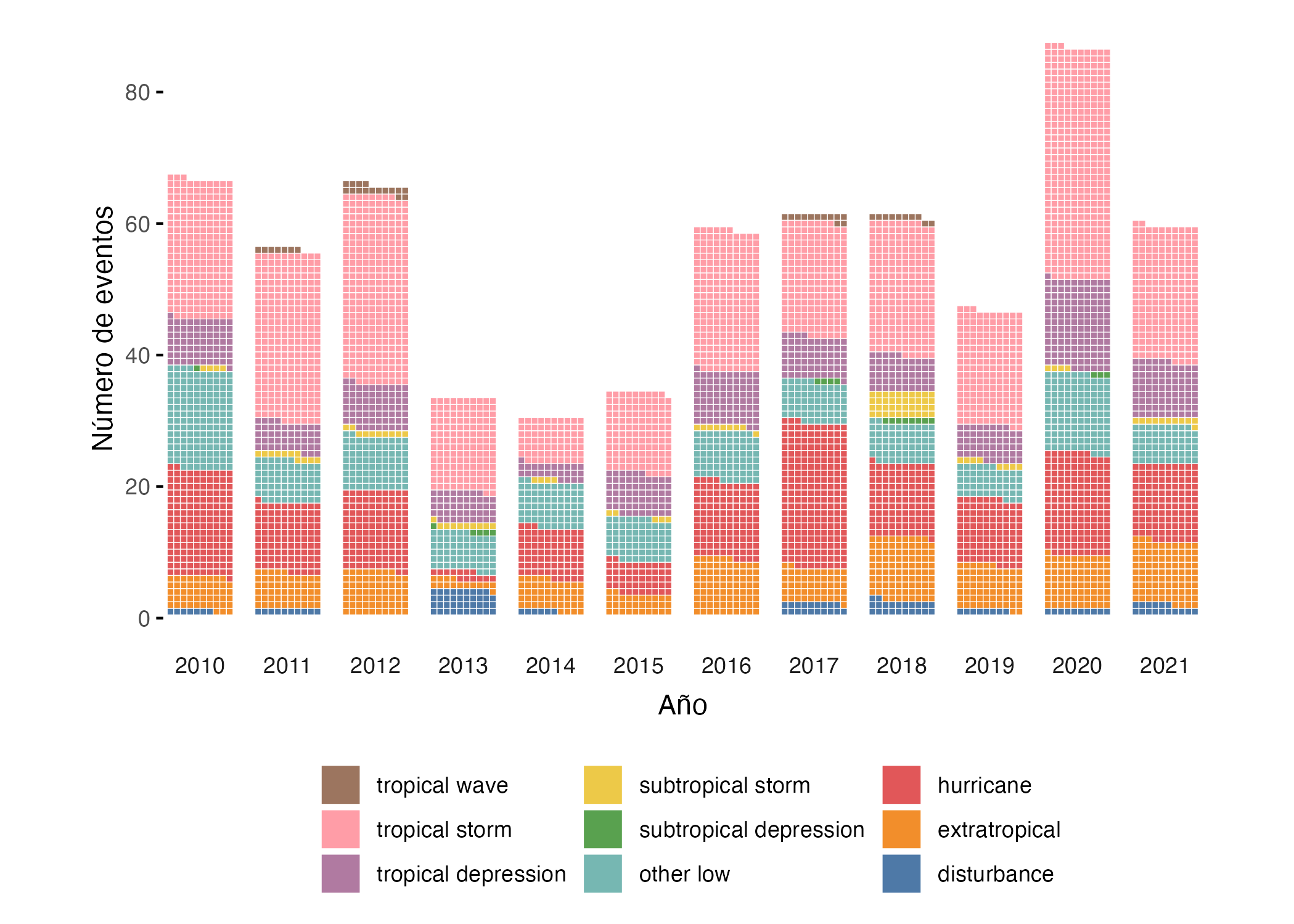
Otra forma interesante de emplear los gráficos de waffle para mostrar la evolución de composición se presenta en la Figura 9.15. En este caso, estamos empleando los datos de tormentas en el océano Atlántico (objeto storms) disponible en el paquete dplyr55 (Wickham, François, et al., 2023) . En este caso, se presenta el número de eventos de tormentas (y no la participación). La visualización no solo permite ver la composición, sino también cómo en el año 2020 se presentaron más eventos que los otros años visualizados.
Figura 9.15: Evolución de los diferentes tipos de tomentas en el océano Atlantico
La Figura 9.15 se puede construir empleando el siguiente código:
# Se crea la base de datos
library(dplyr)
datos.storms <- storms %>%
filter(year >= 2010) %>%
count(year, status)
# Se crea la visualización
datos.storms %>%
ggplot(aes(fill = status, values = n)) +
geom_waffle(color = "white", size = 0.15,
n_rows = 10, flip = TRUE, na.rm = TRUE) +
facet_wrap(~year, nrow = 1, strip.position = "bottom") +
scale_x_discrete() +
scale_y_continuous(breaks= pretty_breaks())+
ggthemes::scale_fill_tableau(name=NULL) +
coord_equal() +
labs(x = "Año", y = "Número de eventos") +
theme_minimal() +
theme(legend.position = 'bottom',
panel.grid = element_blank(),
axis.ticks.y = element_line()) +
guides(fill = guide_legend(reverse = TRUE,
nrow = 3))Finalmente, los gráficos de waffle se pueden convertir en pictogramas. Un pictograma utiliza íconos o imágenes en lugar de cuadrados. Los pictogramas son especialmente útiles para representar datos en una manera que sea fácil de entender para el público en general y son muy empleados en la construcción de infografías.
El paquete waffle (Rudis & Gandy, 2019) incluye la función geom_pictogram() que permite emplear en la capa de Geometría un pictograma. Por ejemplo, la Figura 9.16 presenta un pictograma para la composición de la población por continente para el año 2007.
Figura 9.16: Pitograma de la participación porcentual en la población total de cada continente
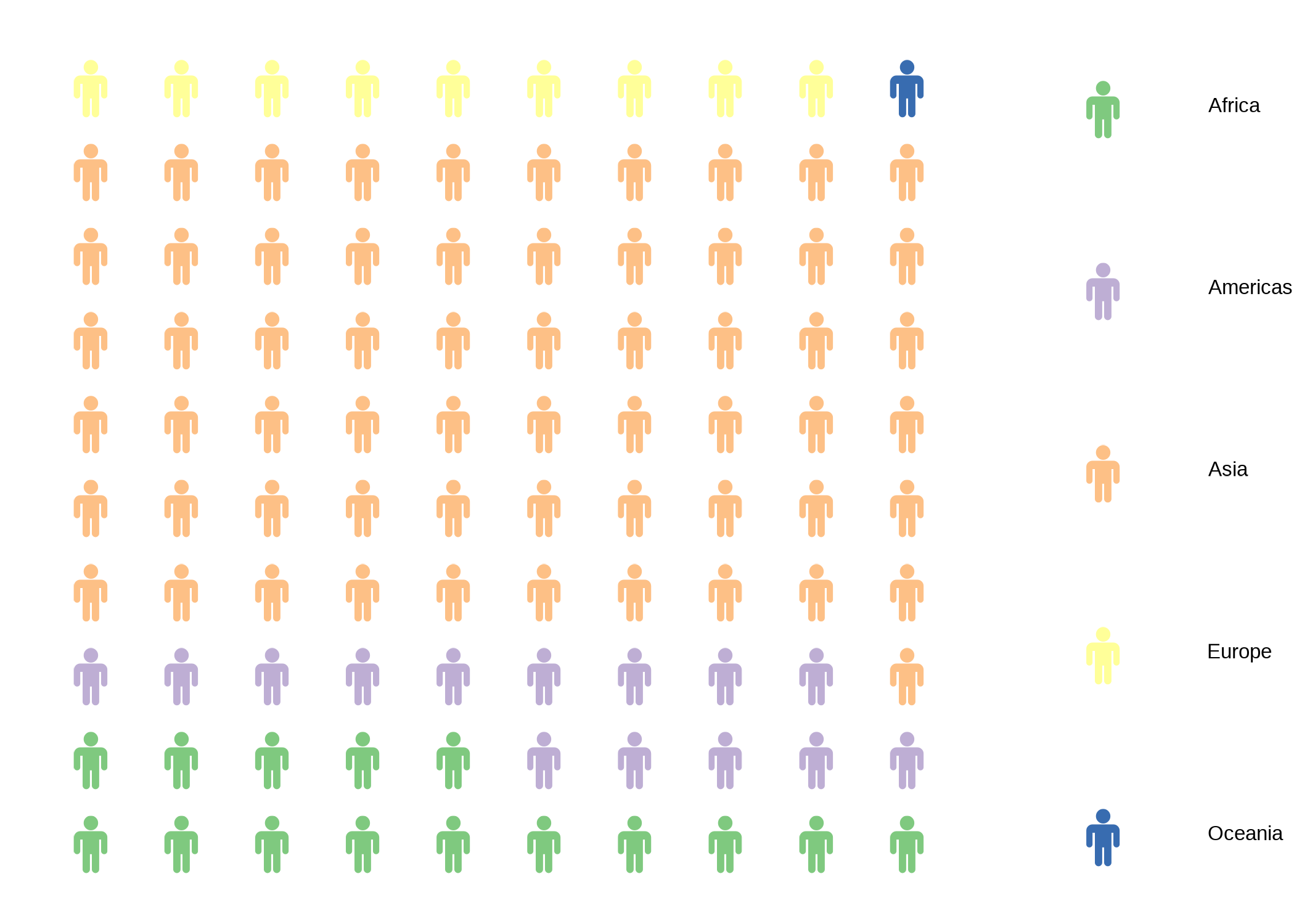
La Figura 9.16 se puede construir empleando el siguiente código:
# Se carga el paquete para emplear los iconos
# si no tienes instalado el paquete instálalo
# install.packages("emojifont")
library(emojifont)
# se carga el tipo de letra necesario para los íconos
load.fontawesome()
# Se crea la base de datos
datos.pob.2007 <- gapminder %>%
filter(year==2007) %>%
group_by(continent) %>%
summarise(pob = sum(pop))
# Se crea la visualización
datos.pob.2007 %>%
ggplot(aes(label = continent, colour= continent,
values=pob)) +
geom_pictogram(n_rows = 10, make_proportional = TRUE,
family = 'fontawesome-webfont',
size = 25, flip = TRUE,
show.legend = TRUE) +
scale_colour_manual(values = c("#7fc97f","#beaed4",
"#fdc086","#ffff99","#386cb0"))+
scale_label_pictogram( values = c("male")) +
scale_y_continuous(breaks= pretty_breaks())+
scale_x_continuous(breaks= pretty_breaks())+
theme_void()+ theme(legend.position = 'bottom',
legend.title = element_blank(),
legend.text = element_text(size = 25)) +
guides(fill = guide_legend(reverse = TRUE))Para emplear los diferentes íconos será necesario intalar el tipo de letra font awesome-webfont56. Nota que con la función scale_label_pictogram() estamos definiendo el ícono que empleamos en el pictograma. en este caso estamos empleando el ícono male. Podríanos emplear un icono diferente para cada categoría de la variable que mapeamos al argumento label. Empleando la función search_fontawesome() del paquete emojifont (Yu, 2021) se pueden buscar iconos que concuerden con el objetivo de nuestra visualización. Por ejemplo, el siguiente código busca los nombres de los íconos que contenga en su nombre “male”:
# se buscan iconos que contengan los caracteres "male"
search_fontawesome("male", approximate = TRUE)## [1] "fa-balance-scale" "fa-calendar"
## [3] "fa-calendar-check-o" "fa-calendar-minus-o"
## [5] "fa-calendar-o" "fa-calendar-plus-o"
## [7] "fa-calendar-times-o" "fa-female"
## [9] "fa-file-image-o" "fa-image"
## [11] "fa-male" "fa-smile-o"
## [13] "fa-stumbleupon" "fa-stumbleupon-circle"Nota que el nombre del ícono corresponde a los caracteres que están después de “fa-”; este prefijo corresponde font awesome (fa). Ahora intenta usar 5 diferentes íconos para modificar la Figura 9.16, de tal manera que cada continente tenga un ícono diferente. Por ejemplo, corre el siguiente código.
datos.pob.2007 %>%
ggplot(aes(label = continent, colour= continent,
values=pob)) +
geom_pictogram(n_rows = 10, make_proportional = TRUE,
family = 'fontawesome-webfont',
size = 10, flip = TRUE,
show.legend = TRUE) +
scale_colour_manual(values = c("#7fc97f","#beaed4",
"#fdc086","#ffff99","#386cb0"))+
scale_label_pictogram( values = c("balance-scale",
"object-group",
"apple", "object-ungroup",
"calendar")) +
scale_y_continuous(breaks= pretty_breaks())+
scale_x_continuous(breaks= pretty_breaks())+
theme_void()+ theme(legend.position = 'bottom',
legend.title = element_blank()) +
guides(fill = guide_legend(reverse = TRUE))9.3.3 Sankey
A diferencia de las anteriores visualizaciones, el gráfico de Sankey permite visualizar la composición de las observaciones según varias variables cualitativas. Aquí, cada característica (variable) de las observaciones compone un nodo, y va creando un flujo, a través de arcos, de una característica a otra. Esto permite mostrar la relación entre la composición cuando consideramos diferentes variables categóricas.
Hay que tener en cuenta que las características que se pueden seguir de una misma observación son las que están ubicadas a la derecha e izquierda de un nodo; esto quiere decir que puedo saber las características de una observación según mi punto de partida o el orden que le de al gráfico.
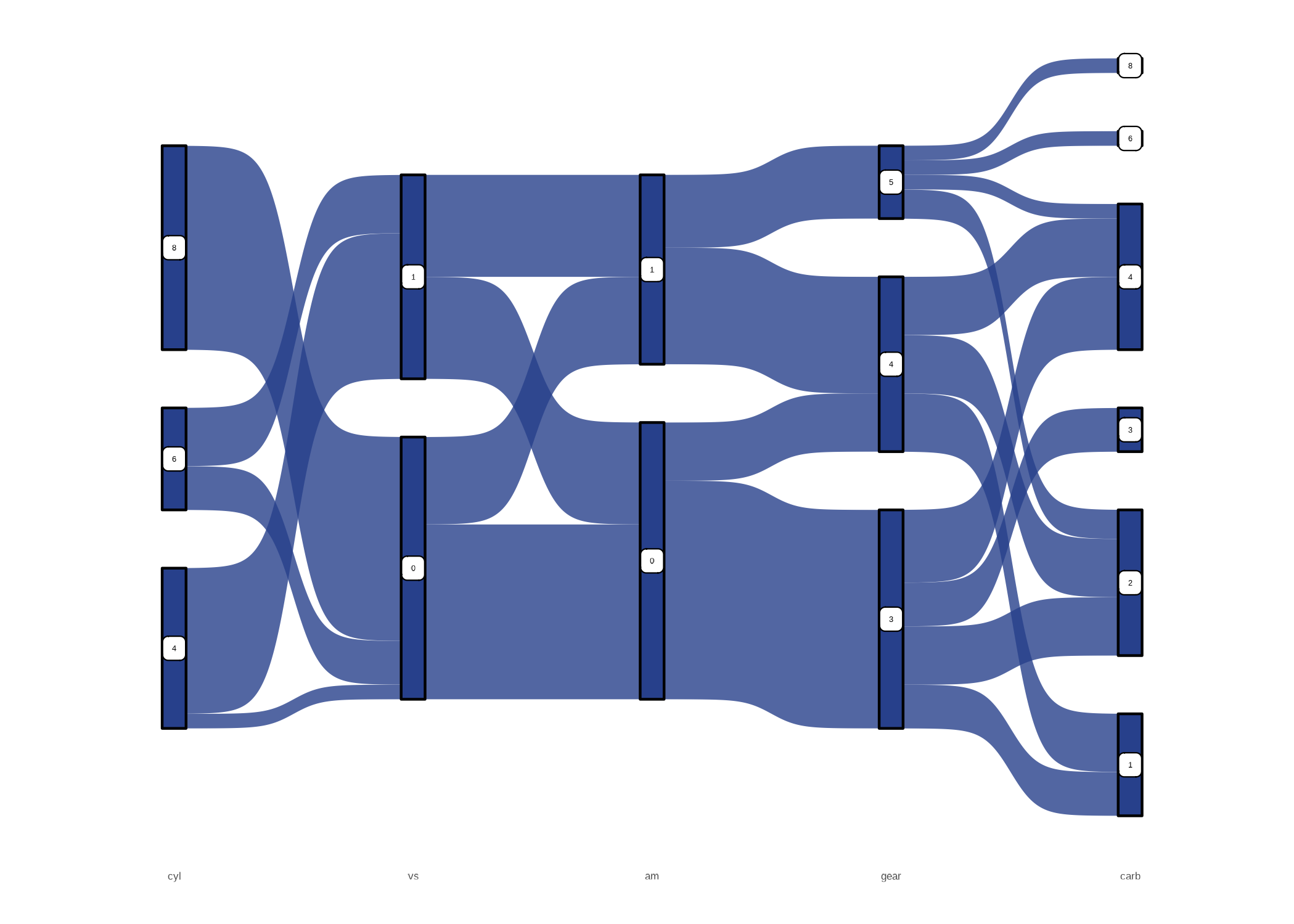
Como ejemplo, tenemos la Figura 9.17. Esta muestra unos datos extraídos de la revista Motor Trend US del año 1974, y están disponibles en el objeto mtcars, que hace parte del paquete base de R (R Core Team, 2018). Empezando por los primeros nodos, es fácil ver que, por ejemplo, todos los autos de ocho cilindros (variable cyl), corresponden al tipo de motor en forma de V (variable vs y categoría 0)57. Y a su vez podemos ver como los carros con motor en V se distribuyen cuando consideramos el tipo de transmisión (variable am). Y así sucesivamente para las variables número de cambios (gear) y número de carburadores (carb).
Figura 9.17: Composición de las características de los carros en la muestra
Para hacer un gráfico de Sankey, es importante tener en cuenta que los datos deben tener una estructura específica. En nuestro caso, la función make_long() del paquete ggsankey (Sjoberg, 2023) nos permite llegar fácilmente al resultado deseado especificando las variables de las cuales vendrán los nodos de nuestra visualización.
Las siguientes líneas de código muestran cómo llegar a la Figura 9.17, con la única modificación de cambiar las leyendas para que las categorías sean más claras.
install.packages("remotes")
remotes::install_github("davidsjoberg/ggsankey")
library(ggsankey)
library(ggplot2)
library(dplyr)
mtcars$vs<-recode(mtcars$vs, "0"="V-shaped", "1"="straight" )
mtcars$am<-recode(mtcars$am, "0"="automatic", "1"="manual" )
ggplot(mtcars %>%
make_long(cyl, vs, am, gear, carb),
aes(x = x,
next_x = next_x,
node = node,
next_node = next_node,
fill = factor(node),
label = node)) +
geom_sankey(flow.alpha = 0.8, node.color = 1) +
geom_sankey_label(size = 3.5, color = 1,
fill = "white", show.legend = NA) +
scale_fill_manual(values=replicate(11,"royalblue4"))+
theme_sankey(base_size = 16) +
theme(legend.position = "none")+
labs(x="")Primero, es necesario instalar el paquete remotes (Csárdi et al., 2021), el cual permite que R instale paquetes desde repositorios remotos, como Github. Después, usamos la función install_github() para descargar e instalar el paquete ggsankey (Sjoberg, 2023), el cual contiene las funciones necesarias para realizar nuestra visualización.
Cargamos los paquetes, y, a continuación, hacemos el cambio en las leyendas del objeto mtcars (R Core Team, 2018). Utilizando la función recode() , modificamos las etiquetas de las variables vs y am.
Posteriormente, debemos pasar los datos de formato ancho (wide) a formato largo (long). Esto lo logramos usando la función make_long(), disponible en el paquete ggsankey . Por defecto, esta función creará los flujos del Sankey. Cada observación determinará de dónde a dónde irá el arco. En la capa de Aesthetics es importante especificar de dónde a dónde irán los flujos, con los argumentos x, next_x, node y next_node (nota que la función make_long() cambia el nombre de las variables por los argumentos que acabamos de mencionar). Lo siguiente que debemos agregar es la capa de Geometría, utilizando la función geom_sankey() (Allaire et al., 2017), para especificar el tipo de gráfico que queremos.
9.4 Comentarios finales
Este capítulo desarrolló visualizaciones que requerían un nivel mayor de comprensión de líneas de código. Dependiendo de tu objetivo y tu público, pueden ser útiles para mostrar fielmente tu información.
Ahora tienes disponible estas visualizaciones en tu caja de herramientas para descrestar a tu público. Esperamos explores en la comunidad de usuarios de R todas las visualizaciones que están disponibles en ggplot2 o en paquetes que adicionan capas de Geometría. Si quieres ver alguna visualización en especial en futuras ediciones de este libro, no dudes en escribirnos.
Esperamos que con las herramientas aprendidas puedas generar visualizaciones de alto impacto. Recuerda: ¡la imaginación es el límite!
Referencias
La traducción de lollipop sería bombón, chupeta, piruleta o pirulí. Dependiendo del lugar donde te encuentres, la traducción adecuada será diferente. En últimas, nos estamos refiriendo a un dulce que está sujetado por un palo y se consume al chuparlo. ↩︎
Nota que para esto empleamos la función filter() del paquete dplyr. Para más información al respecto, puedes consultar Alonso (2022).↩︎
Nota que para esto empleamos las funciones group_by() y count() del paquete dplyr. Para más información al respecto, puedes consultar Alonso (2022).↩︎
Como podrás notar, su forma se asemeja a la de un violín. De ahí su nombre.↩︎
Pista: emplea el argumento width igual a
0.1en la geometría de Boxplot y el color gris para lograr una visualización igual a la presentada.↩︎Para más información al respecto, puedes consultar Alonso (2022).↩︎
El nombre de este gráfico viene de su parecido a las mancuernas, un tipo de pesa usada para hacer ejercicio, la cual es llamada dumbbell en inglés.↩︎
Nota que para esto empleamos la función filter() del paquete dplyr y los operadores lógicos & y |. Para más información al respecto, puedes consultar Alonso (2022).↩︎
Para esto, usamos la función select() del paquete dplyr. Para más información al respecto, puedes consultar Alonso (2022).↩︎
Para lograr esto, usamos la función pivot_wider() del paquete tidyr (Wickham, Vaughan, et al., 2023). ↩︎
Para más información al respecto, puedes consultar Alonso (2022).↩︎
Una traducción para este término es “mapeo de árboles”. Pero es poco usual que se emplee este término en español para referirnos a esta visualización. Es más común emplear el término en inglés.↩︎
Para esto, usamos la función filter() del paquete dplyr. Para más información al respecto, puedes consultar Alonso (2022).↩︎
Para más información al respecto, puedes consultar Alonso (2022).↩︎
Estos datos pertenecen a la base de datos de huracanes del Atlántico de la NOAA de los Estados Unidos. Puedes mirar la ayuda de este objeto para mayor información↩︎
Esta letra se puede descargar del siguiente enlace: https://fontawesome.com/docs/web/setup/host-yourself/webfonts.↩︎
Esto lo puedes verificar utilizando el diccionario de datos de la base, disponible en la descripción del objeto en la herramienta de ayuda de RStudio.↩︎