3 Tabajando con variables
Es rutinario para los científicos de datos, o persona que quiera analizar datos, construir nuevas variables y descartar algunas del análisis.
En el capítulo anterior, estudiamos los verbos del paquete dplyr para trabajar con las observaciones. En este capítulo trabajaremos sobre las columnas (variables) de un objeto de clase tibble o data.frame.
En este capítulo emplearemos unos datos que podrían ser considerados grandes. Usaremos datos que incluyen todas las canciones que han estado en el Top 200 de las listas semanales (Global) de Spotify en 2020 y 2021, y algunas características de las canciones (Pillai, 2021). La base de datos se encuentra en el archivo spotify_dataset.csv15.
La base cuenta con 1556 observaciones con las siguientes 23 variables:
Highest.Charting.Position: la posición más alta en la que ha estado la canción en las listas semanales de Spotify Top 200 Global Charts en 2020 y 2021.Number.of.Times.Charted: el número de veces que la canción ha estado en la lista de las 200 mejores canciones semanales de Spotify en 2020 y 2021.Week.of.Highest.Charting: la semana en la cual la canción tuvo la posición más alta en las listas globales semanales de las 200 mejores canciones de Spotify en 2020 y 2021.Song.Name: el nombre de la canción que ha estado en las Top 200 Weekly Global Charts de Spotify en 2020 & 2021.Song.ID: el ID de la canción proporcionado por Spotify (único para cada canción).Streams: el número aproximado de streams que tiene la canción.Artist: el artista o artistas principales que han participado en la elaboración de la canción.Artist.Followers: el número de seguidores que tiene el artista principal en Spotify.Genre: los géneros a los que pertenece la canción.Release.Date: la fecha inicial de lanzamiento de la canción.Weeks.Charted: las semanas que la canción ha estado en el Top 200 de las listas semanales de Spotify en 2020 y 2021.Popularity: la popularidad de la canción. El valor estará entre 0 y 100, siendo 100 la más popular.Danceability: la bailabilidad describe lo adecuado que es un tema para bailar basándose en una combinación de elementos musicales que incluyen el tempo, la estabilidad del ritmo, la fuerza del compás y la regularidad general. Un valor de 0,0 es el menos bailable y 1,0 es el más bailable.Acousticness: una medida de 0,0 a 1,0 de si la pista es acústica.Energy: la energía es una medida de 0,0 a 1,0 y representa una medida perceptiva de intensidad y actividad. Normalmente, las pistas energéticas se sienten rápidas, fuertes y ruidosas.Liveness: detecta la presencia de público en la grabación. Los valores más altos delivenessrepresentan una mayor probabilidad de que la pista haya sido interpretada en directo.Loudness: la sonoridad general de una pista en decibelios (dB). Los valores de sonoridad se promedian en toda la pista. Los valores suelen oscilar entre -60 y 0 db.Speechiness: la expresividad detecta la presencia de palabras habladas en una pista. Cuanto más exclusivamente hablada sea la grabación (por ejemplo, un programa de entrevistas, un audiolibro o una poesía), más se acercará a 1,0 el valor del atributo.Tempo: el tempo global estimado de una pista en pulsaciones por minuto (BPM). En la terminología musical, el tempo es la velocidad o el ritmo de una pieza determinada y se deriva directamente de la duración media de los tiempos.Duration..ms.: duración de la canción en milisegundos.Valence: una medida de 0,0 a 1,0 que describe la positividad musical que transmite una pista. Las pistas con valencia alta suenan más positivas (por ejemplo, felices, alegres, eufóricas), mientras que las pistas con valencia baja suenan más negativas (por ejemplo, tristes, deprimidas, enfadadas).Chord: el acorde principal de la canción instrumental.
Antes de entrar en la discusión de los verbos carguemos la base de datos en un objeto de clase tibble, al cual llamaremos spotify.
# Carga de bases de datos
spotify <- read.csv("spotify_dataset.csv",
header = TRUE, sep = ",")
# mirar la clase del objeto
class(spotify)## [1] "data.frame"# cambiando a clase tibble
library(dplyr)
spotify <- as_tibble(spotify)Asegúrate de que el objeto spotify tenga 1556 observaciones y 23 variables. Esto lo puedes hacer con el verbo glimpse() del paquete dplyr. Este verbo, que en español sería vislumbrar o dar una mirada rápida, se puede utilizar para ver las columnas (variables) del objeto, al tiempo que se muestran los datos que puedan caber en una sola línea. Así mismo, podemos ver la clase de cada variable. ¡Inténtalo!
3.1 Seleccionar
En algunas ocasiones es deseable trabajar con un conjunto de datos que tenga reducido número de variables. Para seleccionar un grupo de variables se puede emplear el verbo select(). Siguiendo la gramática del paquete dplyr, el primer argumento de la función select() es el objeto de clase tibble o data.frame que se puede pasar empleando el operador%>%. Los siguientes argumentos son las variables que se quieren seleccionar. En la Figura 3.1 se presenta de manera esquemática el procedimiento efectuado cuando se emplea el verbo select en un objeto con datos.
Figura 3.1: Representación del proceso de seleccionar (select()) aplicado a un objeto de clase data.frame o tibble
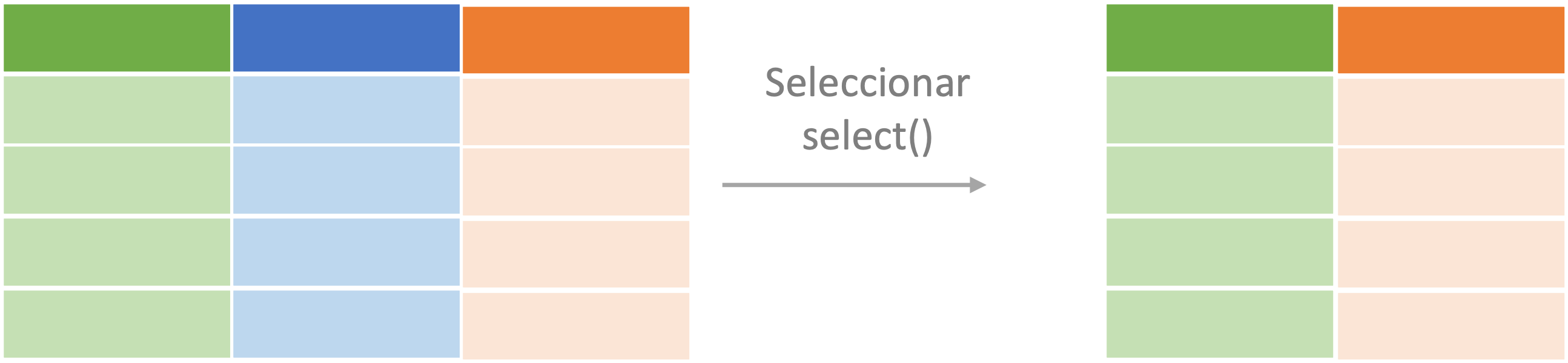
Supongamos que queremos crear un nuevo objeto con datos que solo tenga las variables Song.Name, Genre y Streams. Esto lo podemos hacer con el siguiente código.
spotify %>%
select(Song.Name, Genre, Streams) %>%
glimpse()## Rows: 1,556
## Columns: 3
## $ Song.Name <chr> "Beggin'", "STAY (with Justin Bieber)", "go…
## $ Genre <chr> "['indie rock italiano', 'italian pop']", "…
## $ Streams <int> 48633449, 47248719, 40162559, 37799456, 339…Regresando a este ejemplo, es importante anotar que podemos combinar verbos que actúen sobre variables y observaciones en un mismo pipe. Por ejemplo, supongamos que queremos construir una base que tenga solo las variables Song.Name y Streams, pero sólo de aquellas canciones que pertenecen al género pop. Esto implicará, primero filtrar el objeto spotify por género (Genre == "['pop']"), y luego seleccionar las variables deseadas. El siguiente código efectuará estas operaciones:
spotify_pop <- spotify %>%
filter(Genre == "['pop']") %>%
select(Song.Name, Streams)
# mirando los resultados
glimpse(spotify_pop)## Rows: 18
## Columns: 2
## $ Song.Name <chr> "good 4 u", "traitor", "deja vu", "drivers …
## $ Streams <int> 40162559, 19480679, 18571755, 15684978, 148…El verbo select lo podemos complementar con otros que agilizarán nuestro flujo de trabajo. Por ejemplo, está el verbo contains() que permite seleccionar todas las variables que contengan uno o varios carácteres deseados. En particular, supongamos que queremos seleccionar todas las variables que tienen un punto (.) en su nombre16. Esto lo podemos hacer de la siguiente manera:
spotify_punto <- select(spotify, contains("."))
# mirando los resultados
glimpse(spotify_punto)## Rows: 1,556
## Columns: 9
## $ Highest.Charting.Position <int> 1, 2, 1, 3, 5, 1, 3, 2, 3, …
## $ Number.of.Times.Charted <int> 8, 3, 11, 5, 1, 18, 16, 10,…
## $ Week.of.Highest.Charting <chr> "2021-07-23--2021-07-30", "…
## $ Song.Name <chr> "Beggin'", "STAY (with Just…
## $ Artist.Followers <int> 3377762, 2230022, 6266514, …
## $ Song.ID <chr> "3Wrjm47oTz2sjIgck11l5e", "…
## $ Release.Date <chr> "2017-12-08", "2021-07-09",…
## $ Weeks.Charted <chr> "2021-07-23--2021-07-30\n20…
## $ Duration..ms. <int> 211560, 141806, 178147, 231…Puedes observar que se obtiene un objeto con las 9 variables cuyos nombres contienen un punto (.). En el Cuadro 3.1 se presentan algunas de las funciones que se pueden emplear con el verbo delect().
| Función | Variables seleccionadas |
|---|---|
| contains() | Con nombre que contiene una cadena de caracteres. |
| ends_with() | Con nombre que termina con una cadena de caracteres. |
| starts_with() | Con nombre que inicia con una cadena de caracteres. |
| last_col() | La última. |
| everything() | Todas. |
| num_range() | En un rango de variables que crea la misma función. Por ejemplo, select(num_range("x", 1:5)) selecciona las variables con nombres x1, x2, x3, x4 y x5. |
| one_of() | Con nombres en un grupo de nombres. recuerda poner el grupo como una lista empleando c() |
También podemos emplear operadores como los dos puntos (:) con el verbo select() para escoger un rango de variables que estén adyacentes. Por ejemplo, para seleccionar las variables que están entre Acousticness y Valence puede hacerse con el siguiente código que evita digitar el nombre de todas las variables deseadas:
spotify %>%
select(Acousticness:Valence) %>%
glimpse()## Rows: 1,556
## Columns: 5
## $ Acousticness <dbl> 0.12700, 0.03830, 0.33500, 0.04690, 0.0…
## $ Liveness <dbl> 0.3590, 0.1030, 0.0849, 0.3640, 0.0501,…
## $ Tempo <dbl> 134.002, 169.928, 166.928, 126.026, 149…
## $ Duration..ms. <int> 211560, 141806, 178147, 231041, 212000,…
## $ Valence <dbl> 0.5890, 0.4780, 0.6880, 0.5910, 0.8940,…También es posible emplear el operador signo de exclamación (!) para escoger las variables que no correspondan a un conjunto de variables. Por ejemplo, supongamos que queremos excluir las variables que están entre Song.Name y Chord en el objeto original. Esto lo podemos hacer de la siguiente manera:
spotify_red <- select(spotify, !Song.Name:Chord)
# mirando los resultados
glimpse(spotify_red)## Rows: 1,556
## Columns: 4
## $ Index <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, …
## $ Highest.Charting.Position <int> 1, 2, 1, 3, 5, 1, 3, 2, 3, …
## $ Number.of.Times.Charted <int> 8, 3, 11, 5, 1, 18, 16, 10,…
## $ Week.of.Highest.Charting <chr> "2021-07-23--2021-07-30", "…El mismo resultado se logra con el siguiente código:
spotify_red <- select(spotify, -c(Song.Name:Chord))Esta ultima líneas de código es una forma de expresarnos más parecida a lo que habitualmente se acostumbra en la base de R para no seleccionar columnas de una matriz o data.frame.
3.2 Crear variables nuevas (Mutar)
En otras ocasiones, podemos querer crear nuevas variables a partir de operaciones de otras columnas. Para usar la jerga de dplyr, necesitamos mutar variables ya existentes en otras. Esto puede hacerse con el verbo mutate() . El primer argumento de esta función es el objeto con los datos y los restantes corresponden a las nueva variables que se quieran crear. Las nuevas variables se especifican con su nuevo nombre y la operación que se desea realizar. En la Figura 3.2 se presenta de manera esquemática el procedimiento efectuado cuando empleamos el verbo mutate.
Figura 3.2: Representación del proceso de mutar (mutate())
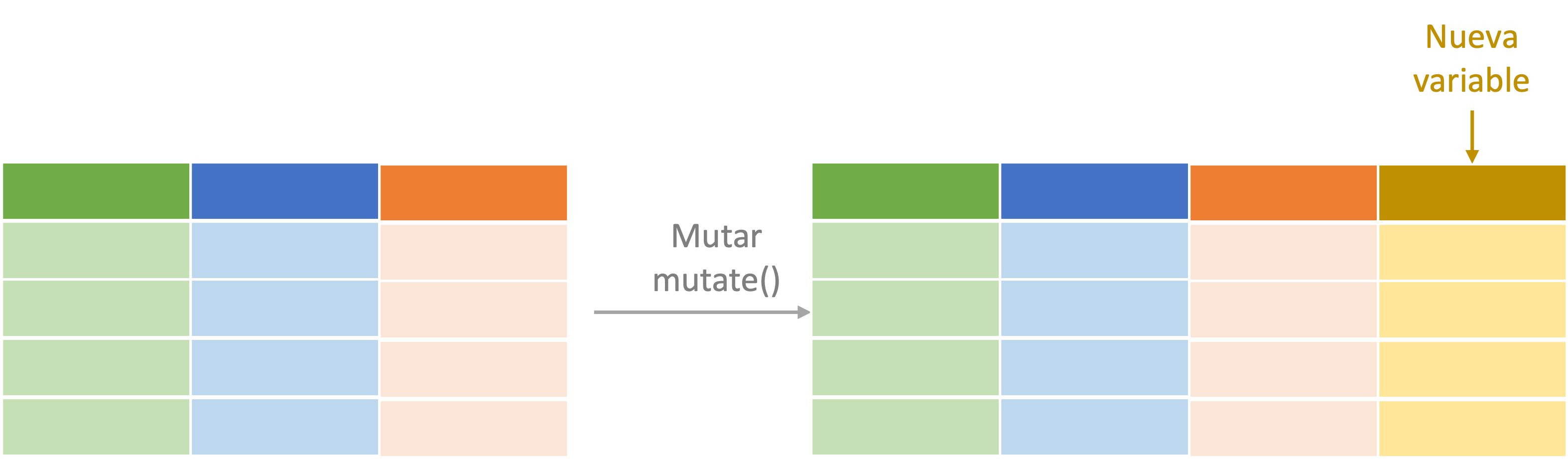
Por ejemplo, supongamos que queremos conocer cuántas reproducciones tiene cada canción por seguidor del artista principal en Spotify. Es decir, la división de la variable Streams por Artist.Followers. Esto lo podemos hacer rápidamente de la siguiente manera:
spotify %>%
mutate(Rep_follow = Streams / Artist.Followers) %>%
glimpse()## Rows: 1,556
## Columns: 24
## $ Index <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, …
## $ Highest.Charting.Position <int> 1, 2, 1, 3, 5, 1, 3, 2, 3, …
## $ Number.of.Times.Charted <int> 8, 3, 11, 5, 1, 18, 16, 10,…
## $ Week.of.Highest.Charting <chr> "2021-07-23--2021-07-30", "…
## $ Song.Name <chr> "Beggin'", "STAY (with Just…
## $ Streams <int> 48633449, 47248719, 4016255…
## $ Artist <chr> "Måneskin", "The Kid LAROI"…
## $ Artist.Followers <int> 3377762, 2230022, 6266514, …
## $ Song.ID <chr> "3Wrjm47oTz2sjIgck11l5e", "…
## $ Genre <chr> "['indie rock italiano', 'i…
## $ Release.Date <chr> "2017-12-08", "2021-07-09",…
## $ Weeks.Charted <chr> "2021-07-23--2021-07-30\n20…
## $ Popularity <int> 100, 99, 99, 98, 96, 97, 94…
## $ Danceability <dbl> 0.714, 0.591, 0.563, 0.808,…
## $ Energy <dbl> 0.800, 0.764, 0.664, 0.897,…
## $ Loudness <dbl> -4.808, -5.484, -5.044, -3.…
## $ Speechiness <dbl> 0.0504, 0.0483, 0.1540, 0.0…
## $ Acousticness <dbl> 0.12700, 0.03830, 0.33500, …
## $ Liveness <dbl> 0.3590, 0.1030, 0.0849, 0.3…
## $ Tempo <dbl> 134.002, 169.928, 166.928, …
## $ Duration..ms. <int> 211560, 141806, 178147, 231…
## $ Valence <dbl> 0.5890, 0.4780, 0.6880, 0.5…
## $ Chord <chr> "B", "C#/Db", "A", "B", "D#…
## $ Rep_follow <dbl> 14.3981278, 21.1875573, 6.4…Esto crea un objeto de datos igual al original e incluye la variable nueva Rep_follow como última columna.
Con el verbo mutate podemos emplear los operadores aritméticos, de relación y lógicos del paquete base de R17, así como las funciones aritméticas y matemáticas como log() y sqrt(). Además, se pueden emplear funciones especiales que trae este verbo. En el Cuadro 3.2 se presentan algunas de dichas funciones.
| Función | Operación |
|---|---|
| lag(n=1) | Trae la observación anterior de la variable. Si se desean dos observaciones atrás, entonces n=2. |
| lead(n=1) | Trae la siguiente observación de la variable. Si se desean dos observaciones adelante, entonces n=2. |
| cume_dist() | Calcula la proporción de observaciones menores o iguales a cada uno de los valores de la variable. La distribución acumulada. |
| cumsum() | Calcula la suma acumulada hasta esta observación de todas las observaciones anteriores de la variable. |
3.3 Otras operaciones con variables
En algunas oportunidades veremos la necesidad de renombrar variables. El verbo rename() permite cambiar el nombre de una o más variables. Después de especificar el objeto que tiene los datos en el primer argumento de la función, solo se necesita especificar el nuevo nombre de la variable y el nombre original.
Veamos un ejemplo: supongamos que queremos cambiarle el nombre a la variable Artist.Followers a Artist_Followers, dado que es una mala práctica emplear el punto (.) en el nombre de una variable. Esto lo podemos hacer con la siguiente línea de código:
spotify_rename <- rename(spotify,
Artist_Followers = Artist.Followers)
# mirando solo los nombres de las variables
names(spotify_rename)## [1] "Index" "Highest.Charting.Position"
## [3] "Number.of.Times.Charted" "Week.of.Highest.Charting"
## [5] "Song.Name" "Streams"
## [7] "Artist" "Artist_Followers"
## [9] "Song.ID" "Genre"
## [11] "Release.Date" "Weeks.Charted"
## [13] "Popularity" "Danceability"
## [15] "Energy" "Loudness"
## [17] "Speechiness" "Acousticness"
## [19] "Liveness" "Tempo"
## [21] "Duration..ms." "Valence"
## [23] "Chord"Otra función relacionada con esta que puede ser útil para automatizar cambios de muchas variables a la vez es rename_with() . Esta función permite renombrar las variables de un objeto empleando funciones. Por ejemplo, podemos utilizar la función toupper() para pasar todos los nombres de las variables a solo mayúsculas (en inglés upper case).
spotify_upper1 <- rename_with(spotify, toupper)
# mirando solo los nombres de las variables
names(spotify_upper1)## [1] "INDEX" "HIGHEST.CHARTING.POSITION"
## [3] "NUMBER.OF.TIMES.CHARTED" "WEEK.OF.HIGHEST.CHARTING"
## [5] "SONG.NAME" "STREAMS"
## [7] "ARTIST" "ARTIST.FOLLOWERS"
## [9] "SONG.ID" "GENRE"
## [11] "RELEASE.DATE" "WEEKS.CHARTED"
## [13] "POPULARITY" "DANCEABILITY"
## [15] "ENERGY" "LOUDNESS"
## [17] "SPEECHINESS" "ACOUSTICNESS"
## [19] "LIVENESS" "TEMPO"
## [21] "DURATION..MS." "VALENCE"
## [23] "CHORD"También podemos jugar un poco más con esta función y las otras que ya conocemos, por ejemplo,
spotify_upper2 <- rename_with(spotify, toupper, contains("."))
# mirando solo los nombres de las variables
names(spotify_upper2)## [1] "Index" "HIGHEST.CHARTING.POSITION"
## [3] "NUMBER.OF.TIMES.CHARTED" "WEEK.OF.HIGHEST.CHARTING"
## [5] "SONG.NAME" "Streams"
## [7] "Artist" "ARTIST.FOLLOWERS"
## [9] "SONG.ID" "Genre"
## [11] "RELEASE.DATE" "WEEKS.CHARTED"
## [13] "Popularity" "Danceability"
## [15] "Energy" "Loudness"
## [17] "Speechiness" "Acousticness"
## [19] "Liveness" "Tempo"
## [21] "DURATION..MS." "Valence"
## [23] "Chord"Nota que solo pasamos a mayúsculas las variables cuyos nombres contienen un punto (.). Ahora puedes intentar con diferentes opciones.
Finalmente, consideremos el verbo transmute() , este es una combinación de los verbos select() y mutate(). Es decir, nos permite seleccionar un conjunto de variables al mismo tiempo que se crean otras nuevas. En la Figura 3.3 se presenta de manera esquemática el procedimiento efectuado cuando se empleamos el verbo transmutar.
Figura 3.3: Representación del proceso de transmutar (transmute()).
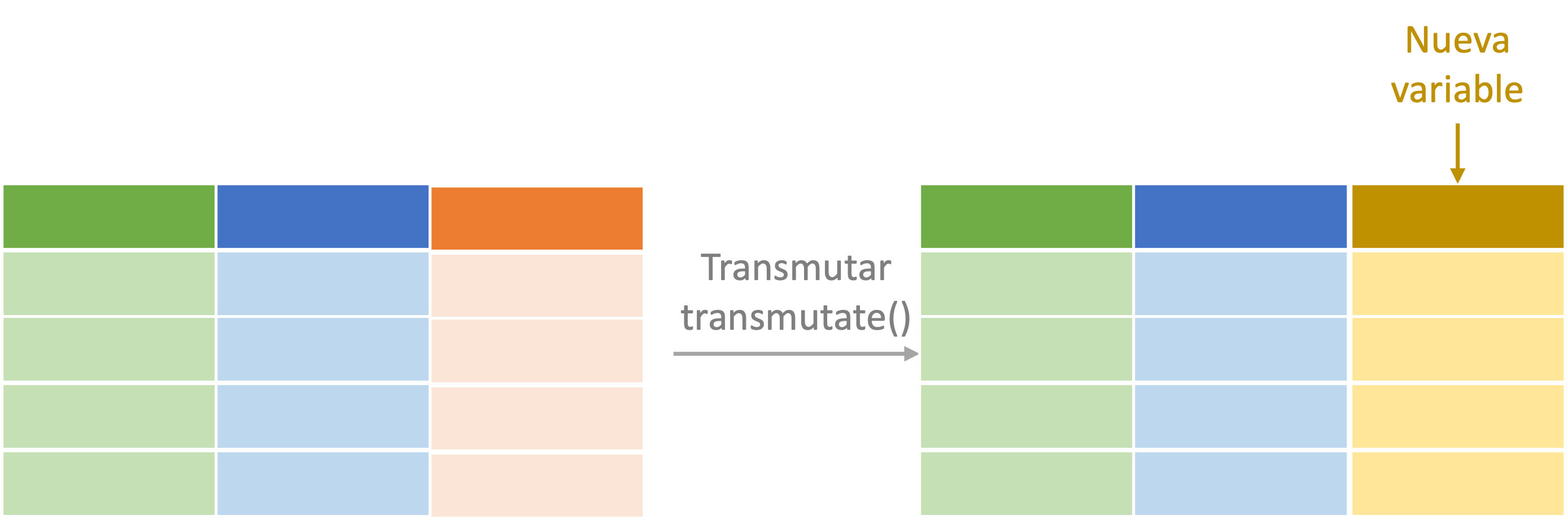
Supongamos que deseamos crear la variable de reproducciones de cada canción por seguidor del artista principal en Spotify (antes la definimos como Rep_follow). Además, queremos una base que solo tenga el nombre de la canción (Song.Name), el género (Genre), las reproducciones (Streams) y la nueva variable creada (Rep_follow). Esto lo logramos con el siguiente código:
spotify_t <- transmute(spotify, Song.Name,
Genre, Streams,
Rep_follow = Streams / Artist.Followers)
# mirando solo los nombres de las variables
names(spotify_t)## [1] "Song.Name" "Genre" "Streams" "Rep_follow"3.4 Comentarios finales
En este capítulo discutimos cuatro verbos que nos permiten trabajar con variables: select(), mutate(), rename() y transmute(). Estas funciones posibilitan seleccionar un subconjunto de variables, crear nuevas variables y renombrarlas. De hecho, estos verbos están relacionados entre sí. Lo que tienen en común select() y transmute(), es que generan un objeto solo con las variables especificadas. Por otro lado, los verbos rename() y mutate() tienen en común que el resultante conjunto de datos tiene todas las columnas que ya estaban en el objeto original.
Si combinamos estos verbos con aquellos que permiten filtrar observaciones, tenemos una herramienta muy potente para transformar cualquier objeto de datos, sin importar su tamaño, de acuerdo con nuestras necesidades. En el próximo capítulo discutiremos cómo unir dos objetos con datos empleando los verbos de dplyr.
Referencias
El archivo lo puedes descargar de la página web del libro (http://www.icesi.edu.co/editorial/empezando-transformar).↩︎
Esto no tiene mucho sentido en este contexto, pero el verbo puede ser útil en otros contextos.↩︎
Puedes ver el Capítulo 4 de Alonso Cifuentes & Ocampo (2022) para una discusión de estos operadores.↩︎