1 El paquete ggplot2
R (R Core Team, 2018) es un lenguaje de programación de uso libre entorno al cual se ha creado una comunidad muy grande alrededor del mundo3. La base de R es muy potente y permite realizar gráficos de alta calidad, pero se requiere de mucho trabajo para lograrlas. No obstante, la base de R permite generar visualizaciones, puede resultar poco intuitivo para la persona que está iniciando. Cambiar los diferentes elementos de una visualización puede ser a veces confuso en la base de R. El paquete ggplot2 (Wickham, 2016) resuelve este problema.
El paquete ggplot2 fue construido de tal manera que se pueda seguir la gramática de los gráficos propuesta por la ciencia estadística. Esa gramática de los gráficos fue finalmente compilada por Wilkinson (2012). La primera versión del paquete fue liberada por Hadley Wickham el 10 de junio de 2007. Desde entonces el paquete se ha enriquecido con diferentes elementos. En los últimos años, ggplot2 se ha convertido en el paquete de creación de visualizaciones más popular en el universo R por permitir de manera sencilla obtener gráficos de alta calidad. Por ejemplo, en las Figuras 1.1, 1.2 y 1.3 vemos unas visualizaciones creadas con ggplot2 empleando un par de líneas.
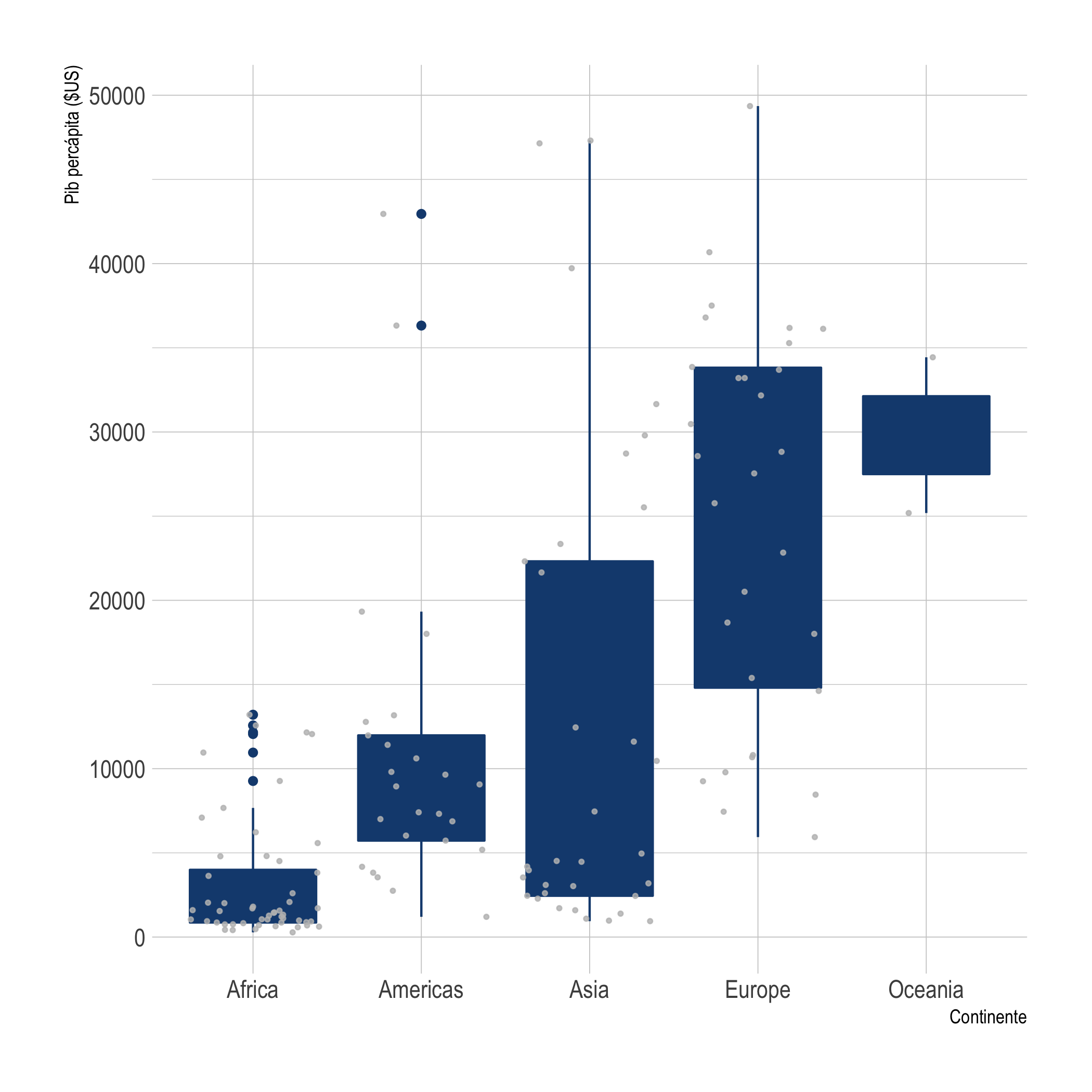
La Figura 1.1 presenta un diagrama de cajas (o también conocido como Boxplot) que además incluye cada una de las observaciones por grupo; en el Capítulo 3 explicaremos cómo interpretar y construir estas visualizaciones.
Figura 1.1: Distribución del PIB percápita por continente (2007)
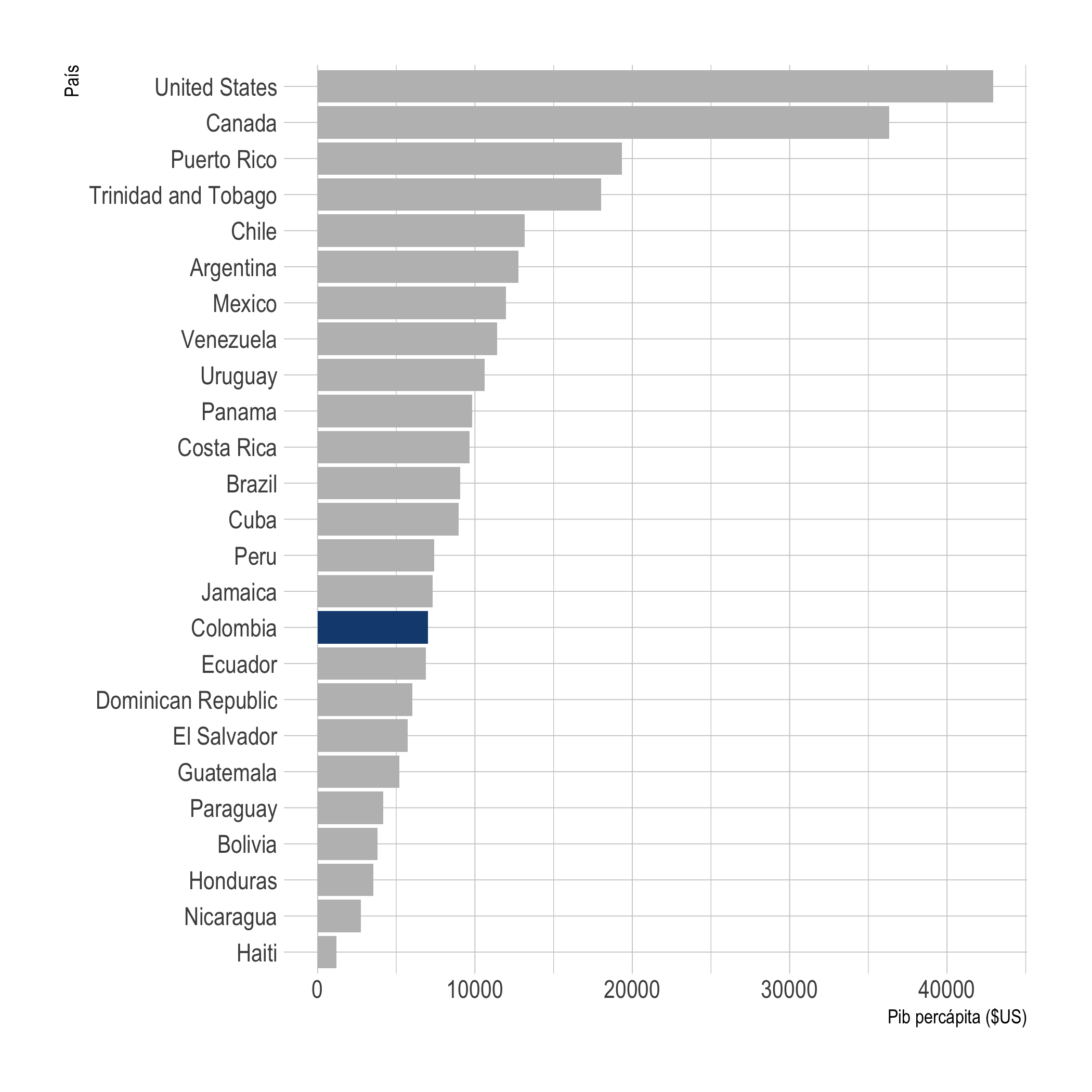
La Figura 1.2 presenta un gráfico de barras tradicional que aprenderemos a construir en el Capítulo 3. Ese gráfico lo hemos “embellecido” empleando unos trucos que estudiaremos en el Capítulo 6.
Figura 1.2: PIB percápita de los países del continente Americano (2007)
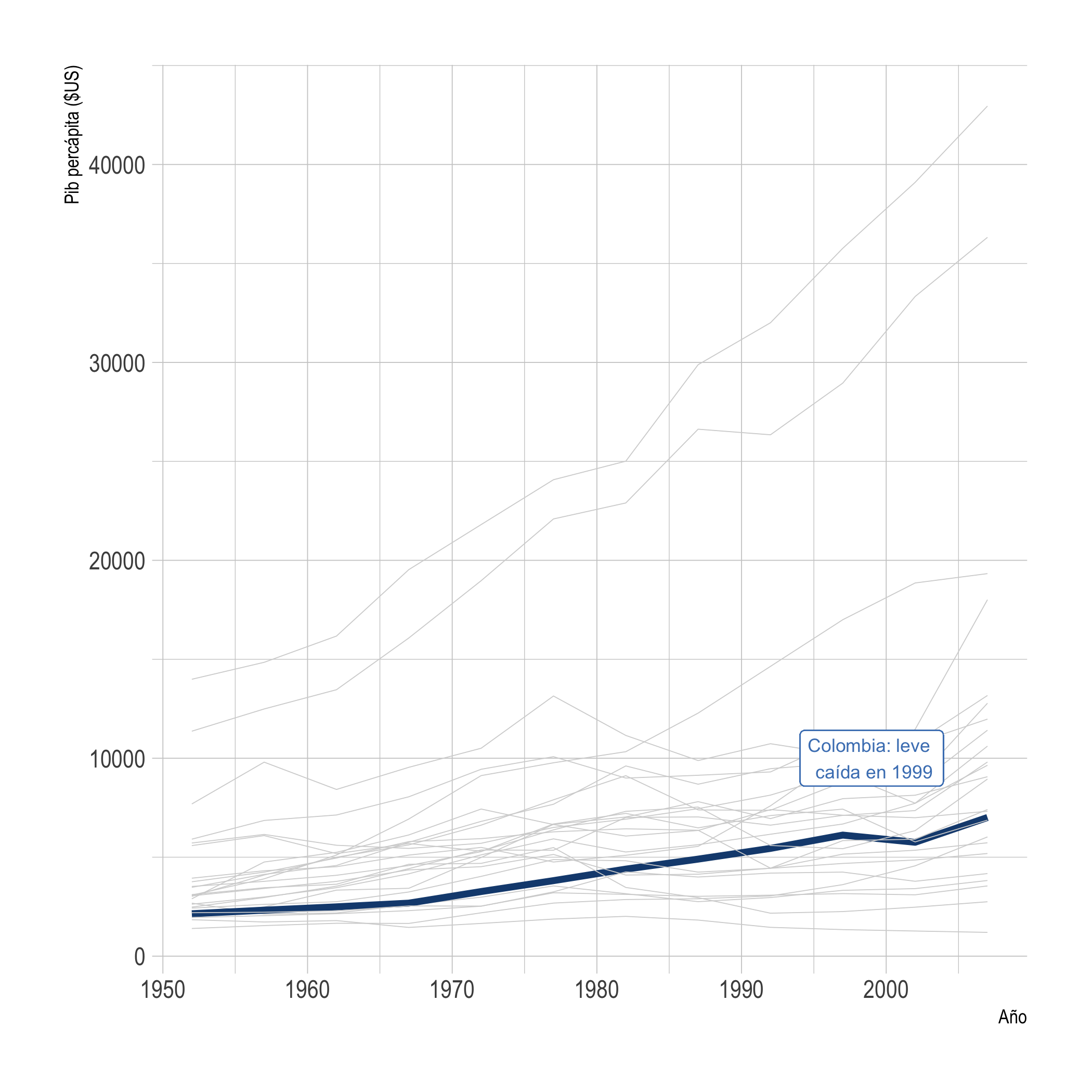
La Figura 1.3 presenta un gráfico de líneas con una anotación que permite resaltar uno de los casos. El gráfico de líneas lo estudiaremos en el Capítulo 4, y en el Capítulo 6 veremos como hacer las anotaciones y resaltar una sola línea.
Figura 1.3: Evolución del PIB percápita de Colombia y otros países de las Américas
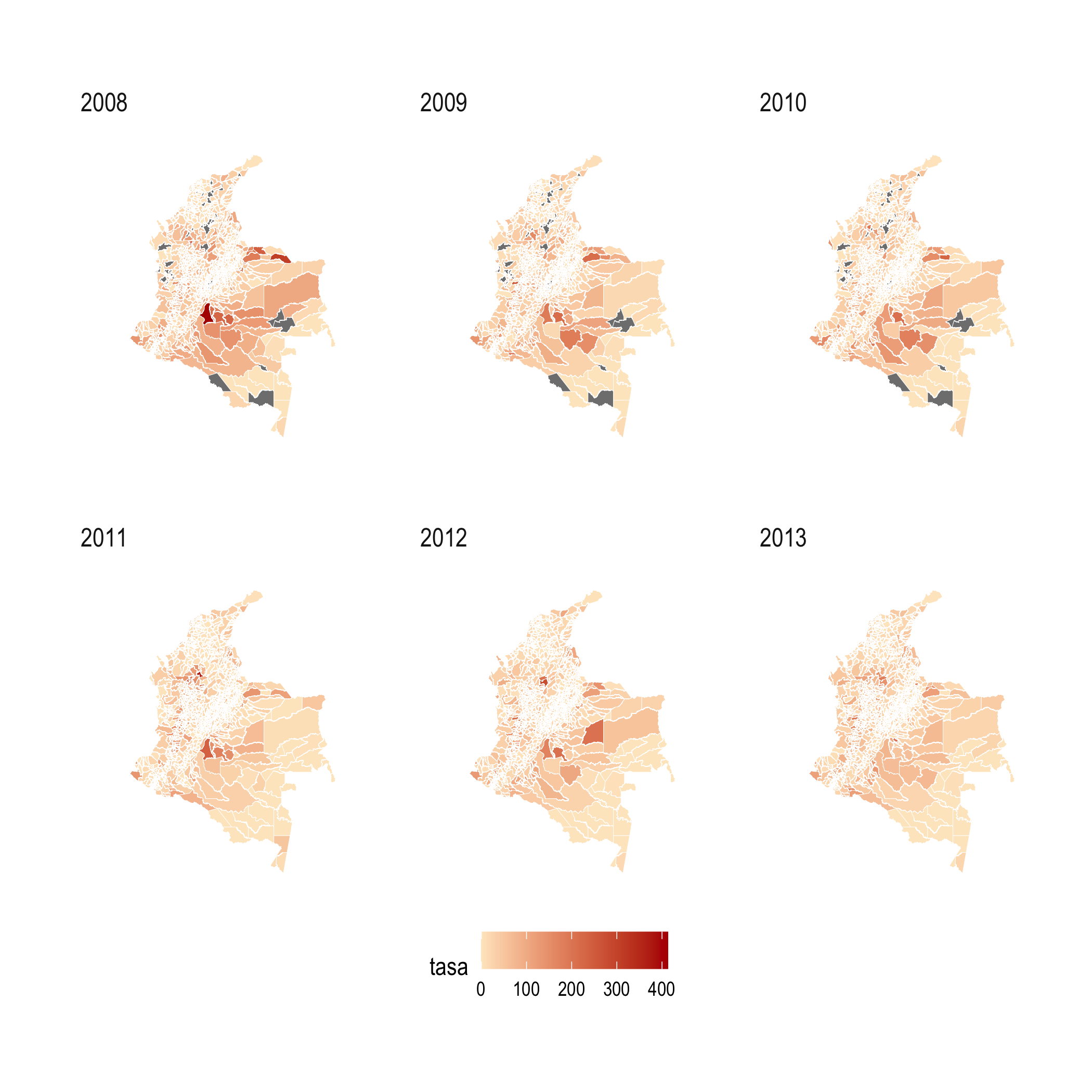
También existen numerosos paquetes que emplean la lógica de ggplot2 para ampliar sus funcionalidades, permitiendo nuevos tipos de visualizaciones. Por ejemplo, el paquete treemapify (Wilkins, 2021) con el que se construyó el treemap, reportado en la Figura 1.4. Otro ejemplo se presenta en al Figura 1.5, que fue creada con los paquetes colmaps (Moreno, 2015a) y homicidios (Moreno, 2015b) . En el Capítulo 2 estudiaremos la lógica detrás de la gramática de las visualizaciones que emplea ggplot2 y que podrás aplicar para otros paquetes como treemapify y colmaps.
Figura 1.4: Composición de la población mundial y esperanza de vida al nacer por país (2007)
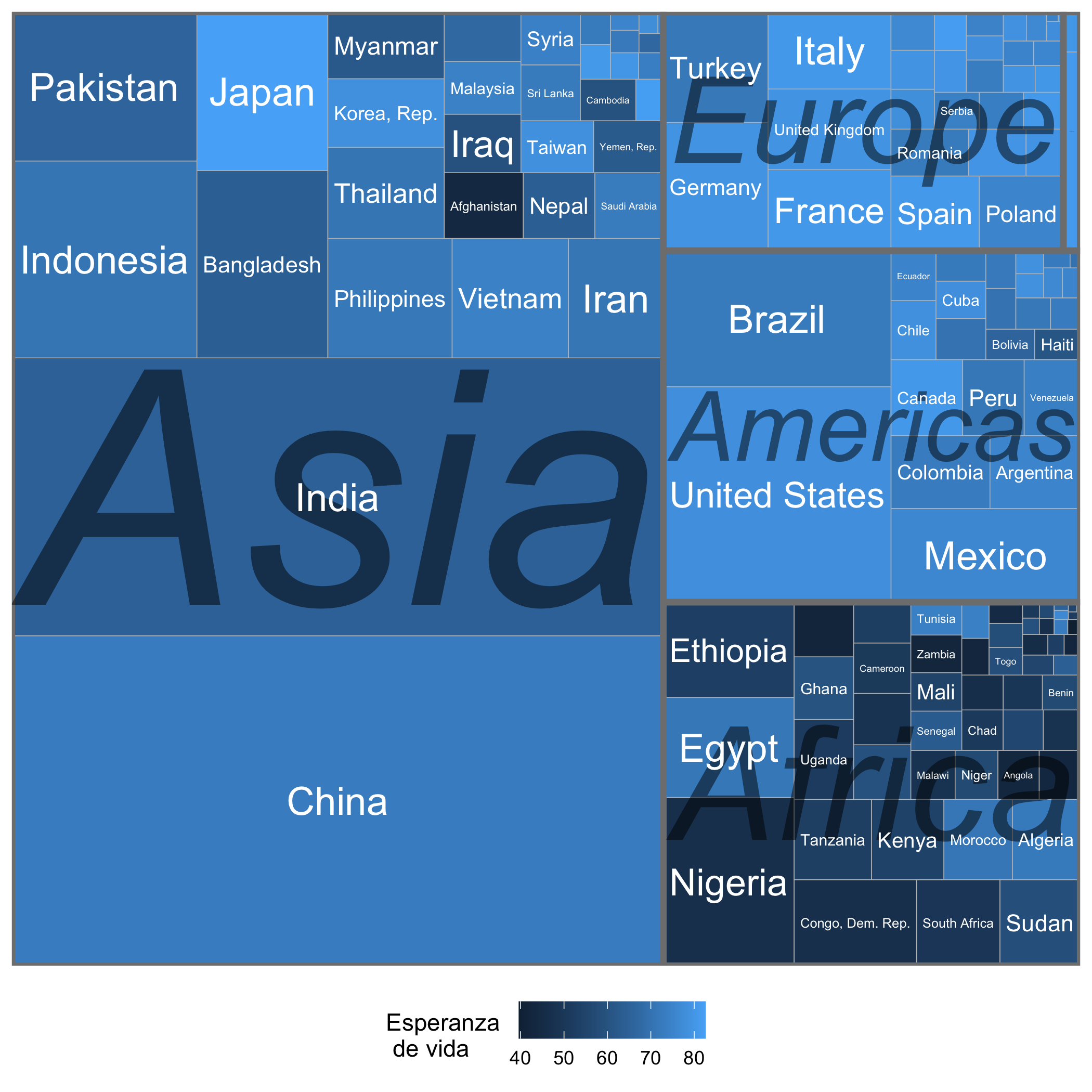
Figura 1.5: Evolución de la tasa municipal de homicidios (por mil habitantes)
Todas las visualizaciones, en últimas, obedecen a una “gramática”, como lo demuestra Wilkinson (2012). El paquete ggplot2 facilita la construcción de las visualizaciones permitiendo implementar dicha gramática en R. Precisamente, al usar esta gramática, el paquete ggplot2 es más intuitivo para el usuario que apenas está empezando en el universo de R.
En el Capítulo 2 analizaremos los elementos básicos de la gramática de los gráficos. En los Capítulos 3, 4 y 5 veremos los diferentes tipos de gráficos (que en este mundo se conoce como la geometría) y en el Capítulo 6 discutiremos unos trucos para mejorar la comunicación de nuestras visualizaciones.
Antes de entrar en los detalles de cómo realizar visualizaciones es importante entender la lógica que siguió el diseñador del paquete ggplot2. De hecho, este paquete hace parte de un conjunto de paquetes que se conocen como tidyverse4. Estos fueron diseñados para facilitar operaciones comunes de la ciencia de datos, permitiendo un flujo de trabajo continuo entre las diferentes tareas de carga, transformación, modelado y visualización de datos.
1.1 El universo tidyverse
Los paquetes que hacen parte de tidyverse5 tienen funciones que no solo permiten realizar tareas como la carga, transformación y visualización de datos, sino también la conexión entre dichas tareas6 (ver Sección 1.2).
Estos paquetes permiten optimizar el flujo de trabajo cuando empleamos datos para sacar conclusiones (ver Figura 1.6). El flujo de trabajo inicia7 desde la preparación y limpieza de los datos que previamente han sido recolectados y almacenados. Posteriormente se exploran los datos de manera gráfica y con estadísticas descriptivas, para pasar al modelado. Finalmente se comunican los resultados empleando visualizaciones y tablas.
Figura 1.6: Actividades y paquetes del Tidyverse en el flujo de trabajo del análisis de datos
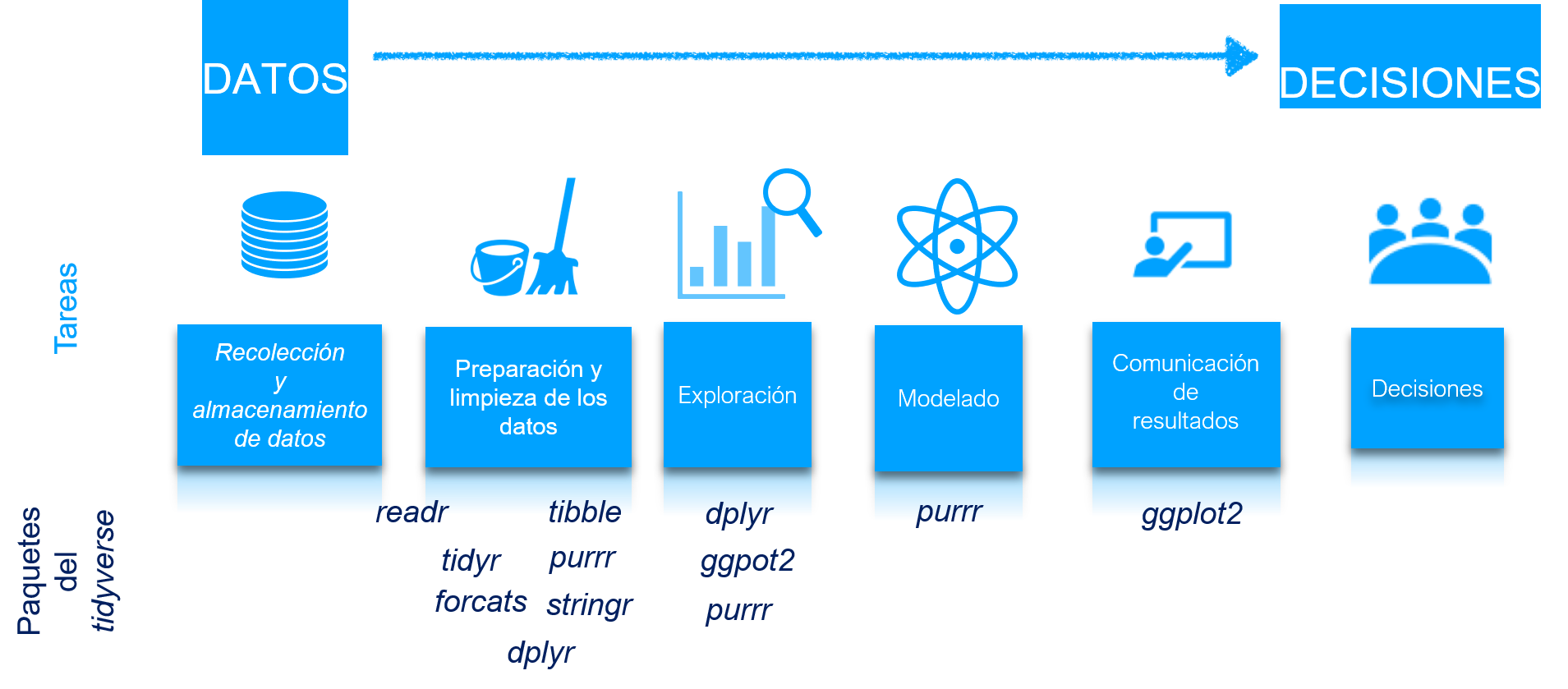
Los paquetes del tidyverse8 son:
readr (Wickham et al., 2018): lee datos de muchas fuentes (incluyendo formatos como .tsv y .fwf). Este paquete es útil para pasar de la actividad de recolección y almacenamiento de datos a la de preparación y limpieza (ver Figura 1.6).
tibble (Müller & Wickham, 2021): guarda bases de datos de la clase tibble (ver Capítulo 1 de Alonso (2022) para una discusión de esta clase de objetos). Las funciones de este paquete son útiles en la actividad de preparación y limpieza de datos (ver Figura 1.6).
tidyr (Wickham, Vaughan, et al., 2023): permite organizar un objeto con datos de clase data.frame o tibble. Este paquete es de especial utilidad en la actividad de preparación de datos (ver Figura 1.6).
stringr (Wickham, 2019): facilita el trabajo con datos que contienen carácteres (texto), lo cuál es conveniente en la limpieza de datos (ver Figura 1.6).
forcats (Wickham, 2020): facilita la preparación y limpieza de variables de clase factor (ver Figura 1.6).
purrr (Henry & Wickham, 2020): facilita la programación con funciones y vectores. Estas herramientas permiten eliminar los bucles (también conocidos como loops9), que son útiles en la ejecución de tareas repetitivas en la actividad de preparación, limpieza, exploración y modelado de datos (ver Figura 1.6).
dplyr (Wickham, François, et al., 2023): facilita el filtrado de observaciones, creación de variables y unión de objetos con datos por medio de una gramática de manipulación de datos. Para una discusión de este paquete puedes ver Alonso (2022). Este paquete es conveniente en la preparación, limpieza y exploración de los datos (ver Figura 1.6).
ggplot2 (Wickham, 2016): crea visualizaciones de datos siguiendo un gramática de capas, las cuales son útiles en las actividades de limpieza y exploración de datos y en la de comunicación de los resultados (ver Figura 1.6). Este libro se centra en este paquete.
Podemos emplear todas las funcionalidades del paquete ggplot2 sin necesidad de emplear los otros paquetes del tidyverse. Pero, en algunas ocasiones, emplear los otros paquetes de universo tidyverse simplifica el flujo de trabajo desde los datos originales hasta obtener la visualización. En este libro mantendremos al mínimo el uso de los otros paquetes del tidyverse; sin embargo, nos será difícil no emplearlos. En otras palabras, si bien evitaremos emplear el operador pipe (%>%), en algunas ocasiones será difícil no emplearlo para agilizar nuestro flujo de trabajo. Así mismo ocurrirá con los verbos de los otros 7 paquetes del tidyverse.
1.2 El operador pipe
Los paquetes del universo tidyverse emplean el operador pipe (%>%). Este operador permite poner en una “tubería” un objeto con datos y ejecutar diferentes operaciones sobre las observaciones (filas) o variables (columnas) sin tener que guardar los resultados intermedios. En otras palabras, el operador %>% permite encadenar resultados rápidamente. En Alonso (2022) encontrarás una presentación de este operador más detallada.
Veamos un ejemplo que emplea los datos del paquete gapminder (Bryan, 2017) (ver Capítulo 6 de Alonso & Ocampo (2022)). Este paquete tiene un objeto con datos con el mismo nombre, que contiene las siguientes variables: país (country), continente (continent), año (year), esperanza de vida al nacer (lifeExp), población (pop) y PIB percápita (gdpPercap). Los datos van desde 1952 a 2007 de a quinquenios. Carguemos los datos y explorémoslos.
# cargar paquete
# install.packages("gapminder")
library(gapminder)
# cargar datos
data("gapminder")
# cargar paquete
library(dplyr)
# Mirando los datos
glimpse(gapminder)## Rows: 1,704
## Columns: 6
## $ country <fct> "Afghanistan", "Afghanistan", "Afghanistan"…
## $ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, A…
## $ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1…
## $ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.…
## $ pop <int> 8425333, 9240934, 10267083, 11537966, 13079…
## $ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739…Supongamos que solo queremos trabajar con los promedios por continentes de la esperanza de vida al nacer para el 2007. Hacer esto con la base de R nos tomará bastantes pasos, pero con el paquete dplyr y el operador %>%, la tarea se simplifica mucho. Por ejemplo:
library(dplyr)
gapminder %>%
filter(year == 2007) %>%
group_by(continent) %>%
summarise(EV_prom = mean(lifeExp))## # A tibble: 5 × 2
## continent EV_prom
## <fct> <dbl>
## 1 Africa 54.8
## 2 Americas 73.6
## 3 Asia 70.7
## 4 Europe 77.6
## 5 Oceania 80.7El operador %>% pasa el resultado del último cálculo al primer argumento de la siguiente función, para que no sea necesario reescribirlo o guardarlo. Con este operador, los datos entran en una tubería (pipe), donde en cada paso se realiza un cálculo y al final solo se recibe el resultado. Recuerda, es necesario cargar el paquete dplyr o cualquiera del conjunto que hace parte de tidyverse (diferente a ggplot2) para usar el operador %>%.
1.3 Comentarios finales
Por su gran cantidad de usuarios, hay muchos ejemplos de visualizaciones creadas con ggplot2 disponibles en internet. Un buen ejemplo es la galería que se presenta en la The R Graph Gallery. Estas comunidades no solo presentan los ejemplos de las visualizaciones que podemos crear con este paquete, sino que es común que se provea el código que generó las visualizaciones. Después de finalizar la lectura de este libro, podrás entender esos códigos y adaptarlos para tu caso particular. También encontrarás en línea numerosos blogs10 y foros11 dedicados a responder dudas sobre errores en este paquete.
No podemos terminar este primer capítulo sin recordar que ggplot2 no es el único paquete para hacer gráficos. Dentro de la base (o core) de R hay otras opciones para “mapear” datos a una visualización, sin tener necesidad de recurrir a instalaciones externas. Lo que hace a este paquete tan especial es que obedece una gramática preestablecida en la estadística y lo traduce a programación de R. Esto hace que su implementación no sea tan compleja como puede llegar a ser la construcción de una visualización en la base de R. El siguiente capítulo te enseñará los elementos esenciales de la gramática de las visualizaciones.
Finalmente, al tener muchos usuarios de uso, existen numerosas comunidades de usuarios que se reflejan en diversas discusiones sobre la realización de gráficos de manera eficiente en los diferentes blogs de R.
Referencias
Puedes encontrar una breve descripción de la historia de R en el Capítulo 1 de Alonso & Ocampo (2022)↩︎
tidyverse (Wickham et al., 2019) es un paquete que contiene 8 paquetes.↩︎
Observa que tidy significa en español ordenado y verse es la parte final de universe (universo); de ahí que también se emplee la expresión universo Tidyverse.↩︎
Si deseas conocer mucho más del detalle de cómo fue diseñado este universo puedes consultar Wickham & Grolemund (2016) o la versión en línea del libro en el siguiente enlace: https://r4ds.had.co.nz.↩︎
Para una explicación breve de las actividades en el proceso de análisis de datos puedes ver el video en el siguiente enlace: https://youtu.be/rhLWa-vOxyU .↩︎
Para una descripción más detallada de cada uno de los paquetes se puede consultar Alonso (2022) .↩︎
Si quieres conocer sobre los loops en R, puedes consultar Alonso (2021) .↩︎
Por ejemplo, R-Blogger es un sitió que se dedica a recoger entradas de diferentes blogs de la comunidad de R ( https://www.r-bloggers.com ).↩︎
Por ejemplo, Stackoverflow es un foro muy común para usuarios en R que tiene una sección especial para ggplot ( https://stackoverflow.com/questions/tagged/ggplot2 ).↩︎