1 El paquete dplyr
R (R Core Team, 2020) es un lenguaje de programación de uso libre con una gran comunidad a nivel mundial. La base (o también conocido como el core) de R es muy potente, permite trabajar con datos grandes y pequeños. El core de R permite separar filas (filtrar observaciones), transformar columnas (transformar variables) y unir objetos con datos. Pero estas tareas de filtrar y transformar empleando la base de R, puede ser al principio un poco tedioso. El paquete dplyr (Wickham et al., 2021) permite simplificar el proceso de filtrado de observaciones y transformación de variables. Así mismo, este paquete puede ser mas intuitivo para el usuario que apenas está empezando en el universo de R2.
Antes de entrar en los detalles de cómo filtrar observaciones (ver Capítulo 2), transformar columnas (ver Capítulo 3) o unir objetos con datos (ver Capítulo 4), es importante entender la lógica que sigue el código que emplean las funciones del paquete dplyr. En este capítulo nos concentraremos en las generalidades de la filosofía, gramática y estructura detrás del paquete.
1.1 El Universo tidyverse
El paquete dplyr hace parte de un conjunto de paquetes que se conocen como tidyverse3 . Los cuales fueron diseñados para facilitar operaciones comunes de la ciencia de datos y permitir, de una manera ordenada4, un flujo de trabajo entre las diferentes tareas.
Los paquetes que hacen parte de tidyverse tienen funciones que permiten la gestión, el ordenamiento, la lectura (y escritura), el análisis sintáctico y la visualización de datos, entre muchas otras tareas5. Los paquetes son:
dplyr: proporciona una gramática de manipulación de datos. Como lo discutiremos en este libro, el paquete emplea un conjunto de “verbos” que facilitan la manipulación de datos.
ggplot2 (Wickham, 2016): crea gráficos siguiendo un gramática de capas. En Alonso & Largo (2022) encontrarás una breve introducción a este paquete.
tidyr (Wickham, 2021): proporciona un conjunto de funciones para transformar la organización de un objeto con datos de clase data.frame o tibble.
readr (Wickham et al., 2018): lee datos de archivos planos de numerosos formatos de manera mas amigable y rápida que la base de R. No solo lee archivos en formato
.csv(valores separado por comas, en inglés comma-separated values), sino qué también archivos en formato.tsv(valores separados por tabuladores, en inglés tab-separated values ) o.fwf(de ancho fijo, en inglés fixed-width files). Estos formatos se emplean típicamente para almacenar grandes volúmenes de información.purrr (Henry & Wickham, 2020): brinda herramientas que facilitan la programación con funciones y vectores, estas permiten eliminar los bucles (también conocidos como loops6).
tibble (Müller & Wickham, 2021): brinda una alternativa para guardar las bases de datos que complementa la clase data.frame, creando lo que se conoce como tibbles (lo discutiremos mas adelante en la sección 1.2.2).
stringr (Wickham, 2019): proporciona funciones que facilitan el trabajo con cadenas de carácteres (texto).
forcats (Wickham, 2020): proporciona funciones para resolver problemas que se presentan con la manipulación de variables de clase factor.
En la siguiente sección exploraremos la sintaxis básica para trabajar con estos paquetes.
1.2 Consideraciones básicas de la sintaxis en el tidyverse
El paquete dplyr, como parte del universo tidyverse, tiene dos características importantes que estaremos empleando. Por un lado, emplea el operador pipe (en español sería tubería) y objetos con datos de la clase tibble. Veamos cada uno de estos elementos.
1.2.1 El operador pipe
Los paquetes del universo tidyverse tienen la peculiaridad de que permiten poner en una “tubería” un objeto con datos y ejecutar diferentes operaciones sobre las observaciones (filas) o variables (columnas), sin tener que guardar los resultados intermedios. El operador pipe ( %>%) permite encadenar resultados rápidamente, de manera que se pueden ejecutar varios comandos de manera fácil e intuitiva.
Veamos un ejemplo: supongamos que se desea sacar la raíz cuadrada de un número, luego al resultado calcularle el logaritmo natural, y finalmente, redondear el resultado para obtener una solución con dos decimales. Esto implica emplear tres funciones: sqrt() , log() y round(). Usando la base de R podemos hacer esto de numerosas maneras, una sería la siguiente:
r1 <- sqrt(65)
r2 <- log(r1)
round(r2, digits = 2)## [1] 2.09Otra manera de hacer lo mismo, sin guardar un objeto intermedio, sería la que se muestra en la siguiente línea:
round(log(sqrt(65)), digits = 2)## [1] 2.09Observa que el segundo caso es ideal para no guardar los resultados intermedios en memoria (en especial si hablamos de cálculos en el mundo del Big Data). Pero si quisiéramos encadenar muchos comandos, esto se volvería engorroso y el código sería difícil de seguir.
Aquí es cuando el operador pipe ( %>%) de los paquetes del tidyverse pueden facilitar las tareas. El operador %>% pasa el resultado del último cálculo al primer argumento de la siguiente función, así no es necesario reescribirlo o guardarlo. Es como si los datos entrasen a una tubería (pipe) de un proceso de producción y al final solo recibiéramos el producto terminado.
Para el anterior ejemplo, el código empleando el operador %>% de estas librerías sería el siguiente:
# cargando la librería
# (recuerda instalarla si no lo has hecho antes)
# installpackages("dplyr")
library(dplyr)
# operación usando el operador pipe
# entran los datos al pipe
65 %>%
# se calcula la raíz cuadrada
sqrt() %>%
# se calcula el log
log() %>%
# se redondea
round( digits = 2) ## [1] 2.09Nota que es necesario cargar el paquete dplyr o cualquiera del conjunto que hace parte de tidyverse para usar el operador %>%. Este ejemplo nos permite ver además que el resultado de la operación anterior se reemplaza en el primer argumento de la siguiente función, y los otros argumentos sí debemos especificarlos. También es importante anotar que no todas las funciones son “amigables” al uso del operador %>%, pero afortunadamente todas las funciones del core en R sí lo son, y un buen número de funciones en diferentes paquetes son escritas de manera que se puede emplear este operador.
Este pequeño ejemplo muestra que encadenar comandos en R, solo usando el paquete base, puede ser bastante complicado. El operador %>% del tidyverse facilita la vida para realizar estos encadenamientos.
Recomendación de Estilo
El operador %>% debe tener siempre un espacio por delante y la siguiente operación deberá ir en una línea nueva. Después del primer paso, cada línea debe tener sangría de dos espacios. Esta estructura facilita la lectura del código, la adición de nuevos pasos, la reorganización de los ya existentes y deja en claro cada uno de los pasos al interior de la tubería.
# Buena práctica
65 %>%
sqrt() %>%
log() %>%
round(,digits = 2)
# Mala práctica
65 %>% sqrt() %>% log() %>% round(,digits = 2)
Recomendación de Estilo
No tiene sentido hacer tuberías de un solo paso.
# Buena práctica
sqrt(65)
# Mala práctica
65 %>%
sqrt()
Antes de continuar, es importante conocer un truco de RStudio7 para digitar el operador pipe (%>%). Este operador se puede generar en la consola o en un script presionando las teclas command + shift + M al mismo tiempo. ¡Inténtalo!, esto te ahorrará mucho tiempo.
1.2.2 La clase tibble
La clase tibble se puede entender como una clase de objeto similar al data.frame para almacenar bases de datos. En ambos casos, las columnas representan variables y las filas observaciones. Las diferencias principales entre estas dos clases de objetos son:
Un objeto tibble pueden tener números y símbolos en los nombres de las variables (columnas), mientras que el data.frame típicamente no lo permite.
Cuando se llama un objeto tibble en la consola, el resultado que se obtiene solo son las 10 primeras filas y todas las columnas que caben en la consola. En el caso de un objeto data.frame, se presentan en la consola todos los datos, o si usas RStudio, se presentan hasta 1000 líneas en la consola. Si esta es muy grande, serán difícil de visualizar los datos. Adicionalmente, sólo en el caso del objeto tible, además de su nombre, cada columna informa su clase (tal como lo haría la función str() ).
Al extraer un subconjunto de variables de un objeto tibble, siempre se obtendrá otro tibble. Para un objeto de clase data.frame al extraer un subconjunto de variables, se podrá obtener un data.frame o a veces un vector.
Un objeto de clase tibble puede tener una columna (variable) de clase list, en un data.frame no es posible.
Trabajemos con un objeto tible. Recuerda que la mayoría de los paquetes traen bases de datos (ver Capítulo 6 de Alonso Cifuentes & Ocampo (2022)) y algunas de esa bases de datos ya están en formato tibble. Por ejemplo, el paquete gapminder (Bryan, 2017) tiene un objeto con datos con el mismo nombre. El objeto gapminder tiene datos para la mayoría de los países del mundo de población, PIB per cápita y esperanza de vida. Veamos rápidamente las características que enunciamos arriba con esta base.
Carga el paquete y los datos y asegúrate que el objeto sea de clase tibble.
# cargar paquete
# install.packages("gapminder")
library(gapminder)
# cargar datos
data("gapminder")
# clase
class(gapminder)## [1] "tbl_df" "tbl" "data.frame"Nota que el objeto tibble se reporta en la consola como tbl_df y también como data.frame. Veamos qué ocurre cuando escribimos el nombre del objeto en la consola.
gapminder## # A tibble: 1,704 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # … with 1,694 more rowsDe hecho, es muy fácil convertir un objeto de clase tibble a data.frame y viceversa. Por ejemplo, podemos emplear a función as.data.frame() del core de R para convertir el objeto gapminder a data.frame.
# convertir a data.frame
gapminder.df2 <- as.data.frame(gapminder)
# clase del objeto
class(gapminder.df2)## [1] "data.frame"Ahora invoca en la consola el objeto gapminder.df2 y verás la diferencia.
Si quieres convertir un objeto de clase data.frame a tibble puedes emplear la a función as_tibble() del paquete tibble.
Todas las funciones de dplyr (y también de tidyverse) que generan bases de datos, lo harán en formato tibble. Así mismo, las funciones que veremos en los siguientes capítulos para manipular bases de datos pueden tomar como argumento, tanto objetos de clase tibble como de clase data.frame.
1.3 Comentarios finales
En esta obra veremos una breve introducción a la gramática que emplea el paquete dplyr del tidyverse. Este paquete emplea diferentes funciones (que en el universo tidyverse se conocen como verbos) para trabajar con observaciones (filtrar) (Capítulo 2), transformar variables (Capítulo 3) y fusionar bases de datos (Capítulo 4).
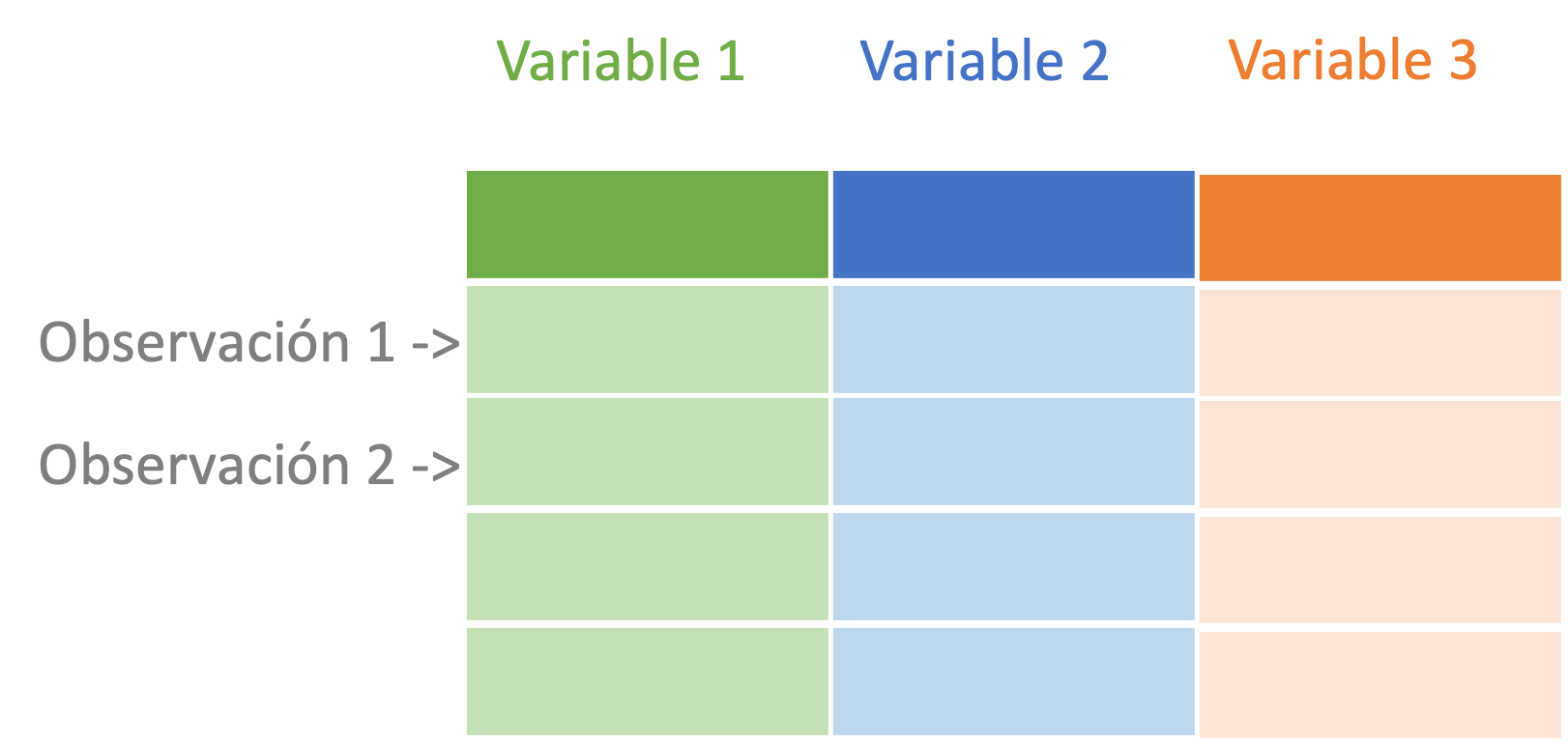
Pero, antes de pasar al siguiente capítulo miremos la representación gráfica de un objeto con datos (ya sea de la clase tibble o data.frame) que emplearemos a lo largo del libro y que es común en el universo tidyverse. En la Figura 1.1 se representa un objeto tibble o data.frame, donde cada columna corresponde a una variable, y cada fila a una observación (individuo).
Figura 1.1: Representación de un objeto con datos de clase tibble o data.frame
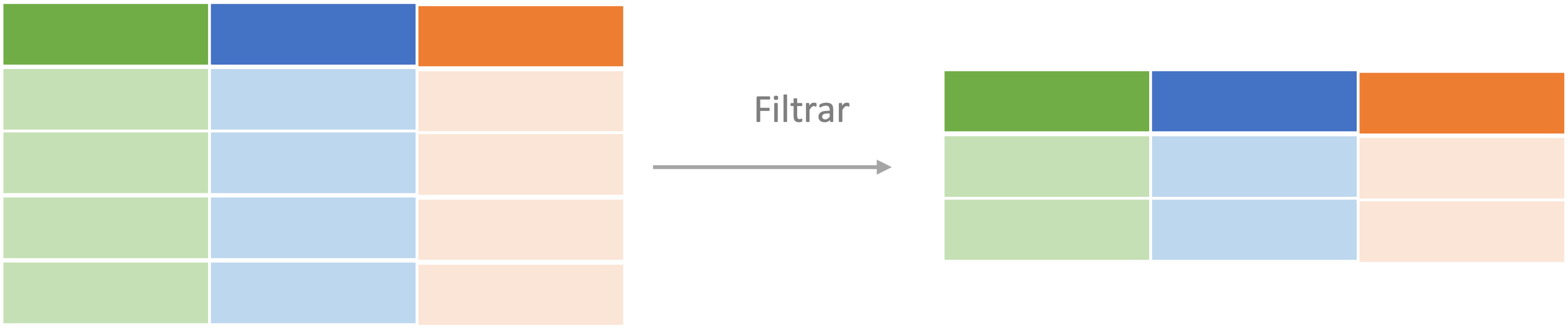
Con este tipo de figura podemos representar qué ocurre cuando filtramos un objeto con datos (ver Figura 1.2). En ese caso estamos seleccionando unas observaciones de la base original.
Figura 1.2: Representación del proceso de filtrado de un objeto de clase tibble o data.frame
En el siguiente capítulo veremos como filtrar objetos con datos de clase data.frame y tibble empleando el paquete dplyr.
Referencias
Algunas de las funciones de las primeras versiones del paquete dplyr presentaban conflicto con las funciones de otros paquetes y de la misma base de R. En las siguientes versiones estos problemas se han solucionado y el nombre de las funciones han sido modificadas para evitar estos inconvenientes. En la actualidad el paquete dplyr es muy estable y tiene muy pocos problemas documentados.↩︎
De hecho, tidyverse (Wickham et al., 2019) es un paquete que a su vez contiene 8 paquetes.↩︎
Nota que tidy significa en español ordenado y verse es la parte final de universe (universo) de ahí que también se emplee la expresión universo Tidyverse.↩︎
Si deseas conocer con mayor detalle el cómo fue diseñado este universo puedes consultar Wickham & Grolemund (2016) o la versión en linea del libro en el siguiente enlace https://r4ds.had.co.nz.↩︎
Si quieres conocer sobre los loops en R, puedes consultar Alonso Cifuentes (2021) .↩︎
RStudio es una interfaz gráfica de usuario que permite trabajar con mayor comodidad en R. Para una discusión de cómo instalar y emplear RStudio puedes consultar Alonso Cifuentes & Ocampo (2022).↩︎